Handbook по дисциплине
«Математические и инструментальные методы поддержки принятия решений»
Программа магистерской подготовки по направлению «Прикладная информатика»
Кафедра Математических методов принятия решений
Харитонов С.В., Дик В.В.
Handbook по дисциплине
«Математические и инструментальные методы поддержки принятия решений»
Программа магистерской подготовки по направлению «Прикладная информатика»
Содержание
Тема 1. Сущность проблемы принятия решения. OLTP-системы и СППР
Вопрос 1. Проблема планирования деятельности фирмы.
Вопрос 2. Однокритериальные и многокритериальные методы выбора плановых решений.
Вопрос 3. Предпосылки появления систем поддержки принятия решений (СППР).
Вопрос 4. OLTP- и OLAP-технологии.
Вопрос 1. Методы решения задач планирования в условиях полной определенности.
Вопрос 2. Понятие и модель данных OLAP.
Вопрос 3. Технические аспекты многомерного хранения данных.
Тема 3. Принятие решений при многих критериях. Технология KDD. ETL-процесс в СППР
Вопрос 1. Принятие решений в условиях неопределенности.
Вопрос 3. ETL –процесс в СППР.
Тема 4. Принятие решений в условиях риска и конфликта. Data miming: кластеризация данных СППР
Вопрос 1. Принятие решений в условиях риска.
Вопрос 2. Решение матричных игр в чистых стратегиях.
Вопрос 3. Алгоритмы кластеризации на службе Data Mining.
Тема 5. Машинное обучение в СППР: деревья решений
Вопрос 1. Дерево решений, как инструмент принятия решений.
Вопрос 2. Деревья решений - общие принципы работы.
Вопрос 3. Дерево решений и типы решаемых задач.
Вопрос 4. Этапы построения деревьев решений.
Тема 6. Принятие решений коллективом экспертов. Машинное обучение в СППР: нейронные сети
Вопрос 1. Метод экспертных оценок.
Вопрос 2. Применение нейронных сетей для задач классификации.
Дисциплина «Математические и инструментальные методы поддержки принятия решений» предназначена для изучения обучающимися по программе магистратуры направления «Прикладная информатика».
Дисциплина формирует систему базовых представлений о содержании, алгоритмах и принципах математических и инструментальных методов поддержки принятия решений, а также развивает основные практические умения в сфере их применения при организации управления.
Цель дисциплины: формирование у студентов теоретических знаний в области разработки и принятия управленческих решений, изучение математического инструментария поддержки принятия решений, а также формирование практических навыков применения программного обеспечения при организации управляющих воздействий.
Задачи дисциплины:
· сформировать представление о процессе принятия решений;
· сформировать представление об условиях и задачах принятия решений;
· освоить методы формализации и алгоритмизации процессов принятия решений;
· развить навыки анализа информации, подготовки и обоснования управленческих решений;
· углубить представление о функциях, свойствах, возможностях системами поддержки принятия решений;
· сформировать навыки использования систем поддержки принятия решений для решения прикладных задач.
В результате изучения дисциплины слушатель должен:
знать:
· многокритериальные методы принятия решений;
· виды информационной и инструментальной поддержки лица, принимающего решения (ЛПР);
· методы группового принятия решений;
· методы исполнения решений на различных этапах цикла принятия решений;
· возможности систем поддержки принятия решений (СППР); критерии выбора инструментов СППР;
· виды информационной и инструментальной поддержки лица, принимающего решения (ЛПР);
· методы группового принятия решений;
· методы исполнения решений на различных этапах цикла принятия решений;
· возможности систем поддержки принятия решений (СППР);
· критерии выбора инструментов СППР; классификацию задач и условий принятия решений;
уметь:
· формулировать требования ЛПР к СППР;
· выбирать инструментарий для каждого этапа принятия решения;
· использовать инструментарий мониторинга исполнения решений;
· управлять рисками при проектировании и внедрении СППР;
· осуществлять выбор СППР, исходя из потребностей и возможностей предприятия и организации;
· формализовать процесс обоснования и принятия решений;
· выбирать инструментарий для каждого этапа принятия решения;
· использовать инструментарий мониторинга исполнения решений;
· управлять рисками при проектировании и внедрении СППР;
владеть:
· навыками формулирования требований к СППР, разработки отдельных их элементов, оценки вариантов последующих закупок ИКТ для внедрения и эксплуатации ИС.
Цель: изучение основных этапов процесса принятия решения, рассмотрение видов информационной и инструментальной поддержки ЛПР, а также сравнительной характеристики OLTP-систем и СППР.
Задачи:
· рассмотреть проблему планирования деятельности фирмы;
· формализовать процесс обоснования и принятия решений;
· рассмотреть постановку однокритериальной и многокритериальной задачи принятия решений;
· сформулировать предпосылки появления СППР;
· рассмотреть OLTP- и OLAP-технологии и структуру СППР.
Вопросы темы:
1. Проблема планирования деятельности фирмы.
2. Однокритериальные и многокритериальные методы выбора плановых решений.
3. Предпосылки появления систем поддержки принятия решений (СППР).
4. OLTP- и OLAP-технологии.
5. Структура СППР.
Проблема планирования деятельности фирмы заключается в определении различных альтернатив действий и выборе оптимальной альтернативы, т. е. такой, которая позволяет получить наилучший результат в достижении поставленной цели. В качестве альтернатив могут выступать новые целевые области (товарные рынки), виды выпускаемой продукции, инвестиции в различные сферы деятельности фирмы и т. д. Как правило, они не могут быть реализованы одновременно. Целенаправленный выбор среди подобных альтернатив представляет собой принятие управленческого решения.
Реализация (осуществление) любой возможной альтернативы ведет к одному или нескольким последствиям (результатам). Ожидаемыми результатами могут быть выручка от реализации товаров, издержки производства, доля удовлетворения спроса, прибыль, затраты на продвижение товара, доля рынка и др.
На значение результата обычно оказывают влияние разнообразные факторы, которые не подвержены или почти не подвержены влиянию со стороны ЛПР. Возможное положение дел, не зависящее напрямую от воздействия руководства фирмы, называется ситуацией внешней или окружающей среды. Состояние внешней среды складывается, как правило, в результате имеющейся политической обстановки (стабильная, нестабильная), поведения конкурирующих фирм (реактивное. нереактивное поведение), социально-экономических условий (платежеспособного спроса, правительственного регулирования экономики и т. д.). Состояния внешней среды в теории принятия решений называют обычно гипотезами.
Каждой реализуемой альтернативе ![]() соответствуют некоторые состояния окружающей
среды
соответствуют некоторые состояния окружающей
среды ![]() . Ожидаемый результат
. Ожидаемый результат ![]() при выборе альтернативы
при выборе альтернативы ![]() и принятии гипотезы
и принятии гипотезы ![]() получается,
если применить функцию предпочтения, или, как чаще всего говорят, функцию
полезности f, т. е.:
получается,
если применить функцию предпочтения, или, как чаще всего говорят, функцию
полезности f, т. е.:
![]()
Предполагается, что ЛПР известны получаемые благодаря
ей закономерности. Значения функции f наглядно
представляются в виде так называемой матрицы ожидаемых результатов. При этом
могут задаваться вероятности появления ситуаций внешней среды (гипотез) ![]() , которые при принятии решений считаются
рисками. Таким образом, проблема планирования может быть сведена к получению
необходимой информации, размещению ее в виде таблиц, например в виде табл. 1.
представляющих собой по существу основные модели задач теории принятия решений,
и выбору оптимальной альтернативы.
, которые при принятии решений считаются
рисками. Таким образом, проблема планирования может быть сведена к получению
необходимой информации, размещению ее в виде таблиц, например в виде табл. 1.
представляющих собой по существу основные модели задач теории принятия решений,
и выбору оптимальной альтернативы.
Таблица 1.
Матрица описания задач принятия решений
|
Альтернативы, Ai |
Состояния внешней среды (гипотезы) |
|||
|
Z1 |
Z2 |
… |
Zn |
|
|
А1 |
e11 |
e12 |
… |
e1n |
|
А2 |
e21 |
e22 |
… |
e2n |
|
… |
… |
… |
… |
… |
|
Am |
em1 |
em2 |
… |
emn |
|
Вероятности гипотез, pj |
p1 |
p2 |
… |
pn |
Альтернатива ![]() ,
считается в общем случае доминирующей, если не существует никакой другой
альтернативы
,
считается в общем случае доминирующей, если не существует никакой другой
альтернативы ![]() со значением
со значением
![]()
и ![]() (для наименьшей
величины, соответствующей j).
(для наименьшей
величины, соответствующей j).
Здесь ![]() означает ожидаемый
результат от применения альтернативы
означает ожидаемый
результат от применения альтернативы ![]() при наступлении состояния внешней среды
при наступлении состояния внешней среды ![]() . Если в матрице решений имеется
доминирующая альтернатива, то она и выбирается в качестве планового решения.
Однако, как правило, доминирующие альтернативы отсутствуют и, кроме того,
решение приходится принимать в условиях риска и неопределенности. Здесь нужны
специальные принципы принятия решений, или решающие правила, или критерии
принятия решений, которые используются иногда как синонимы.
. Если в матрице решений имеется
доминирующая альтернатива, то она и выбирается в качестве планового решения.
Однако, как правило, доминирующие альтернативы отсутствуют и, кроме того,
решение приходится принимать в условиях риска и неопределенности. Здесь нужны
специальные принципы принятия решений, или решающие правила, или критерии
принятия решений, которые используются иногда как синонимы.
Итак, мы имеем задачу принятия решений (ПР). Все задачи ПР группируются в зависимости от набора классификационных признаков. Существует несколько подходов к классификации задач принятия решений (ЗПР). Однако большинство из них опирается на следующие признаки: характер субъекта (ЛПР), содержание ЗПР, количество целей, влияние времени, значимость решений. Каждый из признаков включает несколько параметров классификации ЗПР.
Особый интерес представляет признак «характер субъекта ПР», который описывает степень информированности ЛПР о проблемной ситуации и указывает конкретный тип ЛПР. В следующих темах рассмотрим методы принятия решений:
а) в условиях полной определенности, когда известны все составляющие и характеристики проблемы планирования;
б) в условиях вероятностной определенности (риска);
в) в условиях неопределенности.
На первом этапе планирования происходит упорядочение имеющейся (полученной) информации, которая размещается в соответствующих таблицах. Следует заметить, что для каждого типа задач принятия решений создается своя система подготовки информации.
Рассмотрим как различают однокритериальные и многокритериальные методы выбора плановых решений.
1. Однокритериальные методы выбора. Считается известным:
·
исходное множество альтернатив ![]() ;
;
·
оценки результатов выбираемых
альтернатив ![]() ;
;
·
критерий выбора ![]() или
или ![]() .
.
Следовательно, выбор характеризуется однозначной
связью между принятым решением Ai и его
результатом ![]() . В процессе решения задачи определяется
альтернатива A*, для
которой
. В процессе решения задачи определяется
альтернатива A*, для
которой ![]() или
или ![]() .
.
2. Многокритериальные методы выбора. В достаточно большом количестве практических случаев принятия решений при планировании действий приходится учитывать не один, а несколько критериев. Не умаляя общности, можно считать, что все критерии стремятся к максимуму, так как если некоторые критерии минимизируются, то путем умножения их на (-1) они будут стремиться к максимуму, причем решение при этом не изменяется. Матрица исходных данных принятия решений имеет вид (табл. 2).
Если в табл. 2 находится доминирующая альтернатива, то проблемы выбора как таковой не существует, а именно данная альтернатива и принимается в качестве планового решения.
Таблица 2.
Матрица исходных данных для многокритериальных методов выбора
|
Альтернативы, Ai |
Критерии (цели) |
|||
|
Z1 |
Z2 |
… |
Zn |
|
|
А1 |
e11 |
e12 |
… |
e1n |
|
А2 |
e21 |
e22 |
… |
e2n |
|
… |
… |
… |
… |
… |
|
Am |
em1 |
em2 |
… |
emn |
Однако, как было отмечено ранее, доминирующие стратегии на практике встречаются довольно редко. Поэтому приходится применять методы многокритериального выбора, причем решение должно быть наилучшим в определенном смысле. Итак, выделение существенных для модели рассматриваемой экономической системы показателей качества альтернатив выбора, соответствующих поставленным целям, приводит к задаче векторной оптимизации, которая заключается в нахождении максимума вектор-функции:
![]() ,
,
где D – область допустимых решений модели.
В случае многокритериальной оптимизации возникают три
проблемы. Первая проблема связана с выбором принципа оптимальности. В
математическом отношении эта проблема эквивалентна задаче упорядочения
векторных множеств, а выбор принципа оптимальности - выбору отношений порядка.
Вторая проблема связана с нормализацией векторного критерия F(х). Дело в том, что частные критерии имеют различные
единицы измерения, поэтому их необходимо привести к единому масштабу измерения,
т. е. нормализовать(обычно приводят к безразличным величинам). Третья проблема
связана с учетом приоритета (степени важности) частных критериев. Часто для
учета приоритета вводится вектор распределения важности или значимости
критериев ![]() .
.
В задаче многокритериального выбора решение почти всегда ищется в области компромиссов или в области решений, оптимальных по Парето, Известен целый ряд методов решения многокритериальных задач, которые можно разбить на четыре группы:
1. Сведение многих критериев к одному путем введения весовых коэффициентов для каждого критерия (более важный критерий получает больший вес).
2. Минимизация максимальных отклонений от наилучших значений по всем критериям.
3. Оптимизация одного критерия (почему-либо признанного наиболее важным), а остальные критерии выступают в роли дополнительных ограничений.
4. Упорядочение (ранжирование) множества критериев и последовательная оптимизация по каждому из них.
В
рассматриваемой постановке множество допустимых планов есть совокупность
альтернатив ![]() , а значения критериев равны:
, а значения критериев равны: ![]() .
.
Ситуацию с корпоративной информацией, складывающуюся в настоящее время на большинстве предприятий, можно сравнить с сокровищем, которое лежит под ногами, но которое никто не может извлечь. По данным Gartner Group, большая часть корпоративной информации – 90 % - лежит невостребованной и никак не анализируется. Между тем многие из проблем, которые возникают в текущей деятельности предприятия и которые требуют оперативного решения, не являются для него абсолютно новыми. Как правило, предприятие уже когда-то сталкивалось с похожей ситуацией, и в этой связи были приняты определенные управленческие решения, которые привели к соответствующим результатам. Этот опыт (позитивный или негативный) может оказаться очень ценным при решении проблем, стоящих перед предприятием в настоящий момент.
Подобное положение с очевидностью говорит о том, что необходимы технологии, которые бы позволили анализировать накопленную информацию и предоставили бы возможность оперативно принимать максимально взвешенные решения.
Руководители предприятий сегодня осторожно относятся к проектам внедрения информационных систем, все больше задумываясь над тем, куда они вкладывают деньги и какой результат получат от этих вложений. Многие компании имеют негативный опыт внедрения подобных систем, а инвесторы не получают от реализации таких проектов ожидаемого эффекта. Одной из причин, как представляется, оказывается размытость цели построения информационной системы предприятия.
Цель построения каждой информационной системы должно быть обеспечение максимально прозрачного и эффективного управления бизнесом, то есть предоставление управляющему звену возможности проводить текущую оценку состояния бизнеса, формулировать и описывать бизнес-цели, определять методы и пути достижения поставленных задач.
Для этого, с одной стороны, система должна снабжаться максимально полной, актуальной, качественной и согласованной информацией, а с другой - обеспечивать максимально эффективный, быстрый и многоаспектный анализ данных.
Анализировать всю накопленную корпоративную информацию и учитывать результаты такого анализа в процессе принятия бизнес-решений позволяют так называемые Системы Поддержки Принятия Решений - СППР (Decision Support Systems, DSS). А применяемые технологии именуются OLTP – On-Line Transaction Processing.
Если попытаться коротко сформулировать роль таких технологий в системе управления предприятием, то СППР – это инструмент менеджеров предприятия, предназначенный для решения следующих ключевых задач:
· оценки текущего состояния бизнеса предприятия;
· формулирования и описания бизнес-целей;
· определения методов и способов достижения поставленных бизнес-целей.
Эти технологии уже много лет применяются на Западе и становятся все более актуальными в России[1].
Задачи OLTP-системы – это быстрый сбор и наиболее оптимальное размещение информации в базе данных, а также обеспечение ее полноты, актуальности и согласованности. Однако такие системы не предназначены для максимально эффективного, быстрого и многоаспектного анализа.
Разумеется, по собранным данным можно строить отчеты, но это требует от бизнес-аналитика или постоянного взаимодействия с IT-специалистом, или специальной подготовки в области программирования и вычислительной техники.
Мировая индустрия давно знакома с этой проблемой, и вот уже почти 30 лет существуют OLAP-технологии, которые и предназначены именно для того, чтобы бизнес-аналитики имели возможность оперировать с накопленными данными, непосредственно участвовать в их анализе. Подобные аналитические системы противоположны OLTP-системам в том плане, что они устраняют информационную избыточность («сворачивают» информацию). Вместе с тем очевидно, что именно избыточность первичной информации определяет эффективность анализа. СППР, объединяя эти технологии, дают возможность решать целый ряд задач:
· Аналитические задачи: вычисление заданных показателей и статистических характеристик бизнес-процессов на основе ретроспективной информации, находящейся в хранилищах данных.
· Визуализацию данных: представление всей имеющейся информации в удобном для пользователя графическом и табличном виде.
· Получение новых знаний: определение взаимосвязи и взаимозависимости бизнес-процессов на основе существующей информации (проверка статистических гипотез, кластеризация, нахождение ассоциаций и временных шаблонов).
· Имитационные задачи: математическое моделирование поведения сложных систем в течение произвольного периода времени. Иными словами, это задачи, связанные с необходимостью ответить на вопрос: «Что будет, если...?».
· Синтез управления: определение допустимых управляющих воздействий, обеспечивающих достижение заданной цели.
· Оптимизационные задачи: интеграция имитационных, управленческих, оптимизационных и статистических методов моделирования и прогнозирования.
Менеджеры предприятия, использующие инструментальные средства OLAP-технологии, даже без специальной подготовки могут самостоятельно и оперативно получать всю необходимую для исследования закономерностей бизнеса информацию, причем в самых различных комбинациях и срезах бизнес-анализа. Бизнес-аналитик имеет возможность видеть перед собой список измерений и показателей бизнес-системы. При столь простом интерфейсе аналитик может строить любые отчеты, перестраивать измерения (скажем, делать кросс-таблицы – накладывать одно измерение на другое). Кроме этого, он получает возможность создавать свои функции на базе существующих показателей, проводить анализ «что, если» – получать результат, задавая зависимости каких-либо показателей бизнес-функций или бизнес-функцию от показателей. При этом максимальный отклик любого отчета не превышает 5 секунд[2].
Система строится на основе четырех ключевых компонентов:
· Информационных Хранилищ Данных.
· ETL (Extracting Transformating and Loading) – средств и методов извлечения, обработки и загрузки данных.
· OLAP - многомерной базы данных и средств анализа.
· Data Mining - средств извлечения данных.
При этом Технология Информационных Хранилищ Данных обеспечивает:
· быструю обработку поступающих запросов;
· интеграцию распределенных данных;
· интеграцию внутренних и внешних данных;
· устранение ненужной информации;
· агрегирование (вычисление сумм, средних показателей);
· преобразование типов данных, структур хранения;
· приведение данных к одному моменту времени.
Хранилище Данных строится на основе OLTP-базы данных, а также различных разнородных источников информации. Таким образом, система сбора информации представляет собой централизованный импорт данных из существующих учетных систем.
Когда данные импортируются в Хранилище Данных, они подвергаются некоторой первичной обработке, обеспечивающей эффективность последующего анализа: производится очистка данных, структурирование по времени, агрегирование, фильтрация и ряд других операций.
Все это необходимо для того, чтобы бизнес-аналитик не только оперировал данными оперативного учета (так называемая оперативная отчетность), но имел возможность производить полнофункциональный анализ, строить прогнозы и при этом работать с системой в тех бизнес-терминах, которые он использует в повседневной работе.
Еще одна задача Хранилища Данных – интеграционная, то есть предоставление возможности объединить разнородные источники информации в единое информационное пространство, с которым удобнее работать и которым легче управлять. Во многих компаниях установлены разнородные системы, отвечающие (причем очень эффективно) за выполнение тех или иных задач. Хранилище данных обеспечивает интеграцию этих источников информации и одновременно «разгружает» учетные системы, освобождая их от построения отчетов.
Кроме того, на предприятиях существует большой объем нерегламентированной информации, которую также необходимо подвергать анализу. Это информация, которая приходит от руководящих и регулирующих органов и не поступает в базу данных предприятия, а также информация, получаемая из Интернета, и любые другие существенные для бизнеса данные. Хранилище позволяет собирать эту информацию и производить её дальнейший анализ средствами OLAP.
OLAP – это технология анализа данных, включающая возможности аналитической обработки информации из разных источников (файлов, баз данных и программных приложений); определения скрытых зависимостей между данными и построения объективной картины информации по различным срезам; представления необходимых для прогнозирования данных в виде, простом и понятном для всех, кто занимается управлением.
Data Mining – технология извлечения данных, позволяющая осуществлять поиск общих закономерностей в больших объемах данных. С помощью технологии Data Mining решаются следующие задачи:
· применение правила «если..., то...» с использованием коэффициентов уверенности;
· определение характеристик ненадежного клиента;
· выявление перспективных клиентов;
· сохранение существующих клиентов;
· отбор кандидатов для рассылки новых предложений;
· определение стратегии продаж;
· составление и оценка системы скидок.
Необходимо отметить, что OLAP-технологии в целом очень гармонично интегрируются с другими технологиями построения информационных систем. Например, одновременно с внедрением CRM-системы можно установить и OLAP-систему как средство обработки информации, которую CRM-система позволяет накапливать. Более того, сейчас и в состав многих ERP-систем входят OLAP-решения. Например, Oracle Application содержит такие продукты, как Oracle Financial Analyzer, Oracle Sales Analyzer[3].
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008.
2. Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных странах: Учебник. – М.: Логос, 2008. – 392 с.
3. Смирнов Э.А. Разработка управленческих решений. – М.: ИНФРА-М, 2008. – 272 с.
4. Трахтенгерц Э.А. Компьютерная поддержка принятия решений: Научно-практическое издание. – М.: СИНТЕГ, 1998. – 376 с.
5. Фатхутдинов Р.А. Разработка управленческого решения: Учеб. пособ. – М.: Бизнес-школа, Интел-Синтез, 2007. – 272 с.
Цель: изучение математических методов принятия решений в условиях неопределенности, а также рассмотрение модели хранения данных в СППР и аналитических платформ.
Задачи:
· Сформулировать методы принятия решений в условиях полной определенности.
· Рассмотреть понятия и модель данных OLAP.
· Изучить технические аспекты многомерного хранения данных.
Вопросы темы:
1. Методы решения задач планирования в условиях полной определенности.
2. Понятие и модель данных OLAP.
3. Технические аспекты многомерного хранения данных.
Покажем применение некоторых методов многокритериальной оптимизации к решению задач планирования в системе управления фирмой.
Метод равномерной оптимизации:
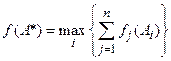 (1)
(1)
Он применяется, если глобальное качество альтернативы представляет собой сумму локальных (частных) качеств и, кроме того, все критерии имеют одну и ту же единицу измерения, например денежное выражение либо безразмерные величины. Главный недостаток метода - это возможность компенсации малых значений некоторых критериев достаточно большими значениями других.
Метод справедливого компромисса:
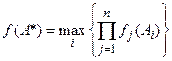 (2)
(2)
Он применяется, во-первых, потому что существуют разнообразные схемы, приводящие к такому методу, во-вторых, потому что имеется тесная связь с решением в некооперативных играх.
Метод свертывания критериев:
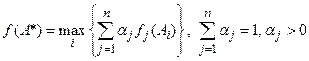 (3)
(3)
Здесь каждому из критериев приписываются весовые коэффициенты а, определяющие предпочтения ЛПР.
Метод главного критерия:
![]() (4)
(4)
Здесь ![]() - главный (наиболее
важный из всех для ЛПР) критерий,
- главный (наиболее
важный из всех для ЛПР) критерий, ![]() - нижняя граница j-го
критерия, устанавливаемая ЛПР.
- нижняя граница j-го
критерия, устанавливаемая ЛПР.
Метод идеальной точки. Ищется план, удовлетворяющий условию равномерного сжатия:
![]() (5)
(5)
Метод последовательных уступок (или пороговых значений):
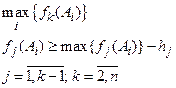
где ![]() - уступка по критерию
- уступка по критерию ![]() , т. е. величина, на которую ЛПР согласен
уменьшить значение данного критерия по сравнению с его максимальным значением.
, т. е. величина, на которую ЛПР согласен
уменьшить значение данного критерия по сравнению с его максимальным значением.
Метод группировки критериев. Суть метода заключается в том, что множество критериев, значения которых предварительно вычислены на некотором оптимальном по Парето плане x°, разбивается на три группы. Первая группа включает критерии, значения которых могут быть уменьшены по сравнению со значениями, вычисленными на плане x° Вторая группа состоит из критериев, значения которых желательно увеличить. Третья группа включает критерии, значения которых не хотелось бы уменьшать по сравнению с достигнутыми на плане x°. Далее отыскивается план уже в новой системе ограничений, который позволяет максимально увеличить значение критерия второй группы.
Так как критерии могут иметь различные масштабы и шкалы измерения, то прежде, чем приступить к решению многокритериальной задачи, их необходимо привести к одной единице измерения (обычно к безразмерному виду). Этот процесс называется нормализацией. Существуют различные методы нормализации, Предлагается следующий способ получения безразмерной формы критериев:
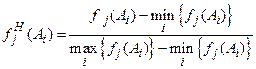 (6)
(6)
где ![]() .
.
Рассмотрим следующую многокритериальную задачу
планирования. Пусть фирма имеет возможность реализовывать свои товары на 4-х
различных рынках (альтернативы ![]() ). При этом ставятся
одновременно следующие цели: минимизация затрат на рекламу, завоевание
максимальной доли рынка и максимальный объем продаж в течение планируемого
периода. Исходные данные приведены в табл. 3.
). При этом ставятся
одновременно следующие цели: минимизация затрат на рекламу, завоевание
максимальной доли рынка и максимальный объем продаж в течение планируемого
периода. Исходные данные приведены в табл. 3.
Таблица 3.
Исходные данные многокритериальной задачи (пример)
|
Альтернативы, рынки |
Цели (критерии) |
||
|
затраты на рекламу, тыс.ден.ед., f1 |
доля рынка, %, f2 |
объем продаж, тыс.ден.ед., f3 |
|
|
А1 |
7 |
45 |
90 |
|
А2 |
5 |
40 |
85 |
|
А3 |
9 |
50 |
80 |
|
А4 |
6 |
45 |
83 |
Значения критериев даны в различных единицах измерения, поэтому согласно формуле (6) приведем их к безразмерному виду:
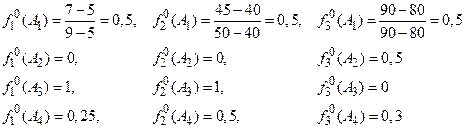
Так как критерий ![]() ,
минимизируется, то для того, чтобы все критерии стремились к максимуму, умножим
безразмерные величины критерия
,
минимизируется, то для того, чтобы все критерии стремились к максимуму, умножим
безразмерные величины критерия ![]() , на (-1) и сформируем
табл. 4. Решим задачу несколькими методами.
, на (-1) и сформируем
табл. 4. Решим задачу несколькими методами.
Таблица 4.
Преобразованные исходные данные (пример)
|
Альтернативы |
Цели (критерии) |
||
|
f1 |
f2 |
f3 |
|
|
А1 |
-0,5 |
0,5 |
1 |
|
А2 |
0 |
0 |
0,5 |
|
А3 |
-1 |
1 |
0 |
|
А4 |
-0,25 |
0,5 |
0,3 |
Метод равномерной оптимальности. В соответствии с (1) имеем:
![]()
Таблица 5.
|
Альтернативы |
Цели (критерии) |
Критерий |
||
|
f1 |
f2 |
f3 |
||
|
А1 |
-0,5 |
0,5 |
1 |
-0,5+0,5+1=1 |
|
А2 |
0 |
0 |
0,5 |
0,5 |
|
А3 |
-1 |
1 |
0 |
0 |
|
А4 |
-0,25 |
0,5 |
0,3 |
-0,25+0,5+0,3=0,55 |
Следовательно, согласно принципу равномерной
оптимальности предприятию выгоднее работать на рынке ![]() .
.
Метод справедливого компромисса. Чтобы воспользоваться данным
методом, избавимся от отрицательности критерия ![]() , добавив
константу, например 1. Тогда значения первого критерия будут равны:
, добавив
константу, например 1. Тогда значения первого критерия будут равны:
![]()
На основании (2) имеем:
![]()
Таблица 6.
|
Альтернативы |
Цели (критерии) |
Критерий |
||
|
f1 |
f2 |
f3 |
||
|
А1 |
-0,5+1=0,5 |
0,5 |
1 |
0,5*0,5*1=0,25 |
|
А2 |
0+1=1 |
0 |
0,5 |
1*0*0,5=0 |
|
А3 |
-1+1=0 |
1 |
0 |
0 |
|
А4 |
-0,25+1=0,75 |
0,5 |
0,3 |
0,75*0,5*0,3=0,1125 |
Результат получился аналогичный предыдущему, а именно выгоднее работать на рынке А1.
Метод свертывания критериев. Сначала положим следующие значения весовых
коэффициентов: ![]() . Тогда функции свертки в соответствии
с (6.3) будут равны:
. Тогда функции свертки в соответствии
с (6.3) будут равны:
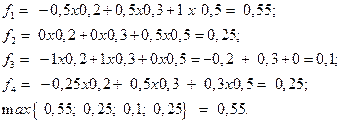
Таблица 7.
|
Альтернативы |
Цели (критерии) |
Критерий
|
||
|
f1 |
f2 |
f3 |
||
|
А1 |
-0,5 |
0,5 |
1 |
-0,5*0,2+0,5*0,3+1*0,5= 0,55 |
|
А2 |
0 |
0 |
0,5 |
0*0,2+0*0,3+0,5*0,5=0,25 |
|
А3 |
-1 |
1 |
0 |
-1*0,2+1*0,3+0*0,5=0,1 |
|
А4 |
-0,25 |
0,5 |
0,3 |
-0,25*0,2+0,5*0,3+ 0,3*0,5= 0,25 |
При таком значении коэффициентов значимости критериев выгоднее работать на рынке A1.
Если доложить ![]() , то
получим:
, то
получим:
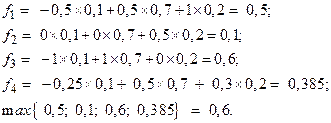
Таблица 8.
|
Альтернативы |
Цели (критерии) |
Критерий
|
||
|
f1 |
f2 |
f3 |
||
|
А1 |
-0,5 |
0,5 |
1 |
-0,5*0,1+0,5*0,7+1*0,2= 0,5 |
|
А2 |
0 |
0 |
0,5 |
0*0,1+0*0,7+0,5*0,2=0,1 |
|
А3 |
-1 |
1 |
0 |
-1*0,1+1*0,7+0*0,2=0,6 |
|
А4 |
-0,25 |
0,5 |
0,3 |
-0,25*0,1+0,5*0,7+ 0,3*0,2= 0,385 |
Таким образом, если приоритет отдается доле рынка (![]() ), то фирме имеет смысл работать на рынке А3.
), то фирме имеет смысл работать на рынке А3.
Если же фирма находится в затруднительном положении с
точки зрения средств, выделяемых на рекламу, другими словами, для нее в данный
момент самым важным является минимизация затрат на рекламу, то коэффициенты
значимости могут быть, например, выбраны такие: ![]() ;
; ![]() .
.
Следовательно, в такой ситуации лучше всего работать на рынке А2.
Если задать весовые коэффициенты ![]() , то
, то
![]() .
.
При таких значениях весовых коэффициентов выгоднее
работать на рынке ![]() .
.
Приведем два последних варианта решений в следующей таблице:
Таблица 9.
|
Альтернативы |
Цели (критерии) |
Критерий |
|
|||
|
|
|
|||||
|
f1 |
f2 |
f3 |
|
|||
|
А1 |
-0,5 |
0,5 |
1 |
-0,25 |
0,35 |
|
|
А2 |
0 |
0 |
0,5 |
0,05 |
0,15 |
|
|
А3 |
-1 |
1 |
0 |
-0,7 |
0,1 |
|
|
А4 |
-0,25 |
0,5 |
0,3 |
-0,12 |
0,215 |
|
Метод главного критерия. Пусть главный критерий ![]() -
затраты на рекламу, а остальные критерии выступают в роли ограничений, причем
доля рынка должна быть не меньше 45%, а объем продаж не меньше 85 тыс. ден. ед.
Тогда в соответствии с (6.4) минимальное значение главного критерия
-
затраты на рекламу, а остальные критерии выступают в роли ограничений, причем
доля рынка должна быть не меньше 45%, а объем продаж не меньше 85 тыс. ден. ед.
Тогда в соответствии с (6.4) минимальное значение главного критерия ![]() равно 5 тыс. ден. ед. и соответствует альтернативе
А2 однако с учетом ограничения на долю рынка следует выбрать
альтернативу
равно 5 тыс. ден. ед. и соответствует альтернативе
А2 однако с учетом ограничения на долю рынка следует выбрать
альтернативу ![]() , но так как еще требуется, чтобы объем
продаж был не меньше 85 тыс. ден. ед., то наилучшей альтернативой в этом случае
будет рынок
, но так как еще требуется, чтобы объем
продаж был не меньше 85 тыс. ден. ед., то наилучшей альтернативой в этом случае
будет рынок ![]() .
.
f1-главный критерий, ![]() ,
, ![]()
Таблица 10.
|
Альтернативы, рынки |
Цели (критерии) |
||
|
затраты на рекламу, тыс.ден.ед., f1 |
доля рынка, %, f2 |
объем продаж, тыс.ден.ед., f3 |
|
|
А1 |
7 |
45 |
90 |
|
А2 |
5=min |
40 |
85 |
|
А3 |
9 |
50 |
80 |
|
А4 |
6 |
45 |
83 |
Метод идеальной точки (критерий равномерного сжатия (6.5) соответствует принципу
Сэвиджа). Определим сначала максимальные значения критериев. А именно ![]() Матрица отклонений значений критериев от
наилучших значений имеет вид:
Матрица отклонений значений критериев от
наилучших значений имеет вид:
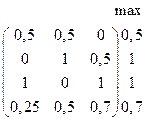
Максимальные отклонения по каждой из 4-х альтернатив имеют следующие значения: 0,5; 1; 1; 0,7. Выберем минимальное из этих отклонений:
![]() .
.
Таблица 11.
|
|
Цели (критерии) |
Отклонения от max |
Max отклонения |
||||
|
f1 |
f2 |
f3 |
|
|
|
||
|
А1 |
-0,5 |
0,5 |
1= |
0-(-0,5)=0,5 |
1-0,5=0,5 |
1-1=0 |
0,5=min |
|
А2 |
0= |
0 |
0,5 |
0 |
1-0=1 |
1-0,5=0,5 |
1 |
|
А3 |
-1 |
1= |
0 |
0-(-1)=1 |
1-1=0 |
1-0=1 |
1 |
|
А4 |
-0,25 |
0,5 |
0,3 |
0-(-0,25)=0,25 |
1-0,5=0,5 |
1-0,3=0,7 |
0,7 |
Минимальное значение 0,5 соответствует альтернативе ![]() следовательно, используя данный метод,
получим решение, которое рекомендует фирме планировать работу на рынке
следовательно, используя данный метод,
получим решение, которое рекомендует фирме планировать работу на рынке ![]() .
.
OLAP (Online Analytical Processing) - технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений.
Основное назначение OLAP-систем - поддержка аналитической деятельности, произвольных запросов пользователей - аналитиков. Цель OLAP-анализа - проверка возникающих гипотез.
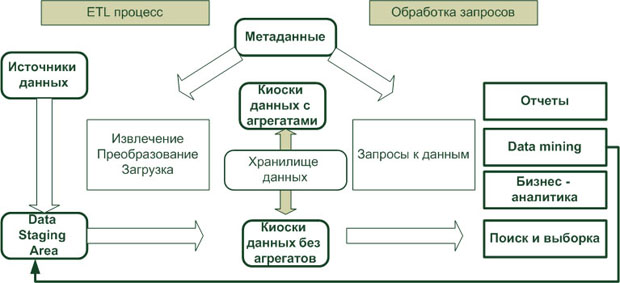
Все данные в ХД делятся на три категории (рисунок 1):
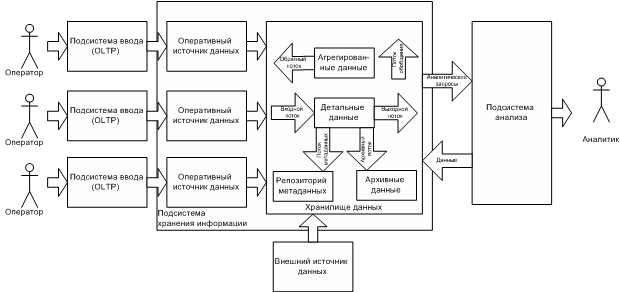
Рис. 1. Архитектура ХД
Детальные данные - данные, переносимые непосредственно из OLTP-подсистем. Соответствуют элементарным событиям, фиксируемым в OLTP-системах. Подразделяются на:
· измерения - наборы данных, необходимые для описания событий (товар, продавец, покупатель, магазин, … );
· факты - данные, отражающие сущность события (количество проданного товара, сумма продаж, …);
· агрегированные (обобщенные) данные - данные, получаемые на основании детальных, путем суммирования по определенным измерениям;
· метаданные - данные о данных, содержащихся в ХД.
Могут описывать:
· объекты предметной области, информация о которых содержится в ХД;
· категории пользователей, использующих данные в ХД;
· места и способы хранения данных;
· действия, выполняемые над данными;
· время выполнения различных действий над данными;
· причины выполнения различных действий над данными.
Информационные потоки в ХД.
Данные в ХД образуют следующие информационные потоки:
· входной поток - образуется данными, копируемыми из OLTP-систем в ХД; данные при этом часто очищаются и обогащаются путем добавления новых атрибутов;
· поток обобщения - образуется агрегированием детальных данных и их сохранением в ХД;
· архивный поток - образуется перемещением детальных данных, количество обращений к которым снизилось;
· поток метаданных - образуется потоком информации о данных в репозиторий данных;
· выходной поток - образуется данными, извлекаемыми пользователями;
· обратный поток - образуется очищенными данными, записываемыми обратно в OLTP-системы.
Структура OLAP-куба.
В процессе анализа данных часто возникает необходимость построения зависимостей между различными параметрами, число которых может быть значительным.
Под измерением будем понимать последовательность значений одного из анализируемых параметров. Например, для параметра «время» это - последовательность дней, месяцев, кварталов, лет.
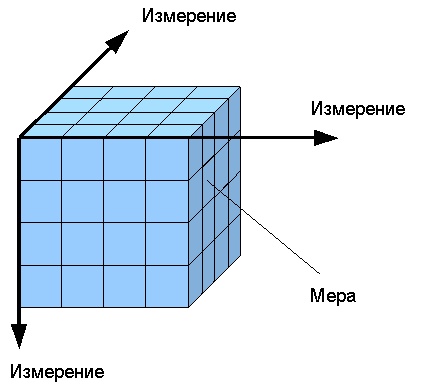
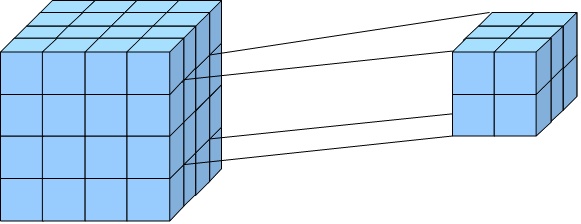
Возможность анализа зависимостей между различными параметрами предполагает возможность представления данных в виде многомерной модели - гиперкуба (рисунок 2), или OLAP-куба.
Рис. 2. Гиперкуб
Оси куба представляют собой измерения, по которым откладывают параметры, относящиеся к анализируемой предметной области, например, названия товаров и названия месяцев года.
На пересечении осей измерений располагаются данные, количественно характеризующие анализируемые факты - меры, например, объемы продаж, выраженные в единицах продукции.
В простейшем случае двумерного куба получается таблица, показывающая значения уровней продаж по товарам и месяцам.
Дальнейшее усложнение модели данных возможно по нескольким направлениям: увеличение числа измерений данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным; усложнение содержимого ячейки например, нас может интересовать не только уровень продаж, но и чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений; введение иерархии в пределах одного измерения общее понятие «время» связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т.д.
Операции, выполняемые над гиперкубом.
Над гиперкубом могут выполняться следующие операции:
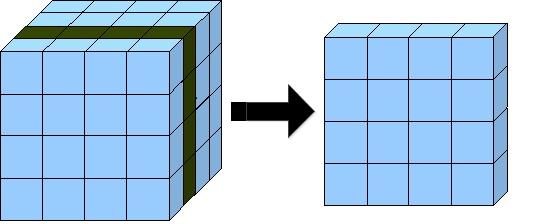
Срез (рисунок 3) - формируется подмножество многомерного массива данных, соответствующее единственному значению одного или нескольких элементов измерений, не входящих в это подмножество.
Рис. 3. Срез
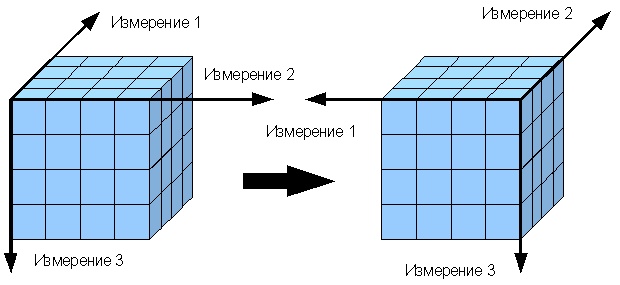
Вращение (рисунок 4) - изменение расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы. Кроме того, вращением куба данных является перемещение внетабличных измерений на место измерений, представленных на отображаемой странице, и наоборот.
Рис. 4. Вращение
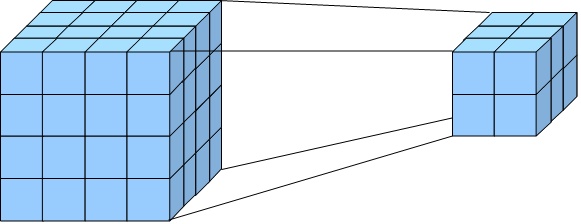
Консолидация (рисунок 5) и детализация (рисунок 6) - операции, которые определяют переход вверх по направлению от детального представления данных к агрегированному и наоборот, соответственно. Направление детализации (обобщения) может быть задано как по иерархии отдельных измерений, так и согласно прочим отношениям, установленным в рамках измерений или между измерениями.
Рис. 5. Консолидация
Рис. 6. Детализация
Например, если при анализе данных о продажах в Северной Америке выполнить операцию детализации для измерения «Регион», то будут отображены такие элементы, как «Канада», «Восточные штаты США» и «Западные штаты США». В результате дальнейшей детализации элемента «Канада» будут отображены элементы «Торонто», «Ванкувер» и т.д.
Таблица фактов - является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся:
· факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата);
· факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка;
· факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки);
· факты, связанные с событиями или состоянием объекта (Event or state facts). Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» - ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно - лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (то есть соответствующие членам нижних уровней иерархии соответствующих измерений). В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран - последние все равно будут вычислены OLAP-средством.
В таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
Таблицы измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов.
Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее.
Полномасштабная OLAP-система должна выполнять сложные и разнообразные функции, включающие сбор данных из различных источников, их согласование, преобразование и загрузку в хранилище, хранение аналитической информации, регламентную отчетность, поддержку произвольных запросов, многомерный анализ и др.
В настоящее время существуют фактические стандарты построения OLAP-систем, основанных на концепции ХД. Эти стандарты опираются на современные исследования и общемировую практику создания хранилищ данных и аналитических систем.
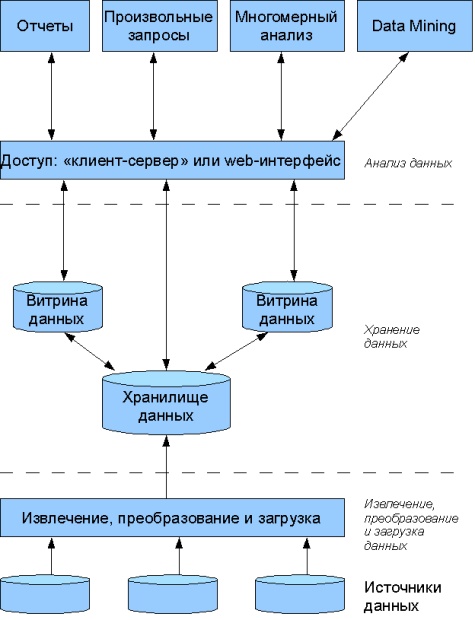
В общем виде архитектура корпоративной OLAP-системы описывается схемой с тремя выделенными слоями (рисунок 7):
· извлечение, преобразование и загрузка данных;
· хранение данных;
· анализ данных.
Рис. 7. Архитектура корпоративной OLAP-системы
Данные поступают из различных внутренних OLTP-систем, от подчиненных структур, от внешних организаций в соответствии с установленным регламентом, формами и макетами отчетности. Вся эта информация проверяется, согласуется, преобразуется и помещается в хранилище и витрины данных. После этого пользователи с помощью специализированных инструментальных средств получают необходимую им информацию для построения различных табличных и графических представлений, прогнозирования, моделирования и выполнения других аналитических задач.
Слой извлечения, преобразования и загрузки данных.
С организационной точки зрения, данный слой включает подразделения и структуры организации всех уровней, поддерживающие базы данных оперативного доступа. Он представляет собой низовой уровень генерации информации, уровень внутренних и внешних информационных источников, вырабатывающих «сырую» информацию. Эта информация является рабочей для повседневной деятельности различных подразделений, которые ее вырабатывают и используют.
С системно-технической точки зрения данный слой представлен ЛВС всех подразделений всех уровней, к которым подключены специализированные технические комплексы, хранящие информацию, чаще всего реализованные в виде реляционных СУБД.
Из источников данных информация перемещается на основе некоторого регламента в централизованное хранилище. Как правило, необходимые для хранилища данные не хранятся в окончательном виде ни в одной из OLTP-систем. Эти данные обычно можно получить из исходных баз данных путем специальных преобразований, вычислений и агрегирования.
Кроме того, несмотря на различную функциональную направленность, исходные транзакционные системы часто «пересекаются» по данным, т.е. их локальные базы данных содержат однотипную по смыслу информацию. Это, прежде всего, касается нормативно-справочной информации, которая используется в том или ином виде в любой OLTP-системе. При этом существенно, что одинаковые по смыслу данные обычно имеют в разных системах различный формат, вид представления, идентификацию, единицы измерения и т.п. Перед загрузкой в хранилище вся эта информация должна быть согласована, чтобы обеспечить целостность и непротиворечивость аналитических данных.
Согласование данных необходимо и при загрузке данных из одного источника. Дело в том, что в хранилище хранятся исторические данные, т.е. данные за достаточно большой промежуток времени. В оперативной системе данные хранятся в целостном виде за ограниченный промежуток, после чего они отправляются в архив. При изменениях в структуре или собственно данных архивы не подвергаются никакой дополнительной обработке, а хранятся в исходном виде. Следовательно, при необходимости иметь данные за достаточно большой период времени необходимо согласовывать архивную информацию с текущей.
Таким образом, загрузка данных из источников в хранилище осуществляется специальными процедурами, позволяющими:
· извлекать данные из различных баз данных, текстовых файлов;
· выполнять различные типы согласования и очистки данных;
· преобразовывать данные при перемещении их от источников к хранилищу;
· загружать согласованные и «очищенные» данные в структуры хранилища.
Слой хранения данных.
Слой хранения данных предназначен непосредственно для хранения значимой, проверенной, согласованной, непротиворечивой и хронологически целостной информации, которую с достаточно высокой степенью уверенности можно считать достоверной.
Собственно ХД не ориентировано на решение какой-либо определенной функциональной аналитической задачи. Цель ХД - обеспечить целостность и поддерживать хронологию всевозможных корпоративных данных, и с этой точки зрения оно нейтрально по отношению к приложениям. В связи с этим в большинстве случаев для выполнения определенного комплекса функционально замкнутых аналитических задач рационально создавать витрины данных, в основе которых может быть как многомерная, так и реляционная модель данных. По существу витрина представляет собой относительно небольшое, но что самое важное, функционально-ориентированное ХД, в котором информация хранится специальным образом, оптимизированным с точки зрения решения конкретных аналитических задач некоторого подразделения или группы аналитиков.
ХД чаще всего реализуется в виде реляционной БД, работающей под управлением достаточно мощной реляционной СУБД. Такая СУБД должна поддерживать эффективную работу с терабайтными объемами информации, иметь развитые средства ограничения доступа, обеспечивать повышенный уровень надежности и безопасности, соответствовать необходимым требованиям по восстановлению и архивации.
Для организации доступа аналитиков к данным ХД и ВД используются специализированные рабочие места, поддерживающие необходимые технологии как оперативного, так и долговременного анализа. Результаты работы аналитиков оформляются в виде отчетов, графиков, рекомендаций и сохраняются как на локальном компьютере, так и в общедоступном узле локальной сети.
Аналитическая деятельность в рамках корпорации достаточно разнообразна и определяется характером решаемых задач, организационными особенностями компании, уровнем и степенью подготовленности аналитиков.
В связи с этим современный подход к инструментальным средствам анализа не ограничивается использованием какой-то одной технологи. В настоящее время принято различать следующие основные виды аналитической деятельности:
· стандартная отчетность;
· нерегламентированные запросы;
· многомерный анализ (OLAP);
· извлечение знаний (data mining).
Каждая из этих технологий имеет свои особенности, определенный набор типовых задач и должна поддерживаться специализированной инструментальной средой.
Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства.
Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных - серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере.
Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний StatSoft и SPSS) и в некоторых электронных таблицах. В частности, средствами многомерного анализа обладает Microsoft Excel. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения.
Надстройки к пакету приложений Microsoft Office для извлечения и обработки данных представляют собой ряд функций, обеспечивающих доступ к возможностям извлечения и обработки данных из приложений Microsoft Office, и тем самым позволяющих осуществлять прогностический анализ на локальном компьютере. Благодаря тому, что встроенные в службы платформы Microsoft SQL Server алгоритмы извлечения и обработки данных доступны из среды приложений Microsoft Office, бизнес-пользователи могут легко извлекать ценную информацию из сложных наборов данных всего несколькими щелчками мыши. Надстройки к пакету приложений Office для извлечения и обработки данных дают конечным пользователям возможность выполнять анализ непосредственно в приложениях Microsoft Excel и Microsoft Visio.
В состав Microsoft Office 2007 входят три отдельных OLAP-компонента:
· клиент извлечения и обработки данных для Excel позволяет создавать проекты извлечения и обработки данных на базе служб SSAS и управлять ими из Excel 2007;
· средства анализа таблиц для приложения Excel позволяют использовать встроенные в службы SSAS функции извлечения и обработки информации для анализа данных, хранящихся в таблицах Excel;
· шаблоны извлечения и обработки данных для приложения Visio позволяют визуализировать деревья решений, деревья регрессии, кластерные диаграммы и сети зависимостей на диаграммах Visio.
С помощью приложения Microsoft Office Visio можно аннотировать, дополнять и отображать графические представления результатов извлечения и обработки данных. Платформа SQL Server 2008 в сочетании с приложением Visio 2007 позволяет:
· визуализировать деревья решений, деревья регрессии, кластерные диаграммы и сети зависимостей;
· сохранять модели извлечения и обработки данных в виде документов Visio, внедренных в другие документы приложений Office или сохраненных в виде веб-страниц.
Клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров, - ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба.
Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с настольными: в случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Отметим, что средства анализа и обработки данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Database Server и Microsoft SQL Server.
Некоторые клиентские OLAP-средства (в частности, Microsoft Excel) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Помимо этого имеется немало продуктов, представляющих собой клиентские приложения к OLAP-средствам различных производителей.
OLAP-серверы скрывают от конечного пользователя способ реализации многомерной модели. Они формируют гиперкуб, с которым пользователи посредством OLAP-клиента выполняют необходимые манипуляции, анализируя данные. Однако способ реализации важен, поскольку от него зависят производительность решения и требуемые ресурсы.
Существует три основных способа реализации многомерной модели - MOLAP, ROLAP, HOLAP.
MOLAP (Multidimensional OLAP) - для реализации многомерной модели используются многомерные БД. При этом данные хранятся в виде упорядоченных многомерных массивов. Такие массивы подразделяются на гиперкубы, в которых все хранимые в БД ячейки имеют одинаковую мерность, и поликубы, в которых каждая ячейка хранится с собственным набором измерений. Физически данные хранятся в «плоских» файлах, при этом куб представляется в виде одной плоской таблицы, в которую построчно вписываются все комбинации элементов всех измерений с соответствующими им значениями мер.
Преимущества использования многомерных БД в OLAP-системах: поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную БД, так как многомерная БД денормализована и содержит заранее агрегированные показатели, обеспечивая оптимизированный доступ к запрашиваемым ячейкам и не требуя дополнительных преобразований при переходе от множества связанных таблиц к многомерной модели; многомерные БД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных БД достаточно сложным, а иногда и невозможным.
Недостатки MOLAP: за счет денормализации и предварительно выполненной агрегации объем данных в многомерной БД, как правило, соответствует (по оценке Кодда) в 2,5 ... 100 раз меньшему объему исходных детализированных данных; в подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удается удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в максимально большие непрерывные группы. Кроме того, оптимальный с точки зрения хранения разреженных данных порядок сортировки, скорее всего, не будет совпадать с порядком, который чаще всего используется в запросах. Поэтому в реальных системах приходится искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных; многомерные БД чувствительны к изменениям в многомерной модели. Например, при добавлении нового измерения приходится изменять структуру всей БД, что влечет за собой большие затраты времени.
На основании анализа достоинств и недостатков многомерных БД можно выделить следующие условия, при которых их использование является эффективным:
· объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), т. е. уровень агрегации данных достаточно высок;
· набор информационных измерений стабилен;
· время ответа системы на нерегламентированные запросы является наиболее критичным параметром;
· требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
ROLAP.
ROLAP (Relational OLAP) - для реализации многомерной модели используются реляционные БД.
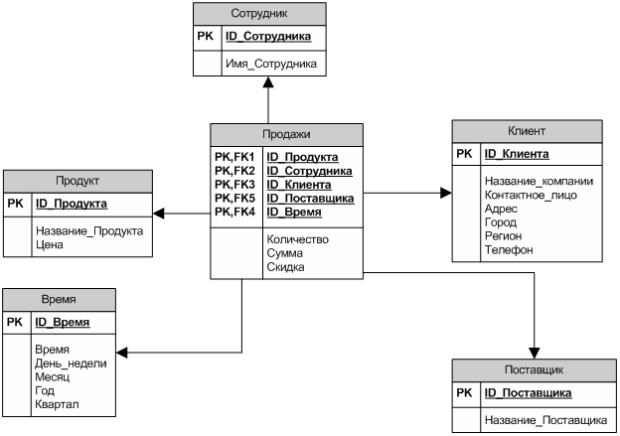
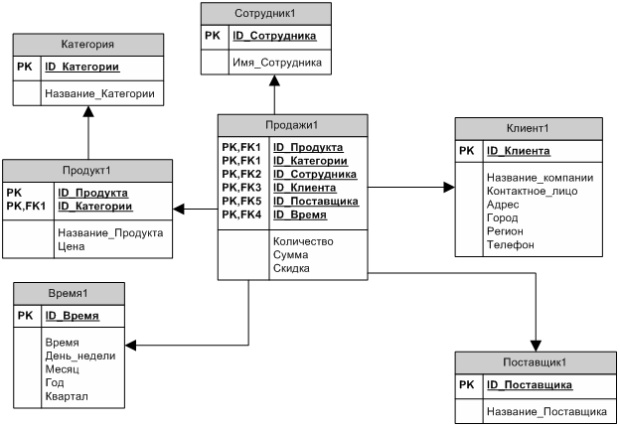
В настоящее время распространены две основные схемы реализации многомерного представления данных с помощью реляционных таблиц: схема «звезда» (рисунок 8) и схема «снежинка» (рисунок 9).
Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema). Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (outrigger table).
Рис. 8. Пример схемы данных «звезда»
Рис. 9. Пример схемы данных «снежинка»
В сложных задачах с иерархическими измерениями целесообразно использование схемы «снежинка». В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений. Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.
Увеличение числа таблиц фактов в БД определяется не только множественностью уровней различных измерений, но и тем обстоятельством, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД со схемой «звезда» из внешних источников и сложностям администрирования.
Использование реляционных БД в OLAP-системах имеет следующие достоинства:
· в большинстве случаев корпоративные ХД реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP;
· в случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP-системы с динамическим представлением размерности являются оптимальным решением, т. к. в них такие модификации не требуют физической реорганизации БД;
· реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов. Только при использовании схем типа «звезда» производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных.
HOLAP.
HOLAP (Hybrid OLAP) - для реализации многомерной модели используются и многомерные, и реляционные БД. HOLAP-серверы используют гибридную архитектуру, которая объединяет технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда данные более-менее плотные, серверы ROLAP показывают лучшие параметры в тех случаях, когда данные довольно разрежены. Серверы HOLAP применяют подход ROLAP для разреженных областей многомерного пространства и подход MOLAP - для плотных областей. Серверы HOLAP разделяют запрос на несколько подзапросов, направляют их к соответствующим фрагментам данных, комбинируют результаты, а затем предоставляют результат пользователю.
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008.
2. Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных странах: Учебник. – М.: Логос, 2008. – 392 с.
3. Смирнов Э.А. Разработка управленческих решений. – М.: ИНФРА-М, 2008. – 272 с.
4. Трахтенгерц Э.А. Компьютерная поддержка принятия решений: Научно-практическое издание. – М.: СИНТЕГ, 1998. – 376 с.
5. Фатхутдинов Р.А. Разработка управленческого решения: Учеб. пособ. – М.: Бизнес-школа, Интел-Синтез, 2007. – 272 с.
Цель: изучить особенности принятия решений в условиях неопределенности, а также технологии KDD и ETL – процесс в СППР.
Задачи:
· Сформулировать методы принятия решений в условиях неопределенности.
· Рассмотреть технологии KDD.
· Описать ETL –процесс в СППР.
Вопросы темы:
1. Принятие решений в условиях неопределенности.
2. Технология KDD.
3. ETL – процесс в СППР.
Большинство задач планирования зависит от ряда
неизвестных заранее и неуправляемых факторов. Эти задачи обладают той или иной
степенью неопределенности, которая может быть как объективной, так и
субъективной, зависящей от индивидуальных психофизических параметров ЛИР. В
таких задачах неизвестно распределение вероятностей ![]() ,
с которыми внешняя среда может находиться в одном из возможных состояний
,
с которыми внешняя среда может находиться в одном из возможных состояний ![]() . В этом случае ЛДР выдвигает только
определенные гипотезы относительно состояний внешней среды.
. В этом случае ЛДР выдвигает только
определенные гипотезы относительно состояний внешней среды.
Таким образом, для ЛПР, действующего в условиях неопределенности и невозможности получения дополнительной информации о неопределенных факторах, элементами описания ситуации планирования являются:
·
множество допустимых стратегий
(множество возможных альтернатив действий ЛПР) ![]() ;
;
·
множество возможных состояний
внешней среды (множество гипотез) ![]() .
.
Предполагается, что на множестве отношений ![]() можно задать некоторую функцию полезности
можно задать некоторую функцию полезности ![]() , которая выступает в качестве меры
желательности или полезности соответствующей альтернативы. Если множества A и Z
конечны, то мера для оценки эффективности действий ЛПР (полезность исходов)
представима в виде матрицы. Каждое конкретное значение элемента матрицы
, которая выступает в качестве меры
желательности или полезности соответствующей альтернативы. Если множества A и Z
конечны, то мера для оценки эффективности действий ЛПР (полезность исходов)
представима в виде матрицы. Каждое конкретное значение элемента матрицы ![]() (см. табл. 1) характеризует выбор
i-й стратегии (альтернативы Ai)
при состоянии внешней среды
(см. табл. 1) характеризует выбор
i-й стратегии (альтернативы Ai)
при состоянии внешней среды ![]() . Для выбора
лучшей стратегии имеется ряд специальных методов, ориентированных на
использование в условиях неопределенности, которые рассмотрены и
проиллюстрированы ниже.
. Для выбора
лучшей стратегии имеется ряд специальных методов, ориентированных на
использование в условиях неопределенности, которые рассмотрены и
проиллюстрированы ниже.
Критерий максимина (принцип гарантированного результата, или критерий Вальда). Данный принцип заключается в выборе в качестве оптимальной (наиболее эффективной) той альтернативы (стратегии), которая имеет наибольшее среди наименее благоприятных состояний внешней среды значение функции полезности. Таким образом, оптимальной, считается альтернатива A*, для которой выполняется соотношение:
![]() (7)
(7)
Здесь ![]() есть значение
функции полезности при альтернативе
есть значение
функции полезности при альтернативе ![]() и состоянии
внешней среды
и состоянии
внешней среды ![]() . Найденная оптимальная
альтернатива
. Найденная оптимальная
альтернатива ![]() выбранная по критерию Вальда,
обеспечивает гарантированный выигрыш (успех в достижении цели) при наихудшем
для данной фирмы состоянии внешней среды.
выбранная по критерию Вальда,
обеспечивает гарантированный выигрыш (успех в достижении цели) при наихудшем
для данной фирмы состоянии внешней среды.
Рассмотрим следующий пример. Исходная таблица решений характеризуется данными, привёденными в табл. 12.
Таблица 12.
Ожидаемые значения прибыли (тыс. ден. ед.) для трех товарных рынков
|
Возможные новые товарные рынки |
Политическая обстановка |
|||
|
стабильная |
стабильная |
нестабильная |
нестабильная |
|
|
Степень конкуренции |
||||
|
слабая, Z1 |
сильная, Z2 |
слабая, Z3 |
сильная, Z4 |
|
|
Рынок, А1 |
530 |
460 |
240 |
220 |
|
Рынок, А2 |
490 |
390 |
300 |
270 |
|
Рынок, А3 |
575 |
420 |
260 |
190 |
Сначала для каждой альтернативы выбираем по соответствующей строке минимальное значение функции полезности, т.е.
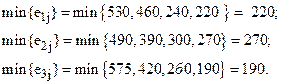
Далее из полученных минимальных значений в соответствии с (7) выбирается максимальное:
![]()
Таблица 13.
|
Возможные новые товарные рынки |
Политическая обстановка |
Min по строке |
|||
|
стабильная |
стабильная |
нестабильная |
нестабильная |
||
|
Степень конкуренции |
|||||
|
слабая, Z1 |
сильная, Z2 |
слабая, Z3 |
сильная, Z4 |
||
|
Рынок, А1 |
530 |
460 |
240 |
220 |
220 |
|
Рынок, А2 |
490 |
390 |
300 |
270 |
270=max |
|
Рынок, А3 |
575 |
420 |
260 |
190 |
190 |
Следовательно, оптимальной по критерию максимина
является альтернатива ![]() , т.е. фирме целесообразно
выходить со своим товаром на рынок А2. Это самая осторожная
стратегия, так как при любом состоянии внешней среды фирма получит прибыль не
менее 270 тыс.ден.ед.
, т.е. фирме целесообразно
выходить со своим товаром на рынок А2. Это самая осторожная
стратегия, так как при любом состоянии внешней среды фирма получит прибыль не
менее 270 тыс.ден.ед.
Критерий максимакса (принцип безудержного оптимизма). Если критерий максимина ориентирован на получение гарантированного минимума желаемого результата (правило «лучший» из «худших”), то критерий оптимизма предполагает возможность получения максимального уровня желательности результата. Эта альтернатива А* выбирается исходя из выражения
![]() (8)
(8)
Рассматривая исходные данные (табл. 12) с точки зрения принципа оптимизма (8), получим:
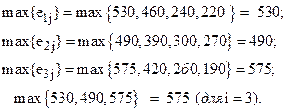
Таким образом, оптимальной по критерию
оптимизма будет альтернатива ![]() , для которой
справедливо соотношение:
, для которой
справедливо соотношение:
![]()
Таблица 14.
|
Возможные новые товарные рынки |
Политическая обстановка |
Max по строке |
|||
|
стабильная |
стабильная |
нестабильная |
нестабильная |
||
|
Степень конкуренции |
|||||
|
слабая, Z1 |
сильная, Z2 |
слабая, Z3 |
сильная, Z4 |
||
|
Рынок, А1 |
530 |
460 |
240 |
220 |
530 |
|
Рынок, А2 |
490 |
390 |
300 |
270 |
490 |
|
Рынок, А3 |
575 |
420 |
260 |
190 |
575=max |
Критерий Гурвица. Данный критерий представляет собой комбинацию принципа гарантированного результата и принципа оптимизма. Функция, описывающая критерий Гурвица, представляется в виде:
![]() (9)
(9)
где ![]() - стратегия
выбора альтернативы, характеризующая принцип гарантированного результата, а
- стратегия
выбора альтернативы, характеризующая принцип гарантированного результата, а ![]() - принципа оптимизма;
- принципа оптимизма; ![]() - весовой коэффициент.
- весовой коэффициент.
Так как ![]()
то общее выражение для принципа Гурвица на основании (9) будет иметь следующий вид:
![]()
или
![]()
Здесь используются две гипотезы: первая - среда
находится с вероятностью а в самом невыгодном состоянии и вторая - среда
находится с вероятностью ![]() в самом
выгодном состоянии.
в самом
выгодном состоянии.
В зависимости от значения весового коэффициента ![]() можно получить различные предпочтительные
альтернативы. Причем если
можно получить различные предпочтительные
альтернативы. Причем если ![]() , то имеем
принцип оптимизма, если
, то имеем
принцип оптимизма, если ![]() , то получим
принцип гарантированного результата.
, то получим
принцип гарантированного результата.
Используя этот критерий, обратимся опять к нашим данным (табл. 12). Пусть весовой коэффициент, характеризующий степень важности соответствующей альтернативы, равен 0,7. Тогда получим:
![]() (10)
(10)
Подставляя значения из табл. 12 в выражение (10), имеем:
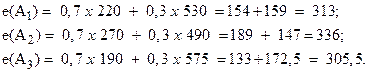
Далее производим выбор на основе следующей стратегии:
![]()
Подставляя вычисленные ранее значения, получим:
![]()
Таким образом, оптимальной по принципу Гурвица при
коэффициенте ![]() будет альтернатива
будет альтернатива ![]() .
.
Приведем решение данным методом в следующей таблице:
Таблица 15.
|
Возможные новые рынки
|
Политическая обстановка |
Критерий е(А) по строкам |
|||
|
стабильная |
стабильная |
нестабил. |
нестабил. |
||
|
Степень конкуренции |
|||||
|
слабая,Z1 |
сильная,Z2 |
слабая,Z3 |
сильная,Z4 |
||
|
Рынок, А1 |
530=max(A1) |
460 |
240 |
220=min(A1) |
0,7*220+0,3*530=313 |
|
Рынок, А2 |
490=max(A2) |
390 |
300 |
270=min(A2) |
0,7*270+0,3*490=336=max |
|
Рынок, А3 |
575=max(A3) |
420 |
260 |
190=min(A3) |
0,7*190+0,3*575=305,5 |
Если же весовой коэффициент равен 0,2 то решение изменится следующим образом:
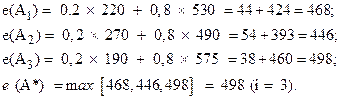
Оптимальной стратегией в этом случае будет работа
фирмы на рынке ![]() .
.
Приведем решение в виде таблицы:
Таблица 16.
|
Возможные новые рынки
|
Политическая обстановка |
Критерий е(А) по строкам |
|||
|
стабильная |
стабильная |
нестабил. |
нестабил. |
||
|
Степень конкуренции |
|||||
|
слабая,Z1 |
сильная,Z2 |
слабая,Z3 |
сильная,Z4 |
||
|
Рынок, А1 |
530=max(A1) |
460 |
240 |
220=min(A1) |
0,2*220+0,8*530=468 |
|
Рынок, А2 |
490=max(A2) |
390 |
300 |
270=min(A2) |
0,2*270+0,8*490=446 |
|
Рынок, А3 |
575=max(A3) |
420 |
260 |
190=min(A3) |
0,2*190+0,8*575=498=max |
Наконец, если положить ![]() , то получим следующее решение:
, то получим следующее решение:
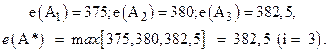
И в этом случае оптимальной стратегией будет работа на
рынке ![]() .
.
Приведем решение в виде таблицы:
Таблица 17.
|
Возможные новые рынки
|
Политическая обстановка |
Критерий е(А) по строкам |
|||
|
стабильная |
стабильная |
нестабил. |
нестабил. |
||
|
Степень конкуренции |
|||||
|
слабая,Z1 |
сильная,Z2 |
слабая,Z3 |
сильная,Z4 |
||
|
Рынок, А1 |
530=max(A1) |
460 |
240 |
220=min(A1) |
0,5*220+0,5*530=375 |
|
Рынок, А2 |
490=max(A2) |
390 |
300 |
270=min(A2) |
0,5*270+0,5*490=380 |
|
Рынок, А3 |
575=max(A3) |
420 |
260 |
190=min(A3) |
0,5*190+0,5*575=382,5=max |
Заметим, что если фирма желает, например, работать на всех трех рынках, то, используя принцип Гурвица, можно принять следующее решение по распределению долей продукции (долей объемов продаж) между рынками, применив формулу:
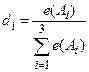
где ![]() . - доля товара
в натуральном или денежном выражении, реализуемого на рынке
. - доля товара
в натуральном или денежном выражении, реализуемого на рынке ![]() .
.
В общем случае процентное соотношение распределения товара по рынкам с использованием критерия Гурвица может быть вычислено по аналогичной формуле:
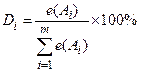 (11)
(11)
где ![]() - доля товара,
реализуемого на рынке
- доля товара,
реализуемого на рынке ![]() , выраженная в процентах;
m - количество рассматриваемых рынков.
, выраженная в процентах;
m - количество рассматриваемых рынков.
В нашем примере при ![]() , если рассматривать все три рынка, то,
используя формулу (11), получим следующее процентное распределение товара между
рынками:
, если рассматривать все три рынка, то,
используя формулу (11), получим следующее процентное распределение товара между
рынками:
Однако представляется более рациональным
распределить товар между рынками ![]() и
и ![]() , так как рынок
, так как рынок ![]() должен
быть выбран согласно принципу гарантированного результата, а рынок
должен
быть выбран согласно принципу гарантированного результата, а рынок ![]() - согласно принципу оптимизма, причем
изменение весового коэффициента в принципе Гурвица приводит к тем же
альтернативам
- согласно принципу оптимизма, причем
изменение весового коэффициента в принципе Гурвица приводит к тем же
альтернативам ![]() и
и ![]() .
Поэтому, используя формулу (11) для двух рынков и
.
Поэтому, используя формулу (11) для двух рынков и ![]() ,
получим следующее процентное распределение товара между ними:
,
получим следующее процентное распределение товара между ними:
Вообще говоря, здесь мы имеем пропорциональное распределение рисков. Данный подход может быть использован в практических расчетах.
Критерий минимаксного сожаления (принцип Сэвиджа). Стратегия выбора по принципу Сэвиджа характеризует те потенциальные потери, которые фирма будет иметь, если выберет неоптимальное решение. Детализированная процедура выбора в этом случае производится в три этапа.
1. Для каждого состояния внешней среды по конкретной альтернативе определяется максимальное значение функции полезности:
![]() (12)
(12)
Это есть, возможно, наилучший уровень полезности,
который можно получить для конкретного состояния внешней среды![]() .
.
2. На основании значений, вычисленных по формуле (12), для каждой альтернативы строится показатель:
![]() (13)
(13)
Данный показатель характеризует потенциальный риск, а точнее потерянную выгоду от выбора неоптимальной альтернативы. В результате этого действия формируется матрица потенциальных потерь.
3. Используя полученную на предыдущем этапе матрицу потерь (или, как еще говорят, матрицу сожалений), производится выбор стратегии с наименьшим показателем риска:
![]() (14)
(14)
Данный критерий минимизирует возможные потери при условии, что состояние внешней среды наихудшим образом отличается от предполагаемого. Рассмотрим применение принципа Сэвиджа на исходных данных (табл. 12) в соответствии с описанной выше процедурой.
1. Для значений функции полезности по каждому состоянию внешней среды Z1, Z2, Z3, Z4 на основании (12) определим максимальный уровень полезности:
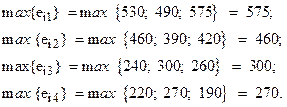
Таблица 18.
|
Возможные новые товарные рынки |
Политическая обстановка |
|||
|
стабильная |
стабильная |
нестабильная |
нестабильная |
|
|
Степень конкуренции |
||||
|
слабая, Z1 |
сильная, Z2 |
слабая, Z3 |
сильная, Z4 |
|
|
Рынок, А1 |
530 |
460=max(Z2) |
240 |
220 |
|
Рынок, А2 |
490 |
390 |
300=max(Z3) |
270=max(Z4) |
|
Рынок, А3 |
575=max(Z1) |
420 |
260 |
190 |
2. Вычислим элементы матрицы потенциальных потерь согласно формуле (13):
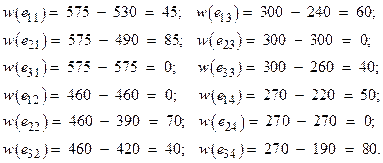
Таким образом, матрица потерь будет иметь следующий вид (табл. 19).
Таблица 19.
Матрица потенциальных потерь
|
Альтернативы |
Состояния внешней среды |
|||
|
Z1 |
Z2 |
Z3 |
Z4 |
|
|
А1 |
575-530=45 |
460-460=0 |
300-240=60 |
270-220=50 |
|
А2 |
575-490=85 |
70 |
0 |
0 |
|
А3 |
575-575=0 |
40 |
40 |
80 |
3. На основании матрицы потерь (табл. 19) можно определить максимальные потери по каждой альтернативе. Для этого применим правило:
![]()
Для каждого i= 1,2,3 определим:
w(A1)= mах [45; 0; 60; 50] = 60;
w(A2)= mах [85; 70; 0; 0] = 85;
w(A3)= mах [0; 40; 40; 80] = 80.
Таблица 20.
|
Альтернативы |
Состояния внешней среды |
|||
|
Z1 |
Z2 |
Z3 |
Z4 |
|
|
А1 |
45 |
0 |
60=max(A1)=min(max) |
50 |
|
А2 |
85=max(A2) |
70 |
0 |
0 |
|
А3 |
0 |
40 |
40 |
80=max(A3) |
Оптимальной будет та альтернатива, которая имеет минимальные потери согласно выражению (14):
![]()
![]()
Следовательно, оптимальна альтернатива A1 имеющая минимальные потери выгоды.
Критерий Лапласа. Данный критерий применяется, если состояния внешней среды неизвестны, но их можно считать равновероятными, т. е.
![]()
Решающее правило в этом случае имеет следующий вид:
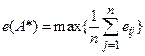
В рассматриваемом примере:
Следовательно, с точки зрения критерия Лапласа можно выбрать как рынок A1, так и рынок A2.
Таблица 21.
|
|
Политическая обстановка |
Критерий е(А) по строкам |
|||
|
стабильная |
стаб. |
нестаб. |
нестаб. |
||
|
Степень конкуренции |
|||||
|
слабая,Z1 |
сильная,Z2 |
слабая,Z3 |
сильная,Z4 |
||
|
А1 |
530 |
460 |
240 |
220 |
(530+460+240+220) / 4=362,5=max |
|
А2 |
490 |
390 |
300 |
270 |
(490+390+300+270) / 4=362,5 |
|
А3 |
575 |
420 |
260 |
190 |
(575+420+260+190) / 4=361,25=max |
Сделаем несколько практических рекомендаций по применению рассмотренных выше критериев (принципов).
1. Критерий Вальда лучше всего использовать тогда, когда фирма желает свести риск от принятого решения к минимуму.
2. Коэффициент в критерии Гурвица выбирается из субъективных соображений: чем опаснее ситуация, тем больше ЛПР желает подстраховаться.
3. Критерий Сэвиджа удобен, если для предприятия приемлем некоторый риск.
4. Критерий Лапласа может быть применен, когда ЛПР не может предпочесть ни одной гипотезы.
Knowledge Discovery in Databases (KDD) - это процесс поиска полезных знаний в “сырых данных”. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных, интерпретации полученных результатов. Безусловно, сердцем всего этого процесса являются методы DM, позволяющие обнаруживать знания.
Этими знаниями могут быть правила, описывающие связи между свойствами данных (деревья решений), часто встречающиеся шаблоны (ассоциативные правила), а также результаты классификации (нейронные сети) и кластеризации данных (карты Кохонена) и т.д.
Процесс KDD, состоит из следующих шагов:
1. Подготовка исходного набора данных. Этот этап заключается в создании набора данных, в том числе из различных источников, выбора обучающей выборки и т.д. Для этого должны существовать развитые инструменты доступа к различным источникам данных. Желательна поддержка работы с хранилищами данных и наличие семантического слоя, позволяющего использовать для подготовки исходных данных не технические термины, а бизнес понятия.
2. Предобработка данных. Для того, чтобы эффективно применять методы Data Mining, следует обратить серьезное внимание на вопросы предобработки данных. Данные могут содержать пропуски, шумы, аномальные значения и т.д. Кроме того, данные могут быть избыточны, недостаточны ит.д. В некоторых задачах требуется дополнить данные некоторой априорной информацией. Наивно предполагать, что если подать данные на вход системы в существующем виде, то на выходе получим полезные знания. Данные должны быть качественны и корректны с точки зрения используемого метода DM. Поэтому первый этап KDD заключается в предобработке данных. Более того, иногда размерность исходного пространства может быть очень большой, и тогда желательно применение специальных алгоритмов понижения размерности. Это как отбор значимых признаков, так и отображение данных в пространство меньшей размерности.
3. Трансформация, нормализация данных. Этот шаг необходим для приведения информации к пригодному для последующего анализа виду. Для чего нужно проделать, например, такие операции как приведение типов, квантование, приведение к 'скользящему окну' и прочее. Кроме того, некоторые методы анализа, которые требуют, чтобы исходные данные были в каком-то определенном виде. Нейронные сети, скажем, работают только с числовыми данными, причем они должны быть нормализованы.
4. Data Mining. На этом шаге применяются различные алгоритмы для нахождения знаний. Это нейронные сети, деревья решений, алгоритмы кластеризации и установления ассоциаций и т.д.
5. Постобработка данных. Интерпретация результатов и применение полученных знаний в бизнес приложениях.
Knowledge Discovery in Databases не задает набор методов обработки или пригодные для анализа алгоритмы, он определяет последовательность действий, которые необходимо сделать для того, чтобы из исходных данных знания. Данный подход универсальный и не зависит от предметной области, что является его несомненным достоинством.
Data Mining.
Термин Data Mining дословно переводится как «добыча данных» или «раскопка данных» и имеет в англоязычной среде несколько определений.
Определение.
Зависимости и шаблоны, найденные в процессе применения методов Data Mining, должны быть нетривиальными и ранее неизвестными, например, сведения о средних продажах таковыми не являются. Знания должны описывать новые связи между свойствами, предсказывать значения одних признаков на основе других.
Нередко KDD отождествляют с Data Mining. Однако правильнее считать Data Mining шагом процесса KDD.
Data Mining – обнаружение в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Data Mining – это не один метод, а совокупность большого числа различных методов обнаружения знаний. Существует несколько условных классификаций задач Data Mining. Мы будем говорить о четырех базовых классах задач.
Классификация – это установление зависимости дискретной выходной переменной от входных переменных.
Регрессия – это установление зависимости непрерывной выходной переменной от входных переменных.
Кластеризация – это группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры.
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее называют анализом рыночной корзины (market basket analysis). Если же нас интересует последовательность происходящих событий, то можно говорить о последовательных шаблонах – установлении закономерностей между связанными во времени событиями. Примером такой закономерности служит правило, указывающее, что из события X спустя время t последует событие Y.
Кроме перечисленных задач, часто выделяют анализ отклонений (deviation detection), анализ связей (link analysis), отбор значимых признаков (feature selection), хотя эти задачи граничат с очисткой и визуализацией данных.
Задача классификации отличается от задачи регрессии тем, что в классификации на выходе присутствует переменная дискретного вида, называемая меткой класса. Решение задачи классификации сводится к определению класса объекта по его признакам, при этом множество классов, к которым может быть отнесен объект, известно заранее. В задаче регрессии выходная переменная является непрерывной – множеством действительных чисел, например сумма продаж. К задаче регрессии сводится, в частности, прогнозирование временного ряда на основе исторических данных.
Кластеризация отличается от классификации тем, что выходная переменная не требуется, а число кластеров, в которые необходимо сгруппировать все множество данных, может быть неизвестным. Выходом кластеризации является не готовый ответ (например, плохо/удовлетворительно/хорошо), а группы похожих объектов – кластеры. Кластеризация указывает только на схожесть объектов, и не более того. Для объяснения образовавшихся кластеров необходима их дополнительная интерпретация.
Перечислим наиболее известные применения этих задач в экономике.
Классификация используется, если заранее известны класс, например, при отнесении нового товара к той или иной товарной группе, клиента к какой-либо категории (при кредитовании – по каким-то признакам к одной из групп риска).
Регрессия используется для установления зависимостей между факторами. Например, в задаче прогнозирования зависимая величина – объемы продаж, а факторами, влияющими на нее, могут быть предыдущие объемы продаж, изменение курсов валют, активность конкурентов и т. д. Или, например, при кредитовании физических лиц вероятность возврата кредита зависит от личных характеристик человека, сферы его деятельности, наличия имущества.
Кластеризация может использоваться для сегментации и построения профилей клиентов. При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально, поэтому их удобно объединять в группы – сегменты с однородными признаками. Выделять сегменты можно по нескольким группам признаков, например по сфере деятельности, по географическому расположению. После кластеризации можно узнать, какие сегменты наиболее активны, какие приносят наибольшую прибыль, выделить характерные для них признаки. Эффективность работы с клиентами повышается благодаря учету их персональных предпочтений.
Ассоциативные правила помогают выявлять совместно приобретаемые товары. Это может быть полезно для более удобного размещения товара на прилавках, стимулирования продаж. Тогда человек, купивший пачку спагетти, не забудет купить к ней бутылочку соуса.
Последовательные шаблоны могут использоваться при планировании продаж или предоставления услуг. Они похожи на ассоциативные правила, но в анализе добавляется временной показатель, то есть важна последовательность совершения операций. Например, если заемщик взял потребительский кредит, то с вероятностью 60 % через полгода он оформит кредитную карту.
Для решения вышеперечисленных задач используются различные методы и алгоритмы Data Mining. Ввиду того что Data Mining развивается на стыке таких дисциплин, как математика, статистика, теория информации, машинное обучение, теория баз данных, программирование, параллельные вычисления, вполне закономерно, что большинство алгоритмов и методов Data Mining были разработаны на основе подходов, применяемых в этих дисциплинах.
В общем случае непринципиально, каким именно алгоритмом будет решаться задача, главное – иметь метод решения для каждого класса задач. На сегодняшний день наибольшее распространение в Data Mining получили методы машинного обучения: деревья решений, нейронные сети, ассоциативные правила и т. д.
Определение.
Общая постановка задачи обучения следующая. Имеется множество объектов (ситуаций) и множество возможных ответов (откликов, реакций). Между ответами и объектами существует некоторая зависимость, но она неизвестна. Известна только конечная совокупность прецедентов – пар вида «объект – ответ», – называемая обучающей выборкой. На основе этих данных требуется обнаружить зависимость, то есть построить модель, способную для любого объекта выдать достаточно точный ответ. Чтобы измерить точность ответов, вводится критерий качества.
Решение подавляющего большинства бизнес-задач сводится к процессу KDD. Ранее были описаны базовые блоки, из которых собирается практически любое бизнес-решение.
Отметим, что Data Mining не ограничивается алгоритмами решения упомянутых классов задач.
Существует несколько современных подходов, которые «встраиваются» внутрь алгоритмов машинного обучения, придавая им новые свойства. Так, генетические алгоритмы призваны эффективно решать задачи оптимизации, поэтому их можно встретить в процедурах обучения нейронных сетей, карт Кохонена, логистической регрессии, при отборе значимых признаков.
Математический аппарат нечеткой логики (fuzzy logic) также успешно включается в состав практически всех алгоритмов Data Mining; так появились нечеткие нейронные сети, нечеткие деревья решений, нечеткие ассоциативные правила. Объединение технологии хранилищ данных и нечетких запросов позволяет аналитикам получать нечеткие срезы. И подобных примеров множество.
Причины распространения KDD и Data Mining.
В KDD и Data Mining нет ничего принципиально нового. Специалисты в различных областях человеческого знания решали подобные задачи на протяжении нескольких десятилетий.
Однако в последние годы интеллектуальная составляющая бизнеса стала возрастать, и для распространения технологий KDD и Data Mining были созданы все необходимые и достаточные условия:
1. Развитие технологий автоматизированной обработки информации создало основу для учета сколь угодно большого количества факторов и достаточного объема данных.
2. Возникла острая нехватка высококвалифицированных специалистов в области статистики и анализа данных. Поэтому потребовались технологии обработки и анализа, доступные для специалистов любого профиля за счет применения методов визуализации и самообучающихся алгоритмов.
3. Возникла объективная потребность в тиражировании знаний. Полученные в процессе KDD и Data Mining результаты являются формализованным описанием некоего процесса, а следовательно, поддаются автоматической обработке и повторному использованию на новых данных.
4. На рынке появились программные продукты, поддерживающие технологии KDD и Data Mining, – аналитические платформы. С их помощью можно создавать полноценные аналитические решения и быстро получать первые результаты.
Под аббревиатурой ETL (extraction, transformation, loading – извлечение, преобразование и загрузка данных) понимается составной процесс переноса данных одного приложения или автоматизированной информационной системы в другие.
Процесс ETL реализуется путем либо разработки приложения ETL, либо создания комплекса встроенных программных процедур, либо использования ETL-инструментария. Приложения ETL извлекают информацию из исходных БД источников, преобразуют ее в формат, поддерживаемый БД назначения, а затем загружают в эту БД преобразованные данные.
Цель любого ETL-приложения состоит в том, чтобы своевременно доставить данные из внешних систем в систему, с которой работают пользователи. Как правило, ETL-приложения используются при переносе данных внешних источников в ХД систем бизнес-аналитики. Поэтому организация процесса ETL является составной частью проекта разработки практически любого ХД.
Проектирование и разработка ETL-процесса является одной из самых важных задач проектировщика ХД. Для ХД процесс ETL имеет следующие свойства. Во-первых, объем данных, который выбирается из систем источников данных и помещается в ХД, как правило, бывает достаточно большим, до десятков Гб. Во-вторых, процесс ETL является необходимой составной частью эксплуатации ХД. Периодичность процесса ETL определяется не только потребностью пользователя в своевременных данных, но и размером загружаемой порции данных. По оценкам специалистов, ETL-процесс может занимать до 80% времени. В-третьих, на разных стадиях процесса ETL формируются метаданные ХД и обеспечивается качество данных. В-четвертых, во время процесса ETL может произойти потеря данных, поэтому необходимо обеспечивать контроль за поступлением данных в ХД. В-пятых, процесс ETL обладает свойством восстанавливаемости после сбоев без потери данных.
На рис. 10 показано место процесса ETL в архитектуре системы бизнес - аналитики на основе ХД.
Рис. 10. Процесс ETL в архитектуре хранилища данных
Как видно из рисунка, на процесс ETL возложена вся работа по подготовке данных для доставки их в ХД, формирование и обновление метаданных ХД, а также управление данными, извлеченными в результате Data mining.
Таким образом, процесс ETL состоит из трех основных стадий:
· Извлечение данных. На этой стадии отбираются и описываются данные внешних источников (начинают формироваться метаданные ХД), которые должны храниться в ХД (релевантные данные).
· Преобразование данных. На этой стадии релевантные данные преобразуются в формат представления данных в ХД, правила преобразования сохраняются в метаданных ХД, формируются ключевые поля таблиц физической структуры ХД, выполняется очистка данных.
· Загрузка данных. На этой стадии данные загружаются в ХД, выполняется построение агрегатов.
Таким образом, разработка ETL-процесса включает в себя следующие основные стадии:
· планирование ETL-процесса;
· конструирование процесса заполнения таблиц измерений;
· конструирование процесса заполнения таблиц фактов;
· извлечение данных;
· преобразование и очистка данных;
· загрузка данных.
При проектировании процессов преобразования данных проектировщик ХД должен решить следующие задачи:
· проанализировать требования к данным ХД;
· проанализировать и описать источники данных для ХД;
· создать модель преобразования данных высокого уровня;
· определить и подробно описать каждую задачу преобразования данных.
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008.
2. Батыгин Г.С. Лекции по методологии социологических исследований. М. Аспект Пресс, 1995, – 286 с.
3. Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных странах: Учебник. – М.: Логос, 2008. – 392 с.
4. Смирнов Э.А. Разработка управленческих решений. – М.: ИНФРА-М, 2008. – 272 с.
5. Трахтенгерц Э.А. Компьютерная поддержка принятия решений: Научно-практическое издание. – М.: СИНТЕГ, 1998. – 376 с.
6. Фатхутдинов Р.А. Разработка управленческого решения: Учеб. пособ. – М.: Бизнес-школа, Интел-Синтез, 2007. – 272 с.
Цель: Изучить особенности принятия решений в условиях риска, а также рассмотреть аспекты создания и использования хранилища данных в СППР.
Задачи:
· Изучить особенности принятия решений в условиях риска.
· Рассмотреть постановку задачи и ее решении в теории игр.
· Охарактеризовать алгоритмы кластеризации в Data Mining.
Вопросы темы:
1. Принятие решений в условиях риска.
2. Решение матричных игр в чистых стратегиях.
3. Алгоритмы кластеризации на службе Data Mining.
Когда выбор планового решения осуществляется в условиях риска, известны или задаются субъективные вероятности возможных состояний внешней среды. При этом постановка задачи будет следующей:
а)
имеется множество альтернатив ![]() и множество состояний внешней среды
и множество состояний внешней среды ![]() ;
;
б)
известны субъективные вероятности
состояния среды ![]() , причем
, причем  ;
;
в)
для каждого сочетания
альтернативного решения Ai и состояния ![]() задана
функциональная полезность
задана
функциональная полезность ![]() .
.
Существующие методы выбора базируются в основном на использовании вероятностных мер в качестве критериев выбора. В теории статистических решений обычно используются принцип Байеса, принцип Бернулли и принцип энтропии математического ожидания функции полезности.
Базовыми методами риск-менеджмента являются отказ от риска, снижение, передача и принятие. Риск-инструментарий значительно шире. Он включает политические, организационные, правовые, экономические, социальные инструменты, причем риск-менеджмент как система допускает возможность одновременного применения нескольких методов и инструментов риск-управления.
Наиболее часто применяемым инструментом риск-менеджмента является страхование. Страхование предполагает передачу ответственности за возмещение предполагаемого ущерба сторонней организации (страховой компании). Примерами других инструментов могут быть:
· отказ от чрезмерно рисковой деятельности (метод отказа);
· профилактика или диверсификация (метод снижения);
· аутсорсинг затратных рисковых функций (метод передачи);
· формирование резервов или запасов (метод принятия).
Подходы к оцениванию рисков. Понятие «риск», как уже отмечалось, многогранно. Например, при использовании статистических методов управления качеством продукции риски (точнее, оценки рисков) - это вероятности некоторых событий. В статистическом приемочном контроле «риск поставщика» - это вероятность забракования партии продукции хорошего качества, а «риск потребителя» - приемки «плохой» партии. При статистическом регулировании технологических процессов рассматривают риск незамеченной разладки и риск излишней наладки.
Тогда оценка риска – это оценка вероятности, точечная или интервальная, по статистическим данным или экспертная. В таком случае для управления риском задают ограничения на вероятности нежелательных событий.
Иногда под уменьшением риска понимают уменьшение дисперсии случайной величины, поскольку при этом уменьшается неопределенность. В теории принятия решений риск - это плата за принятие решения, отличного от оптимального, он обычно выражается как математическое ожидание. В экономике плата измеряется обычно в денежных единицах, т.е. в виде финансового потока (потока платежей и поступлений) в условиях неопределенности.
Методы математического моделирования позволяют предложить и изучить разнообразные методы оценки риска. Широко применяются два вида методов - статистические, основанные на использовании эмпирических данных, и экспертные, опирающиеся на мнения и интуицию специалистов.
«Игра (в математике) - это идеализированная математическая модель коллективного поведения: несколько игроков влияют на исход игры, причем их интересы различны».
Регулярное действие, выполняемое игроком во время игры, называется ходом. Совокупность ходов игрока, совершаемых им для достижения цели игры, называется стратегией.
Классификацию игр можно проводить: по количеству игроков, количеству стратегий, характеру взаимодействия игроков, характеру выигрыша, количеству ходов, состоянию информации и т.д.
В зависимости от количества игроков различают игры двух и n игроков. Первые из них наиболее изучены. Игры трёх и более игроков менее исследованы из-за возникающих принципиальных трудностей и технических возможностей получения решения.
По количеству стратегий игры делятся на конечные и бесконечные. Если в игре все игроки имеют конечное число возможных стратегий, то она называется конечной. Если же хотя бы один из игроков имеет бесконечное количество возможных стратегий, игра называется бесконечной.
По характеру взаимодействия игры делятся на бескоалиционные: игроки не имеют права вступать в соглашения, образовывать коалиции; коалиционные (кооперативные) – могут вступать в коалиции.
В кооперативных играх коалиции заранее определены.
По характеру выигрышей игры делятся на: игры с нулевой суммой (общий капитал всех игроков не меняется, а перераспределяется между игроками; сумма выигрышей всех игроков равна нулю) и игры с ненулевой суммой.
По виду функций выигрыша игры делятся на: матричные, биматричные, непрерывные, выпуклые и др.
Матричная игра – это конечная игра двух игроков с нулевой суммой, в которой задаётся выигрыш игрока 1 в виде матрицы (строка матрицы соответствует номеру применяемой стратегии игрока 1, столбец – номеру применяемой стратегии игрока 2; на пересечении строки и столбца матрицы находится выигрыш игрока 1, соответствующий применяемым стратегиям).
Для матричных игр доказано, что любая из них имеет решение и оно может быть легко найдено путём сведения игры к задаче линейного программирования.
Биматричная игра – это конечная игра двух игроков с ненулевой суммой, в которой выигрыши каждого игрока задаются матрицами отдельно для соответствующего игрока (в каждой матрице строка соответствует стратегии игрока 1, столбец – стратегии игрока 2, на пересечении строки и столбца в первой матрице находится выигрыш игрока 1, во второй матрице – выигрыш игрока 2.).
Непрерывной считается игра, в которой функция выигрышей каждого игрока является непрерывной. Доказано, что игры этого класса имеют решения, однако не разработано практически приемлемых методов их нахождения.
Если функция выигрышей является выпуклой, то такая игра называется выпуклой. Для них разработаны приемлемые методы решения, состоящие в отыскании чистой оптимальной стратегии (определённого числа) для одного игрока и вероятностей применения чистых оптимальных стратегий другого игрока. Такая задача решается сравнительно легко.
Запись матричной игры в виде платёжной матрицы.
В общем виде матричная игра может быть записана следующей платёжной матрицей (рис. 11.).
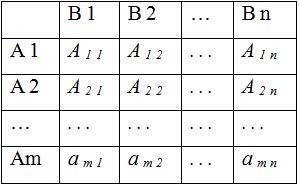
Рис. 11. Общий вид платёжной матрицы матричной игры
где ![]() – названия стратегий игрока 1;
– названия стратегий игрока 1;
![]() – названия стратегий игрока 2;
– названия стратегий игрока 2;
![]() – значения
выигрышей игрока 1 при выборе им i – й стратегии, а игроком 2 – j – й стратегии.
– значения
выигрышей игрока 1 при выборе им i – й стратегии, а игроком 2 – j – й стратегии.
Поскольку данная игра является игрой с нулевой суммой, значение выигрыша для игрока 2 является величиной, противоположенной по знаку значению выигрыша игрока 1.
Понятие о нижней и верхней цене игры. Решение игры в чистых стратегиях.
Каждый из игроков стремится максимизировать свой выигрыш с учётом поведения противодействующего ему игрока. Поэтому для игрока 1 необходимо определить минимальные значения выигрышей в каждой из стратегий, а затем найти максимум из этих значений, то есть определить величину
![]() ,
,
или найти минимальные значения по каждой из строк
платёжной матрицы, а затем определить максимальное из этих значений. Величина ![]() называется максимином матрицы или нижней
ценой игры.
называется максимином матрицы или нижней
ценой игры.
Величина выигрыша игрока 1 равна, по определению матричной игры, величине проигрыша игрока 2. Поэтому для игрока 2 необходимо определить значение
![]() .
.
Или найти максимальные значения по каждому из столбцов
платёжной матрицы, а затем определить минимальное из этих значений. Величина ![]() называется минимаксом матрицы или верхней
ценой игры.
называется минимаксом матрицы или верхней
ценой игры.
В случае, если значения ![]() и
и
![]() не совпадают, при сохранении правил игры
(коэффициентов
не совпадают, при сохранении правил игры
(коэффициентов ![]() ) в длительной
перспективе, выбор стратегий каждым из игроков оказывается неустойчивым.
Устойчивость он приобретает лишь при равенстве
) в длительной
перспективе, выбор стратегий каждым из игроков оказывается неустойчивым.
Устойчивость он приобретает лишь при равенстве ![]() .
В этом случае говорят, что игра имеет решение в чистых стратегиях, а
стратегии, в которых достигается V -
оптимальными чистыми стратегиями. Величина V называется чистой
ценой игры.
.
В этом случае говорят, что игра имеет решение в чистых стратегиях, а
стратегии, в которых достигается V -
оптимальными чистыми стратегиями. Величина V называется чистой
ценой игры.
Например, в матрице (рис. 12) существует решение в чистых стратегиях. При этом для игрока 1 оптимальной чистой стратегией будет стратегия A1, а для игрока 2 – стратегия B4.
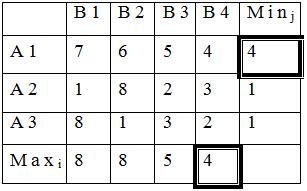
Рис. 12. Платёжная матрица, в которой существует решение в чистых стратегиях
В матрице (рис. 13) решения в чистых стратегиях не существует, так как нижняя цена игры достигается в стратегии A1 и её значение равно 2, в то время как верхняя цена игры достигается в стратегии B4 и её значение равно 3.
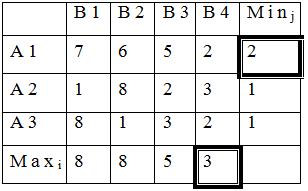
Рис. 13. Платёжная матрица, в которой не существует решения в чистых стратегиях
Уменьшение порядка платёжной матрицы.
Порядок платёжной матрицы (количество строк и столбцов) может быть уменьшен за счёт исключения доминируемых и дублирующих стратегий.
Стратегия ![]() называется доминируемой
стратегией
называется доминируемой
стратегией ![]() , если при любом варианте
поведения противодействующего игрока выполняется соотношение
, если при любом варианте
поведения противодействующего игрока выполняется соотношение
![]() ,
,
где ![]() и
и ![]() - значения выигрышей при выборе игроком,
соответственно, стратегий
- значения выигрышей при выборе игроком,
соответственно, стратегий ![]() и
и ![]() .
.
В случае, если выполняется соотношение
![]() ,
,
стратегия ![]() называется
дублирующей по отношению к стратегии
называется
дублирующей по отношению к стратегии ![]() .
.
Например, в матрице
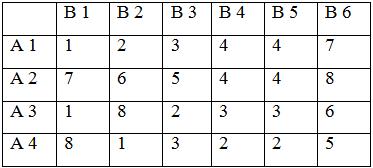
Рис. 14. Платёжная матрица с доминируемыми и дублирующими стратегиями
Стратегия A1 является доминируемой по отношению к стратегии A2, стратегия B6 является доминируемой по отношению к стратегиям B3, B4 и B5, а стратегия B5 является дублирующей по отношению к стратегии B4. Данные стратегии не будут выбраны игроками, так как являются заведомо проигрышными и удаление этих стратегий из платёжной матрицы не повлияет на определение нижней и верхней цены игры, описанной данной матрицей.
Множество недоминируемых стратегий, полученных после уменьшения размерности платёжной матрицы, называется ещё множеством Парето (по имени итальянского экономиста Вильфредо Парето, занимавшегося исследованиями в данной области).
Пример решения матричной игры в чистых стратегиях.
Рассмотрим пример решения матричной игры в чистых стратегиях, в условиях реальной экономики, в ситуации борьбы двух предприятий за рынок продукции региона.
Задача.
Два предприятия производят продукцию и поставляют её на рынок региона. Они являются единственными поставщиками продукции в регион, поэтому полностью определяют рынок данной продукции в регионе.
Каждое из предприятий имеет возможность производить продукцию с применением одной из трёх различных технологий. В зависимости от качества продукции, произведённой по каждой технологии, предприятия могут установить цену единицы продукции на уровне 10, 6 и 2 денежных единиц соответственно. При этом предприятия имеют различные затраты на производство единицы продукции.
Таблица 22.
Затраты на единицу продукции, произведенной на предприятиях региона (д.е.).
|
Технология |
Цена реализации единицы продукции, д.е. |
Полная себестоимость единицы продукции, д.е. |
|
|
Предприятие 1 |
Предприятие 2 |
||
|
I |
10 |
5 |
8 |
|
II |
6 |
3 |
4 |
|
III |
2 |
1.5 |
1 |
В результате маркетингового исследования рынка продукции региона была определена функция спроса на продукцию:
![]() ,
,
где Y – количество продукции, которое приобретёт население региона (тыс. ед.), а X – средняя цена продукции предприятий, д.е.
Данные о спросе на продукцию в зависимости от цен реализации приведены в таблице.
Таблица 23.
Спрос на продукцию в регионе, тыс. ед.
|
Цена реализации 1 ед. продукции, д.е. |
Средняя цена реализации 1 ед. продукции, д.е. |
Спрос на продукцию, тыс. ед. |
|
|
Предприятие 1 |
Предприятие 2 |
||
|
10 |
10 |
10 |
1 |
|
10 |
6 |
8 |
2 |
|
10 |
2 |
6 |
3 |
|
6 |
10 |
8 |
2 |
|
6 |
6 |
6 |
3 |
|
6 |
2 |
4 |
4 |
|
2 |
10 |
6 |
3 |
|
2 |
6 |
4 |
4 |
|
2 |
2 |
2 |
5 |
Значения Долей продукции предприятия 1, приобретенной населением, зависят от соотношения цен на продукцию предприятия 1 и предприятия 2. В результате маркетингового исследования эта зависимость установлена и значения вычислены.
Таблица 24.
Доля продукции предприятия 1, приобретаемой населением в зависимости от соотношения цен на продукцию
|
Цена реализации 1 ед. продукции, д.е. |
Доля продукции предприятия 1, купленной населением |
|
|
Предприятие 1 |
Предприятие 2 |
|
|
10 |
10 |
0,31 |
|
10 |
6 |
0,33 |
|
10 |
2 |
0,18 |
|
6 |
10 |
0,7 |
|
6 |
6 |
0,3 |
|
6 |
2 |
0,2 |
|
2 |
10 |
0,92 |
|
2 |
6 |
0,85 |
|
2 |
2 |
0,72 |
По условию задачи на рынке региона действует только 2 предприятия. Поэтому долю продукции второго предприятия, приобретённой населением, в зависимости от соотношения цен на продукцию можно определить как единица минус доля первого предприятия.
Стратегиями предприятий в данной задаче являются их решения относительно технологий производства продукции. Эти решения определяют себестоимость и цену реализации единицы продукции. В задаче необходимо определить:
1. Существует ли в данной задаче ситуация равновесия при выборе технологий производства продукции обоими предприятиями?
2. Существуют ли технологии, которые предприятия заведомо не будут выбирать вследствие невыгодности?
3. Сколько продукции будет реализовано в ситуации равновесия? Какое предприятие окажется в выигрышном положении?
Решение задачи.
1. Определим экономический смысл коэффициентов выигрышей в платёжной матрице задачи. Каждое предприятие стремится к максимизации прибыли от производства продукции. Но кроме того, в данном случае предприятия ведут борьбу за рынок продукции в регионе. При этом выигрыш одного предприятия означает проигрыш другого. Такая задача может быть сведена к матричной игре с нулевой суммой. При этом коэффициентами выигрышей будут значения разницы прибыли предприятия 1 и предприятия 2 от производства продукции. В случае, если эта разница положительна, выигрывает предприятие 1, а в случае, если она отрицательна – предприятие 2.
2. Рассчитаем коэффициенты выигрышей платёжной матрицы. Для этого необходимо определить значения прибыли предприятия 1 и предприятия 2 от производства продукции. Прибыль предприятия в данной задаче зависит:
· от цены и себестоимости продукции;
· от количества продукции, приобретаемой населением региона;
· от доли продукции, приобретённой населением у предприятия.
Таким образом, значения разницы прибыли предприятий, соответствующие коэффициентам платёжной матрицы, необходимо определить по формуле (1):
![]() (15),
(15),
где D – значение разницы прибыли от производства продукции предприятия 1 и предприятия 2;
p - доля продукции предприятия 1, приобретаемой населением региона;
S – количество продукции, приобретаемой населением региона;
R1 и R2 - цены реализации единицы продукции предприятиями 1 и 2;
C1 и C2 – полная себестоимость единицы продукции, произведённой на предприятиях 1 и 2.
Вычислим один из коэффициентов платёжной матрицы.
Пусть, например, предприятие 1 принимает решение о производстве продукции в соответствии с технологией III, а предприятие 2 – в соответствии с технологией II. Тогда цена реализации единицы. продукции для предприятия 1 составит 2 д.е. при себестоимости единицы. продукции 1,5 д.е. Для предприятия 2 цена реализации единицы. продукции составит 6 д.е. при себестоимости 4 д.е.
Количество продукции, которое население региона приобретёт при средней цене 4 д.е., равно 4 тыс. ед. Доля продукции, которую население приобретёт у предприятия 1, составит 0,85, а у предприятия 2 – 0,15. Вычислим коэффициент платёжной матрицы a32 по формуле (15):
![]()
где i=3 – номер технологии первого предприятия, а j=2 – номер технологии второго предприятия.
Аналогично вычислим все коэффициенты платёжной матрицы. В платёжной матрице стратегии A1 – A3 – представляют собой решения о технологиях производства продукции предприятием 1, стратегии B1 – B3 – решения о технологиях производства продукции предприятием 2, коэффициенты выигрышей – разницу прибыли предприятия 1 и предприятия 2.
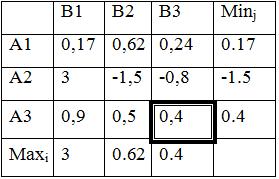
Рис. 15. Платёжная матрица в игре «Борьба двух предприятий за рынок продукции региона»
В данной матрице нет ни доминируемых, ни дублирующих стратегий. Это значит, что для обоих предприятий нет заведомо невыгодных технологий производства продукции. Определим минимальные элементы строк матрицы. Для предприятия 1 каждый из этих элементов имеет значение минимально гарантированного выигрыша при выборе соответствующей стратегии. Минимальные элементы матрицы по строкам имеют значения: 0,17, -1,5, 0,4.
Определим максимальные элементы столбцов матрицы. Для предприятия 2 каждый из этих элементов также имеет значение минимально гарантированного выигрыша при выборе соответствующей стратегии. Максимальные элементы матрицы по столбцам имеют значения: 3, 0,62, 0,4.
Нижняя цена игры в матрице равна 0,4. Верхняя цена игры также равна 0,4. Таким образом, нижняя и верхняя цена игры в матрице совпадают. Это значит, что имеется технология производства продукции, которая является оптимальной для обоих предприятий в условиях данной задачи. Эта технология III, которая соответствует стратегиям A3 предприятия 1 и B3 предприятия 2. Стратегии A3 и B3 – чистые оптимальные стратегии в данной задаче.
Значение разницы прибыли предприятия 1 и предприятия 2 при выборе чистой оптимальной стратегии положительно. Это означает, что предприятие 1 выиграет в данной игре. Выигрыш предприятия 1 составит 0,4 тыс. д.е. При этом на рынке будет реализовано 5 тыс. ед. продукции (реализация равна спросу на продукцию). Оба предприятия установят цену за единицу продукции в 2 д.е. При этом для первого предприятия полная себестоимость единицы продукции составит 1,5 д.е., а для второго – 1 д.е. Предприятие 1 окажется в выигрыше лишь за счёт высокой доли продукции, которую приобретёт у него население.
Понятие о матричных играх со смешанным расширением.
Исследование в матричных играх начинается с нахождения её чистой цены. Если матричная игра имеет решение в чистых стратегиях, то нахождением чистой цены заканчивается исследование игры. Если же в игре нет решения в чистых стратегиях, то можно найти нижнюю и верхнюю цены этой игры, которые указывают, что игрок 1 не должен надеяться на выигрыш больший, чем верхняя цена игры, и может быть уверен в получении выигрыша не меньше нижней цены игры. Улучшение решений матричных игр следует искать в использовании секретности применения чистых стратегий и возможности многократного повторения игр в виде партии. Этот результат достигается путём применения чистых стратегий случайно, с определённой вероятностью.
Определение. Смешанной стратегией игрока называется полный набор чистых стратегий, применённых в соответствии с установленным распределением вероятностей. Матричная игра, решаемая с использованием смешанных стратегий, называется игрой со смешанным расширением.
Стратегии, применённые с вероятностью, отличной от нуля, называются активными стратегиями.
![]()
При этом условии величина V называется ценой игры.
Кроме того, доказано, что, если один из игроков придерживается своей оптимальной смешанной стратегии, то выигрыш остаётся неизменным и равным цене игры V, независимо от того, каких стратегий придерживается другой игрок, если только он не выходит за пределы своих активных стратегий. Поэтому, для достижения наибольшего гарантированного выигрыша второму игроку также необходимо придерживаться своей оптимальной смешанной стратегии.
Решение матричных игр со смешанным расширением методами линейного программирования.
Решение матричной игры со смешанным расширением – это определение оптимальных смешанных стратегий, то есть нахождение таких значений вероятностей выбора чистых стратегий для обоих игроков, при которых они достигают наибольшего выигрыша.
Для матричной игры, платёжная матрица которой показана
на рис. 15, ![]() , определим такие
значения вероятностей выбора стратегий для игрока 1
, определим такие
значения вероятностей выбора стратегий для игрока 1 ![]() и
для игрока 2
и
для игрока 2 ![]() , при которых игроки достигали бы
своего максимально гарантированного выигрыша.
, при которых игроки достигали бы
своего максимально гарантированного выигрыша.
Если один из игроков придерживается своей оптимальной стратегии, то, по условию задачи, его выигрыш не может быть меньше цены игры V. Поэтому данная задача может быть представлена для игроков в виде следующих систем линейных неравенств:
Для первого игрока:
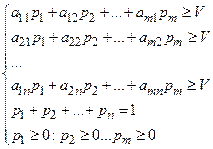
Для второго игрока:
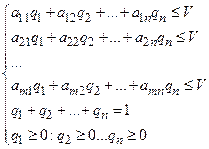
Чтобы определить значение V, разделим обе части каждого из уравнений на V. Величину pi/V обозначим через xi, а qj/V – через yj.
Для игрока 1 получим следующую систему неравенств, из которой найдём значение 1/v:
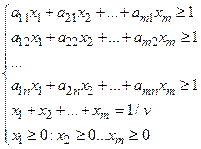
Для игрока 1 необходимо найти максимальную цену игры (V). Следовательно, значение 1/V должно стремиться к минимуму.
Целевая функция задачи будет иметь следующий вид:
![]()
Для игрока 2 получим следующую систему неравенств, из которой найдём значение 1/v:
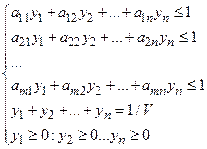
Для игрока 2 необходимо найти минимальную цену игры (V). Следовательно, значение 1/V должно стремиться к максимуму.
Целевая функция задачи будет иметь следующий вид:
![]()
Все переменные в данных системах линейных неравенств
должны быть неотрицательными:![]() . Значения
. Значения ![]() и
и ![]() не
могут быть отрицательными, так как являются значениями вероятностей выбора
стратегий игроков. Поэтому необходимо, чтобы значение цены игры V не
было отрицательным. Цена игры вычисляется на основе коэффициентов выигрышей
платёжной матрицы. Поэтому, для того, чтобы гарантировать условие не
отрицательности для всех переменных, необходимо, чтобы все коэффициенты матрицы
были неотрицательными. Этого можно добиться, прибавив перед началом решения
задачи к каждому коэффициенту матрицы число K,
соответствующее модулю наименьшего отрицательного коэффициента матрицы. Тогда в
ходе решения задачи будет определена не цена игры, а величина
не
могут быть отрицательными, так как являются значениями вероятностей выбора
стратегий игроков. Поэтому необходимо, чтобы значение цены игры V не
было отрицательным. Цена игры вычисляется на основе коэффициентов выигрышей
платёжной матрицы. Поэтому, для того, чтобы гарантировать условие не
отрицательности для всех переменных, необходимо, чтобы все коэффициенты матрицы
были неотрицательными. Этого можно добиться, прибавив перед началом решения
задачи к каждому коэффициенту матрицы число K,
соответствующее модулю наименьшего отрицательного коэффициента матрицы. Тогда в
ходе решения задачи будет определена не цена игры, а величина ![]() .
.
Для решения задач линейного программирования используется симплекс-метод.
В результате решения определяются значения целевых
функций (для обоих игроков эти значения совпадают), а также значения переменных
![]() и
и ![]() .
.
Величина ![]() определяется по
формуле:
определяется по
формуле: ![]()
Значения вероятностей выбора стратегий определяются:
для игрока ![]() : для игрока
: для игрока ![]() .
.
Для определения цены игры V из величины ![]() необходимо вычесть число K.
необходимо вычесть число K.
Пример решения матричной игры со смешанным расширением.
Рассмотрим пример решения матричной игры со смешанным расширением. Платёжную матрицу игры составим на основе исходных данных рассмотренной выше задачи, заменив лишь значения долей продукции предприятия 1, приобретаемой населением в зависимости от соотношений цен (табл. 25).
Таблица 25.
Доля продукции предприятия 1, приобретаемой населением в зависимости от соотношения цен на продукцию
|
Цена реализации 1 ед. продукции, д.е. |
Доля продукции предприятия 1, купленной населением |
|
|
Предп. 1 |
Предп. 2 |
|
|
10 |
10 |
0,31 |
|
10 |
6 |
0,33 |
|
10 |
2 |
0,18 |
|
6 |
10 |
0,7 |
|
6 |
6 |
0,3 |
|
6 |
2 |
0,2 |
|
2 |
10 |
0,9 |
|
2 |
6 |
0,85 |
|
2 |
2 |
0,69 |
Применив к исходным данным задачи формулу (15) определения разницы прибыли от производства продукции, получим следующую платёжную матрицу (рис. 16)
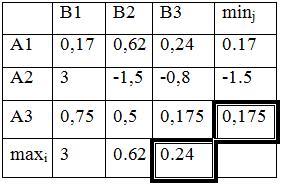
Рис. 16. Платёжная матрица в игре «Борьба двух предприятий за рынок продукции региона»
В данной матрице (рис. 16) нет доминируемых или дублирующих стратегий. Нижняя цена игры равна 0,175, а верхняя цена игры равна 0,24. Нижняя цена игры не равна верхней. Поэтому решения в чистых стратегиях не существует и для каждого из игроков необходимо найти оптимальную смешанную стратегию.
Решение задачи.
1. В данной матрице имеются отрицательные коэффициенты. Для соблюдения условия неотрицательности в задачах линейного программирования прибавим к каждому коэффициенту матрицы модуль минимального отрицательного коэффициента. В данной задаче к каждому коэффициенту матрицы необходимо прибавить число 1,5 – значение модуля наименьшего отрицательного элемента матрицы. Получим платёжную матрицу, преобразованную для выполнения условия не отрицательности (рис. 17).
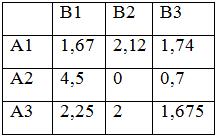
Рис. 17. Платёжная матрица, преобразованная для выполнения условия неотрицательности
2. Опишем задачу линейного программирования для каждого игрока в виде системы линейных неравенств:
Для игрока 1:
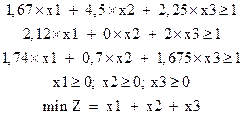
Для игрока 2:
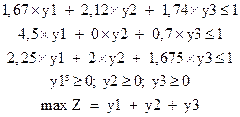
3. Решим обе задачи с использованием симплекс-метода, применяя программный комплекс «Линейная оптимизация».
В результате решения задачи получим следующие значения целевой функции и переменных:
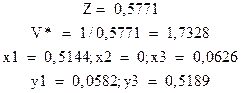
4. Для определения значений вероятностей выбора стратегий игроков 1 и 2 умножим значения переменных на V*.
![]()
5. Определим значение цены игры. Для этого из величины V* вычтем 1,5 (значение модуля наименьшего отрицательного элемента).
![]()
Таким образом, в данной игре выиграет предприятие 1 (значение V > 0). Для достижения своей оптимальной стратегии (получения максимального математического ожидания гарантированного выигрыша) предприятие 1 должно выбирать технологию 1 с вероятностью 0,8914, а технологию 3 – с вероятностью 0,1083. Предприятие 2, соответственно, должно выбирать технологию 1 с вероятностью 0,1008, а технологию 3 – с вероятностью 0,8991. Значение математического ожидания выигрыша предприятия 1 составит 0,2328 тыс. д.е.
Кластеризация – объединение в группы схожих объектов – является одной из фундаментальных задач в области анализа данных и Data Mining. Список прикладных областей, где она применяется, широк: сегментация изображений, маркетинг, борьба с мошенничеством, прогнозирование, анализ текстов и многие другие. На современном этапе кластеризация часто выступает первым шагом при анализе данных. После выделения схожих групп применяются другие методы, для каждой группы строится отдельная модель.
Задачу кластеризации в том или ином виде формулировали в таких научных направлениях, как статистика, распознавание образов, оптимизация, машинное обучение. Отсюда многообразие синонимов понятию кластер – класс, таксон, сгущение.
На сегодняшний момент число методов разбиения групп объектов на кластеры довольно велико – несколько десятков алгоритмов и еще больше их модификаций. Однако нас интересуют алгоритмы кластеризации с точки зрения их применения в Data Mining.
Кластеризация в Data Mining.
Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель на всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой их них отдельную стратегию.
Очень часто данные, с которыми сталкивается технология Data Mining, имеют следующие важные особенности:
· высокая размерность (тысячи полей) и большой объем (сотни тысяч и миллионы записей) таблиц баз данных и хранилищ данных (сверхбольшие базы данных);
· наборы данных содержат большое количество числовых и категорийных атрибутов.
Все атрибуты, или признаки объектов делятся на числовые (numerical) и категорийные (categorical). Числовые атрибуты – это такие, которые могут быть упорядочены в пространстве, соответственно категорийные – которое не могут быть упорядочены. Например, атрибут «возраст» – числовой, а «цвет» – категорийный. Приписывание атрибутам значений происходит во время измерений выбранным типом шкалы, а это, вообще говоря, представляет собой отдельную задачу.
Большинство алгоритмов кластеризации предполагают сравнение объектов между собой на основе некоторой меры близости (сходства). Мерой близости называется величина, имеющая предел и возрастающая с увеличением близости объектов. Меры сходства «изобретаются» по специальным правилам, а выбор конкретных мер зависит от задачи, а также от шкалы измерений. В качестве меры близости для числовых атрибутов очень часто используется евклидово расстояние, вычисляемое по формуле:
![]()
Для категорийных атрибутов распространена мера
сходства Чекановского-Серенсена и Жаккара ![]() .
.
Потребность в обработке больших массивов данных в Data Mining привела к формулированию требований, которым, по возможности, должен удовлетворять алгоритм кластеризации. Рассмотрим их:
· Минимально возможное количество проходов по базе данных.
· Работа в ограниченном объеме оперативной памяти компьютера.
· Работу алгоритма можно прервать с сохранением промежуточных результатов, чтобы продолжить вычисления позже.
· Алгоритм должен работать, когда объекты из базы данных могут извлекаться только в режиме однонаправленного курсора (т.е. в режиме навигации по записям).
Алгоритм, удовлетворяющий данным требованиям (особенно второму), будем называть масштабируемым (scalable). Масштабируемость – важнейшее свойство алгоритма, зависящее от его вычислительной сложности и программной реализации. Имеется и более емкое определение. Алгоритм называют масштабируемым, если при неизменной емкости оперативной памяти с увеличением числа записей в базе данных время его работы растет линейно.
Но далеко не всегда требуется обрабатывать сверхбольшие массивы данных. Поэтому на заре становления теории кластерного анализа вопросам масштабируемости алгоритмов внимания практически не уделялось. Предполагалось, что все обрабатываемые данные будут умещаться в оперативной памяти, главный упор всегда делался на улучшение качества кластеризации. Трудно соблюсти баланс между высоким качеством кластеризации и масштабируемостью. Поэтому в идеале в арсенале Data Mining должны присутствовать как эффективные алгоритмы кластеризации микромассивов (microarrays), так и масштабируемые для обработки сверхбольших баз данных (large databases).
Алгоритм Кохонена.
Алгоритм Кохонена относится к наиболее
старым алгоритмам обучения сетей с самоорганизацией на основе конкуренции, и в
настоящее время существуют различные его версии. В классическом алгоритме
Кохонена сеть инициализируется путем приписывания нейронам определенных позиций
в пространстве и связывания их с соседями на постоянной основе. Такая сеть
называется самоорганизующейся картой признаков (сеть SOFM - Self-Organizing
Feature Map). В момент выбора победителя уточняются не только его веса, но
также и веса его соседей, находящихся в ближайшей окрестности. Таким образом,
нейрон-победитель подвергается адаптации вместе со своими соседями. В
классическом алгоритме Кохонена функция соседства ![]() определяется
в виде
определяется
в виде
![]()
В этом выражении ![]() обозначает
эвклидово расстояние между векторами весов нейрона-победителя
обозначает
эвклидово расстояние между векторами весов нейрона-победителя ![]() и
и ![]() -го
нейрона. Коэффициент
-го
нейрона. Коэффициент ![]() выступает в роли уровня соседства,
его значение уменьшается в процессе обучения до нуля. Соседство такого рода
называется прямоугольным.
выступает в роли уровня соседства,
его значение уменьшается в процессе обучения до нуля. Соседство такого рода
называется прямоугольным.
Другой тип соседства, часто применяемый в
картах Кохонена, - это соседство гауссовского типа, при котором функция ![]() задается формулой
задается формулой
![]() .
.
Степень адаптации нейронов-соседей определяется не
только евклидовым расстоянием между ![]() -м нейроном и
победителем (
-м нейроном и
победителем ( ![]() -м нейроном), но также и уровнем
соседства
-м нейроном), но также и уровнем
соседства ![]() В отличие от соседства
прямоугольного типа, где каждый нейрон, находящийся в окрестности победителя,
адаптировался в равной степени, при соседстве гауссовского типа уровень
адаптации различен и зависит от значения функции Гаусса. Как правило,
гауссовское соседство дает лучшие результаты обучения и обеспечивает лучшую
организацию сети, чем прямоугольное соседство.
В отличие от соседства
прямоугольного типа, где каждый нейрон, находящийся в окрестности победителя,
адаптировался в равной степени, при соседстве гауссовского типа уровень
адаптации различен и зависит от значения функции Гаусса. Как правило,
гауссовское соседство дает лучшие результаты обучения и обеспечивает лучшую
организацию сети, чем прямоугольное соседство.
Самоорганизующаяся карта признаков проходит два этапа обучения. На первом этапе элементы упорядочиваются так, чтобы отражать пространство входных элементов, а на втором происходит уточнение их позиций. Как правило, процесс представляется визуально путем использования двумерных данных и построения соответствующей поверхности. Например, входные векторы выбираются случайным образом на основе однородного распределения в некотором квадрате, и начинается обучение карты. В определенные моменты в ходе обучения строятся изображения карты путем использования соответствия, показанного на рис. 18. Элементы соединяются линиями, чтобы показать их относительное размещение. Сначала карта выглядит сильно «измятой», но постепенно в ходе обучения она разворачивается и расправляется. Конечным результатом обучения является карта, покрывающая все входное пространство и являющаяся достаточно регулярной (т.е. элементы оказываются распределенными почти равномерно). Для примера была рассмотрена карта с топологией квадрата из 49 элементов, и для 250 точек данных, взятых из единичного квадрата, было проведено ее обучение, которое начиналось со случайного набора весовых значений, задающих размещение кластерных элементов в центре входного пространства, как показано на рис. 18. На рис. 19 и 20 иллюстрируется процесс разворачивания карты с течением времени. Как и для других типов сетей, в данном случае результат обучения зависит от учебных данных и выбора параметров обучения.
Рис. 18. Весовые векторы инициализируются случайными значениями из диапазона 0.4-0.6
Рис. 19. Карта по прошествии 20 итераций
Рис. 20. Карта незадолго до окончания обучения. Элементы теперь упорядочены, и карта станет еще более регулярной по окончании финальной фазы сходимости
k-means (метод k-средних) – наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математиком Гуго Штейнгаузом и почти одновременно Стюартом Ллойдом. Особую популярность приобрёл после работы Маккуина.
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
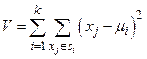
где ![]() – число
кластеров;
– число
кластеров;
![]() – полученные кластеры;
– полученные кластеры;
![]() и
и ![]() – центры
масс векторов
– центры
масс векторов ![]() .
.
По аналогии с методом главных компонент центры кластеров называются также главными точками, а сам метод называется методом главных точек и включается в общую теорию главных объектов, обеспечивающих наилучшую аппроксимацию данных.
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008
2. Вентцель Е.С. Исследование операция. - М.: Советское радио, 1972.
3. Воробьев Н.Н. Теория игр для экономистов-кибернетиков. - М.: Наука, 1985.
4. Горелик В.А., Кононенко А.Ф. Теоретико-игровые модели принятия решений в эколого-экономических системах. - М.: Радио и связь, 1982/
5. Давыдов Э.Г. Исследование операций. - М.: Высшая школа, 1990.
6. Лапшин К.А., Светлов Н.М. Прогграммный комплекс «Линейная оптимизация» - методические указания для студентов экономического факультета. - М.: МСХА, 1994.
7. Economists. Princeton University press, Princeton, New Gersey, 1992.
Цель: Рассмотрение инструментария «Дерево решений».
Задачи:
· Сформулировать общие принципы работы деревьев решений.
· Охарактеризовать типы решаемых задач.
· Рассмотреть этапы построения деревьев решений.
Вопросы темы:
1. Дерево решений, как инструмент принятия решений.
2. Деревья решений - общие принципы работы.
3. Дерево решений и типы решаемых задач.
4. Этапы построения деревьев решений.
Своевременная разработка и принятие правильного решения – главные задачи работы управленческого персонала любой организации. Непродуманное решение может дорого стоить компании. На практике результат одного решения заставляет нас принимать следующее решение и т. д. Когда нужно принять несколько решений в условиях неопределенности, когда каждое решение зависит от исхода предыдущего решения или исходов испытаний, то применяют схему, называемую деревом решений.
Дерево решений – это графическое изображение процесса принятия решений, в котором отражены альтернативные решения, альтернативные состояния среды, соответствующие вероятности и выигрыши для любых комбинаций альтернатив и состояний среды.
Рисуют деревья слева направо. Места, где принимаются решения, обозначают квадратами □, места появления исходов – кругами ○, возможные решения – пунктирными линиями --------, возможные исходы – сплошными линиями ––.
Для каждой альтернативы мы считаем ожидаемую стоимостную оценку (EMV) – максимальную из сумм оценок выигрышей, умноженных на вероятность реализации выигрышей, для всех возможных вариантов.
Пример 1 (по материалам сайта «Экономика и финансы»). Главному инженеру компании надо решить, монтировать или нет новую производственную линию, использующую новейшую технологию. Если новая линия будет работать безотказно, компания получит прибыль 200 млн. рублей. Если же она откажет, компания может потерять 150 млн. рублей. По оценкам главного инженера, существует 60% шансов, что новая производственная линия откажет. Можно создать экспериментальную установку, а затем уже решать, монтировать или нет производственную линию. Эксперимент обойдется в 10 млн. рублей. Главный инженер считает, что существует 50% шансов, что экспериментальная установка будет работать. Если экспериментальная установка будет работать, то 90% шансов зато, что смонтированная производственная линия также будет работать. Если же экспериментальная установка не будет работать, то только 20% шансов за то, что производственная линия заработает. Следует ли строить экспериментальную установку? Следует ли монтировать производственную линию? Какова ожидаемая стоимостная оценка наилучшего решения?
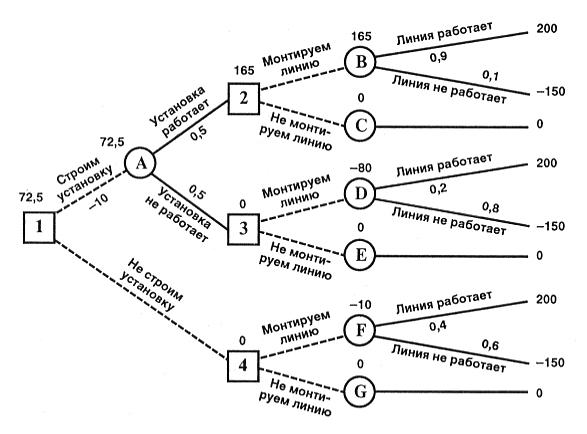
Рис. 21. Дерево решений
В узле F возможны исходы «линия работает»
с вероятностью 0,4 (что приносит прибыль 200) и «линия не работает» с
вероятностью 0,6 (что приносит убыток -150) => оценка узла F. ![]() . Это число мы пишем над узлом F.
. Это число мы пишем над узлом F.
![]() .
.
В узле 4 мы выбираем между решением «монтируем
линию» (оценка этого решения ![]() ) и решением «не
монтируем линию» (оценка этого решения
) и решением «не
монтируем линию» (оценка этого решения ![]() ):
):
![]() .
.
Эту оценку мы пишем над узлом 4, а решение «монтируем линию» отбрасываем и зачеркиваем.
Аналогично:
![]() .
.
![]() .
.
![]() .
.
Поэтому в узле 2 отбрасываем возможное решение «не монтируем линию».
![]()
![]() .
.
![]() .
.
Поэтому в узле 3 отбрасываем возможное решение «монтируем линию».
![]() .
.
![]() .
.
Поэтому в узле 1 отбрасываем возможное решение «не строим установку».
Ожидаемая стоимостная оценка наилучшего решения равна 72,5 млн. рублей. Строим установку. Если установка работает, то монтируем линию. Если установка не работает, то линию монтировать не надо.
Пример 2 (по материалам сайта «Экономика и финансы»). Компания рассматривает вопрос о строительстве завода. Возможны три варианта действий.
А) Построить большой завод стоимостью M1 = 700 тысяч долларов. При этом варианте возможны большой спрос (годовой доход в размере R1 = 280 тысяч долларов в течение следующих 5 лет) с вероятностью p1 = 0,8 и низкий спрос (ежегодные убытки R2 = 80 тысяч долларов) с вероятностью р2 = 0,2.
Б) Построить маленький завод стоимостью М2 = 300 тысяч долларов. При этом варианте возможны большой спрос (годовой доход в размере T1= 180 тысяч долларов в течение следующих 5 лет) с вероятностью p1 = 0,8 и низкий спрос (ежегодные убытки Т2 = 55 тысяч долларов) с вероятностью р2 = 0,2.
В) Отложить строительство завода на один год для сбора дополнительной информации, которая может быть позитивной или негативной с вероятностью p 3 = 0,7 и p4 = 0,3 соответственно. В случае позитивной информации можно построить заводы по указанным выше расценкам, а вероятности большого и низкого спроса меняются на p 5 = 0,9 и р6 = 0,1 соответственно. Доходы на последующие четыре года остаются прежними. В случае негативной информации компания заводы строить не будет.
Все расчеты выражены в текущих ценах и не должны дисконтироваться. Нарисовав дерево решений, определим наиболее эффективную последовательность действий, основываясь на ожидаемых доходах.
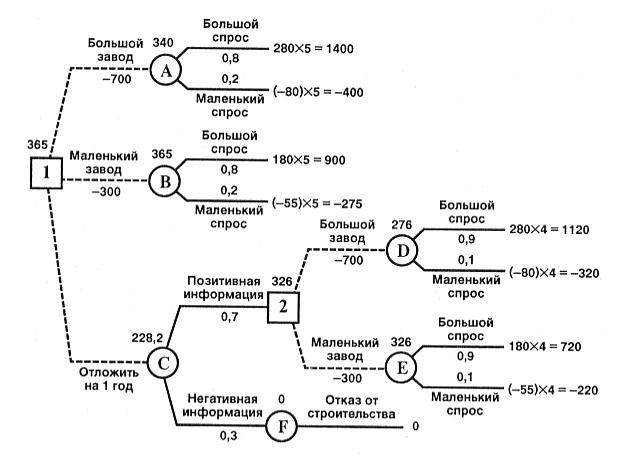
Рис. 22
Ожидаемая стоимостная оценка узла А равна
![]() .
.
![]() .
.
![]() .
.
![]() .
.
![]() .
.
Поэтому в узле 2 отбрасываем возможное решение «большой завод».
![]() .
.
![]() .
.
Поэтому в узле 1 выбираем решение «маленький завод». Исследование проводить не нужно. Строим маленький завод. Ожидаемая стоимостная оценка этого наилучшего решения равна 365 тысяч долларов.
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает, что породило спрос на методы автоматического исследования (анализа) данных, который с каждым годом постоянно увеличивается.
Деревья решений – один из таких методов автоматического анализа данных. Первые идеи создания деревьев решений восходят к работам Ховленда (Hoveland) и Ханта(Hunt) конца 50-х годов XX века. Однако, основополагающей работой, давшей импульс для развития этого направления, явилась книга Ханта (Hunt, E.B.), Мэрина (Marin J.) и Стоуна (Stone, P.J) «Experiments in Induction», увидевшая свет в 1966г.
Таблица 26.
Терминология
|
Название |
Описание |
|
Объект |
Пример, шаблон, наблюдение |
|
Атрибут |
Признак, независимая переменная, свойство |
|
Метка класcа |
Зависимая переменная, целевая переменная, признак определяющий класс объекта |
|
Узел |
Внутренний узел дерева, узел проверки |
|
Лист |
Конечный узел дерева, узел решения |
|
Проверка (test) |
Условие в узле |
Деревья решений – это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение.
Под правилом понимается логическая конструкция, представленная в виде «если... то...».Область применения деревья решений в настоящее время широка, но все задачи, решаемые этим аппаратом могут быть объединены в следующие три класса:
· Описание данных: Деревья решений позволяют хранить информацию о данных в компактной форме, вместо них мы можем хранить дерево решений, которое содержит точное описание объектов.
· Классификация: Деревья решений отлично справляются с задачами классификации, т.е. отнесения объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения.
· Регрессия: Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых(входных) переменных. Например, к этому классу относятся задачи численного прогнозирования(предсказания значений целевой переменной).
Как построить дерево решений?
Пусть нам задано некоторое обучающее множество T, содержащее объекты (примеры), каждый из которых характеризуется m атрибутами (атрибутами), причем один из них указывает на принадлежность объекта к определенному классу.
Идею построения деревьев решений из множества T, впервые высказанную Хантом, приведем по Р. Куинлену (R. Quinlan).
Пусть через ![]() обозначены классы(значения метки класса),
тогда существуют 3 ситуации:
обозначены классы(значения метки класса),
тогда существуют 3 ситуации:
1. Множество T содержит один или более примеров,
относящихся к одному классу ![]() . Тогда дерево
решений для Т – это лист, определяющий класс
. Тогда дерево
решений для Т – это лист, определяющий класс ![]() .
.
2. Множество T не содержит ни одного примера, т.е. пустое множество. Тогда это снова лист, и класс, ассоциированный с листом, выбирается из другого множества отличного от T, скажем, из множества, ассоциированного с родителем.
3. Множество T содержит примеры, относящиеся к разным
классам. В этом случае следует разбить множество T на некоторые подмножества.
Для этого выбирается один из признаков, имеющий два и более отличных друг от
друга значений ![]() . T разбивается на
подмножества
. T разбивается на
подмножества ![]() , где каждое подмножество
, где каждое подмножество ![]() содержит все примеры, имеющие значение
содержит все примеры, имеющие значение ![]() для выбранного признака. Это процедура
будет рекурсивно продолжаться до тех пор, пока конечное множество не
будет состоять из примеров, относящихся к одному и тому же классу.
для выбранного признака. Это процедура
будет рекурсивно продолжаться до тех пор, пока конечное множество не
будет состоять из примеров, относящихся к одному и тому же классу.
Вышеописанная процедура лежит в основе многих современных алгоритмов построения деревьев решений, этот метод известен еще под названием разделения и захвата (divide and conquer). Очевидно, что при использовании данной методики, построение дерева решений будет происходит сверху вниз.
Поскольку все объекты были заранее отнесены к известным нам классам, такой процесс построения дерева решений называется обучением с учителем (supervised learning). Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction).
На сегодняшний день существует значительное число алгоритмов, реализующих деревья решений CART, C4.5, NewId, ITrule, CHAID, CN2 и т.д. Но наибольшее распространение и популярность получили следующие два:
· CART (Classification and Regression Tree) – это алгоритм построения бинарного дерева решений – дихотомической классификационной модели. Каждый узел дерева при разбиении имеет только двух потомков. Как видно из названия алгоритма, решает задачи классификации и регрессии.
· C4.5 – алгоритм построения дерева решений, количество потомков у узла не ограничено. Не умеет работать с непрерывным целевым полем, поэтому решает только задачи классификации.
Большинство из известных алгоритмов являются «жадными алгоритмами». Если один раз был выбран атрибут, и по нему было произведено разбиение на подмножества, то алгоритм не может вернуться назад и выбрать другой атрибут, который дал бы лучшее разбиение. И поэтому на этапе построения нельзя сказать даст ли выбранный атрибут, в конечном итоге, оптимальное разбиение.
При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия атрибута, по которому пойдет разбиение, остановки обучения и отсечения ветвей. Рассмотрим все эти вопросы по порядку.
Правило разбиения. Каким образом следует выбрать признак?
Для построения дерева на каждом внутреннем узле необходимо найти такое условие (проверку), которое бы разбивало множество, ассоциированное с этим узлом на подмножества. В качестве такой проверки должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов («примесей») в каждом из этих множеств было как можно меньше.
Были разработаны различные критерии, но мы рассмотрим только два из них:
Теоретико-информационный критерий.
Алгоритм C4.5, усовершенствованная версия алгоритма ID3 (Iterative Dichotomizer), использует теоретико-информационный подход. Для выбора наиболее подходящего атрибута, предлагается следующий критерий:
![]() (16)
(16)
где, Info(T) – энтропия множества T, а
 (17)
(17)
Множества ![]() получены при
разбиении исходного множества T по проверке X. Выбирается атрибут, дающий
максимальное значение по критерию.
получены при
разбиении исходного множества T по проверке X. Выбирается атрибут, дающий
максимальное значение по критерию.
Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме вышеупомянутого алгоритма C4.5, есть еще целый класс алгоритмов, которые используют этот критерий выбора атрибута.
Статистический критерий.
Алгоритм CART использует так называемый индекс Gini (в честь итальянского экономиста Corrado Gini), который оценивает «расстояние» между распределениями классов.
![]() (18)
(18)
где c – текущий узел, а ![]() –
вероятность класса j в узле c.
–
вероятность класса j в узле c.
CART был предложен Л.Брейманом (L.Breiman) и др.
Правило остановки. Разбивать дальше узел или отметить его как лист?
В дополнение к основному методу построения деревьев решений были предложены следующие правила:
· Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая «ранняя остановка» (prepruning). В конечном счете «ранняя остановка» процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна. Признанные авторитеты в этой области Л.Брейман и Р. Куинлен советуют буквально следующее: «Вместо остановки используйте отсечение».
· Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение.
· Разбиение должно быть нетривиальным, т.е. получившиеся в результате узлы должны содержать не менее заданного количества примеров.
Этот список эвристических правил можно продолжить, но на сегодняшний день не существует такого, которое бы имело большую практическую ценность. К этому вопросу следует подходить осторожно, так как многие из них применимы в каких-то частных случаях.
Правило отсечения. Каким образом ветви дерева должны отсекаться?
Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые «переполнены данными», имеют много узлов и ветвей. Такие «ветвистые» деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из все меньшего количества объектов.
Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и в целях анализа данных такое правило практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки. И тут возникает вопрос: а не построить ли все возможные варианты деревьев, соответствующие обучающему множеству, и из них выбрать дерево с наименьшей глубиной? К сожалению, это задача является NP-полной, это было показано Л. Хайфилем (L. Hyafill) и Р. Ривестом (R. Rivest), и, как известно, этот класс задач не имеет эффективных методов решения.
Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning).
Пусть под точностью (распознавания) дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных. Предположим, что нам известен способ оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило:
· построить дерево;
· отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки.
В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом.
Хотя отсечение не является панацеей, но в большинстве практических задач дает хорошие результаты, что позволяет говорить о правомерности использования подобной методики.
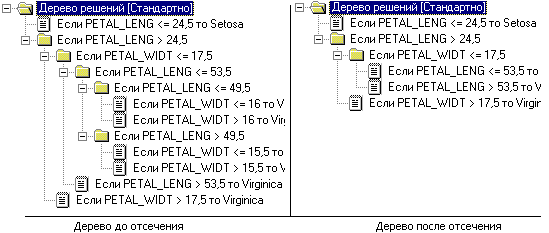
Рис. 23
Правила.
Иногда даже усеченные деревья могут быть все еще сложны для восприятия. В таком случае, можно прибегнуть к методике извлечения правил из дерева с последующим созданием наборов правил, описывающих классы.
Для извлечения правил необходимо исследовать все пути от корня до каждого листа дерева. Каждый такой путь даст правило, где условиями будут являться проверки из узлов встретившихся на пути.
Преимущества использования деревьев решений.
Рассмотрев основные проблемы, возникающие при построении деревьев, было бы несправедливо не упомянуть об их достоинствах:
· быстрый процесс обучения;
· генерация правил в областях, где эксперту трудно формализовать свои знания;
· извлечение правил на естественном языке;
· интуитивно понятная классификационная модель;
· высокая точность прогноза, сопоставимая с другими методами (статистика, нейронные сети);
· построение непараметрических моделей.
В силу этих и многих других причин, методология деревьев решений является важным инструментом в работе каждого специалиста, занимающегося анализом данных, вне зависимости от того практик он или теоретик.
Области применения деревьев решений.
Деревья решений являются прекрасным инструментом в системах поддержки принятия решений, интеллектуального анализа данных (data mining).
В состав многих пакетов, предназначенных для интеллектуального анализа данных, уже включены методы построения деревьев решений. В областях, где высока цена ошибки, они послужат отличным подспорьем аналитика или руководителя.
Деревья решений успешно применяются для решения практических задач в следующих областях:
· Банковское дело. Оценка кредитоспособности клиентов банка при выдаче кредитов.
· Промышленность. Контроль за качеством продукции (выявление дефектов), испытания без разрушений (например проверка качества сварки) и т.д.
· Медицина. Диагностика различных заболеваний.
· Молекулярная биология. Анализ строения аминокислот.
Это далеко не полный список областей, где можно использовать деревья решений. Не исследованы еще многие потенциальные области применения.
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008.
2. Батыгин Г.С. Лекции по методологии социологических исследований. М. Аспект Пресс, 1995, – 286 с.
3. Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных странах: Учебник. – М.: Логос, 2008. – 392 с.
4. Смирнов Э.А. Разработка управленческих решений. – М.: ИНФРА-М, 2008. – 272 с.
5. Трахтенгерц Э.А. Компьютерная поддержка принятия решений: Научно-практическое издание. – М.: СИНТЕГ, 1998. – 376 с.
6. Фатхутдинов Р.А. Разработка управленческого решения: Учеб. пособ. – М.: Бизнес-школа, Интел-Синтез, 2007. – 272 с.
Цель: изучение особенностей и методов принятия решений коллективом экспертов; рассмотрение понятия и особенностей нейронных сетей.
Задачи:
· Рассмотреть метод экспертных оценок и его составляющие.
· Изучить особенности применения нейронных сетей для задач классификации.
Вопросы темы:
1. Метод экспертных оценок.
2. Применение нейронных сетей для задач классификации.
Экспертное оценивание – процедура получения оценки проблемы на основе мнения специалистов (экспертов) с целью последующего принятия решения (выбора).
Существует две группы экспертных оценок:
· Индивидуальные оценки основаны на использовании мнения отдельных экспертов, независимых друг от друга.
· Коллективные оценки основаны на использовании коллективного мнения экспертов.
Совместное мнение обладает большей точностью, чем индивидуальное мнение каждого из специалистов. Данный метод применяют для получения количественных оценок качественных характеристик и свойств. Например, оценка нескольких технических проектов по их степени соответствия заданному критерию, во время соревнования оценка судьями выступления фигуриста.
Известны следующие методы экспертных оценок:
· Метод ассоциаций. Основан на изучении схожего по свойствам объекта с другим объектом.
· Метод парных (бинарных) сравнений. Основан на сопоставлении экспертом альтернативных вариантов, из которых надо выбрать наиболее предпочтительные.
· Метод векторов предпочтений. Эксперт анализирует весь набор альтернативных вариантов и выбирает наиболее предпочтительные.
· Метод фокальных объектов. Основан на перенесении признаков случайно отобранных аналогов на исследуемый объект.
Индивидуальный экспертный опрос. Опрос в форме интервью или в виде анализа экспертных оценок. Означает беседу заказчика с экспертом, в ходе которой заказчик ставит перед экспертом вопросы, ответы на которые значимы для достижения программных целей. Анализ экспертных оценок предполагает индивидуальное заполнение экспертом разработанного заказчиком формуляра, по результатам которого производится всесторонний анализ проблемной ситуации и выявляются возможные пути ее решения. Свои соображения эксперт выносит в виде отдельного документа.
Метод средней точки. Формулируются два альтернативных варианта решения, один из которых менее предпочтителен. После этого эксперту необходимо подобрать третий альтернативный вариант, оценка которого расположена между значений первой и второй альтернативы.
Этапы экспертного оценивания:
· Постановка цели исследования.
· Выбор формы исследования, определение бюджета проекта.
· Подготовка информационных материалов, бланков анкет, модератора процедуры.
· Подбор экспертов.
· Проведение экспертизы.
· Статистический анализ результатов.
· Подготовка отчета с результатами экспертного оценивания.
Постановка цели исследования.
Проверить информацию. Необходимо проверить точность фактов и достоверность сведений. На странице обсуждения должны быть пояснения.
Экспертное оценивание предполагает создание некого разума, обладающего большими способностями по сравнению с возможностями отдельного человека. Источником возможностей мультиразума является поиск слабых ассоциаций и предположений, основанных на опыте отдельного специалиста. Экспертный подход позволяет решать задачи, не поддающиеся решению обычным аналитическим способом, в том числе:
· Выбор лучшего варианта решения среди имеющихся.
· Прогнозирование развития процесса.
· Поиска возможного решения сложных задач.
Перед началом экспертного исследования необходимо четко определить его цель (проблему) и сформулировать соответствующий вопрос для экспертов. При этом рекомендуется придерживаться следующих правил:
Четкое определение условий, времени, внешних и внутренних ограничений проблемы. Возможность ответа на вопрос с доступной человеческому опыту точностью.
Вопрос лучше формулировать как качественное утверждение, чем как оценку числа. Для численных оценок не рекомендуется задавать более пяти градаций.
Эксперты оценивают возможные варианты, и не следует ожидать от них построения законченного плана действий, развернутого описания возможных решений.
Выбор формы исследования, определение бюджета проекта.
Существующие виды экспертных оценок можно классифицировать по признакам:
По форме участия экспертов: очное, заочное. Очный метод позволяет сосредоточить внимание экспертов на решаемой проблеме, что повышает качество результата, однако заочный метод может быть дешевле.
По количеству итераций (повторов процедуры для повышения точности) – одношаговые и итерационные.
По решаемым задачам: генерирующие решения и оценивающие варианты.
По типу ответа: идейные, ранжирующие, оценивающие объект в относительной или абсолютной (численной) шкале.
По способу обработки мнений экспертов: непосредственные и аналитические.
По количеству привлекаемых экспертов: без ограничения, ограниченные. Обычно используется 5 – 12 человек экспертов.
Наиболее известные методы экспертных оценок: метод Дельфи, мозговой штурм и метод анализа иерархий. Каждому методу соответствуют свои сроки проведения и потребность в экспертах. Рассмотрим более подробно методологию метода анализа иерархий и метода мозгового штурма.
Метод Анализа Иерархий (далее - МАИ) – математический инструмент системного подхода к сложным проблемам принятия решений. Основное применение при проведении оценки МАИ находит при осуществлении процедуры согласования полученных результатов по затратному, сравнительному и доходному подходу и расчете итоговой стоимости оцениваемого объекта. Рассмотрим методологию данного математического инструментария более подробно.
МАИ не предписывает лицу, принимающему решение, какого-либо «правильного» решения проблемы, а позволяет ему в интерактивном режиме найти такой альтернативный вариант, который наилучшим образом согласуется с пониманием указанным лицом сути проблемы и требованиями к ее решению. МАИ позволяет понятным и рациональным образом структурировать сложную проблему принятия решений в виде иерархии, а также сравнить и выполнить количественную оценку альтернативных вариантов решения.
Анализ проблемы принятия решений в МАИ начинается с построения иерархической структуры, которая включает цель, критерии, альтернативы и другие рассматриваемые факторы, влияющие на выбор. Эта структура отражает понимание проблемы лицом, принимающим решение. Каждый элемент иерархии может представлять различные аспекты решаемой задачи, причем во внимание могут быть приняты материальные и нематериальные факторы, измеряемые количественные параметры и качественные характеристики, объективные данные и субъективные экспертные оценки. Следующим этапом анализа является определение приоритетов, представляющих относительную важность или предпочтительность элементов построенной иерархической структуры, с помощью процедуры парных сравнений. Безразмерные приоритеты позволяют обоснованно сравнивать разнородные факторы, что является отличительной особенностью МАИ. На заключительном этапе анализа выполняется синтез (линейная свертка) приоритетов на иерархии, в результате которой вычисляются приоритеты альтернативных решений относительно главной цели. Лучшей считается альтернатива с максимальным значением приоритета.
Рассмотрим каждый этап МАИ более подробно:
Представление проблемы в виде иерархии.
Вершиной иерархии является главная цель; элементы нижнего уровня представляют множество вариантов достижения цели (альтернатив); элементы промежуточных уровней соответствуют критериям или факторам, которые связывают цель с альтернативами. Существуют специальные термины для описания иерархической структуры МАИ. Каждый уровень иерархии состоит из узлов. Элементы, исходящие из узла, принято называть его «детьми» (дочерними элементами). Элементы, из которых исходит узел, называются родительскими. Группы элементов, имеющие один и тот же родительский элемент, называются группами сравнения. Родительские элементы альтернатив, как правило, исходящие из различных групп сравнения, называются покрывающими критериями. Вид любой иерархии МАИ будет зависеть не только от объективного характера рассматриваемой проблемы, но и от знаний, суждений, системы ценностей, мнений, желаний и т. п. участников процесса. Опубликованные описания применений МАИ часто включают в себя различные схемы и объяснения представленных иерархий. Последовательное выполнение всех шагов МАИ предусматривает возможность изменения структуры иерархии с целью включения в неё вновь появившихся или ранее не считавшихся важными критериев и альтернатив.
Иерархия является полной, если каждый элемент заданного уровня является критерием для всех элементов нижнего уровня (рис. 24).
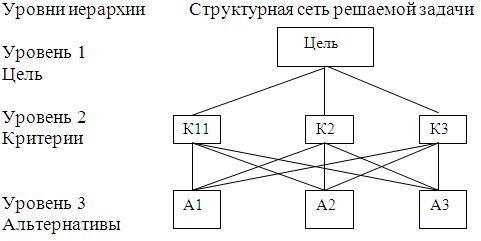
Рис. 24. Полная доминантная иерархия
Определение приоритетов критериев.
После иерархического представления задачи необходимо установить приоритеты критериев и оценить каждую из альтернатив по выбранным критериям, определив наиболее важную их них.
Приоритеты – это числа, которые связаны с узлами иерархии. Они представляют собой относительные веса элементов в каждой группе. Подобно вероятностям, приоритеты – безразмерные величины, которые могут принимать значения от нуля до единицы. Чем больше величина приоритета, тем более значимым является соответствующий ему элемент. Сумма приоритетов элементов, подчиненных одному элементу вышестоящего уровня иерархии, равна единице. Приоритет цели по определению равен 1,0.
В МАИ элементы сравниваются попарно по отношению к их влиянию на общую для них характеристику.
Парные сравнения приводят к записи характеристик сравнений в виде квадратной таблицы чисел, т.е. матрицы.
Сравнивая набор критериев друг с другом, получим следующую матрицу:
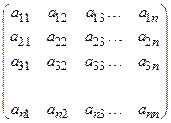
Эта матрица обратно симметричная, т.е. имеет место свойство
![]() ,
,
где индексы i и j - номер строки и номер столбца, на пересечении которых стоит элемент.
При сравнении элемента с самим собой имеем равную значимость, так что на пересечение строки и столбца с одинаковыми номерами заносим единицу. Поэтому главная диагональ будет состоять из единиц.
Таким образом, матрица парных сравнений имеет вид
Когда задача представлена в виде иерархической структуры, матрица составляется для попарного сравнения критериев на втором уровне по отношению к общей цели, расположенной на первом уровне. Такие же матрицы должны быть построены для парных сравнений каждой альтернативы на третьем уровне по отношению к критериям второго уровня и т.д., в зависимости от количества уровней.
Матрица составляется следующим образом.
В левом верхнем углу записывается цель или критерий, по отношению к которым будет проводиться сравнение; в левом столбце и верхней строке необходимо перечислить сравниваемые элементы. Для иерархии, приведенной на рис. 24, потребуется построить четыре матрицы - одну для второго уровня и три для третьего. Эти матрицы представлены в рис. 25 и 26.
Рис. 25. Матрица второго уровня
Рис. 26. Матрицы третьего уровня
Для проведения субъективных парных сравнений в МАИ разработана шкала относительной важности, представленная в табл. 27.
Таблица 27.
Шкала относительной важности
|
Интенсивность относительной важности |
Определение |
Объяснение |
|
1 |
Равная важность |
Равный вклад двух критериев в цель |
|
3 |
Умеренное превосходство одного над другим |
Опыт и суждения дают легкое превосходство одной альтернативы над другой |
|
5 |
Существенное или сильное превосходство |
Опыт и суждения дают сильное превосходство одного критерия над другим |
|
7 |
Значительное превосходство |
Одному из критериев дается настолько сильное предпочтение, что оно становится практически значительным |
|
9 |
Очень сильное превосходство |
Очевидность превосходства одного критерия над другим подтверждается наиболее сильно |
|
2, 4, 6, 8 |
Промежуточные решения между двумя соседними суждениями |
Применяется в компромиссных случаях |
|
Обратные величины приведенных выше чисел |
Если при сравнении одного критерия с другим получено одно из вышеуказанных чисел, то при сравнении второго критерия с первым получаем обратную величину |
|
При проведении попарных сравнений задаются следующие вопросы:
· Какая из альтернатив важнее или имеет большее воздействие на цель?
· Какая из альтернатив более вероятна?
· Какая из альтернатив предпочтительнее?
· Какой из критериев более важен?
· Какая из альтернатив более желательна по отношению к определенному критерию?
· Какой из сценариев более вероятен?
Когда возникают споры, применяют геометрическое среднее разных оценок в качестве общей оценки суждений,
![]()
Синтез приоритетов.
После построения иерархии и определения величин парных субъективных суждений следует этап, на котором иерархическая декомпозиция и относительные суждения объединяются для получения осмысленного решения многокритериальной задачи принятия решений.
Локальные приоритеты.
Из групп парных сравнений формируется набор локальных критериев, которые выражают относительное влияние элементов на элемент, расположенный на уровень выше.
Для определения относительной ценности каждого элемента необходимо найти геометрическое среднее и с этой целью перемножить n элементы каждой строки и из полученного результата извлечь корни n-й степени (1). Полученные числа необходимо нормализовать.
![]() (19)
(19)
Для нормализации полученных чисел определяем нормирующий множитель r.
![]() . (20)
. (20)
И каждое из чисел ![]() делим
на r.
делим
на r.
![]() . (21)
. (21)
В результате получаем вектор приоритетов:
![]() , (22)
, (22)
где индекс 2 означает, что вектор приоритетов относится ко второму уровню иерархии.
Согласованность локальных приоритетов.
Любая матрица суждений в общем случае является не согласованной.
Когда отклонения от согласованности превышают установленные пределы, возникает необходимость определения индекса согласованности и отношения согласованности.
Индекс согласованности (ИС) в каждой матрице и для всей иерархии может быть выражен следующим способом.
Определяется сумма каждого j-го столбца матрицы суждений.
![]() (23)
(23)
Затем полученный результат умножается на j-ю компоненту нормализованного вектора приоритетов q2, т.е. сумма суждений первого столбца - на первую компоненту, сумма суждений второго столбца - на вторую и т.д.
![]() . (24)
. (24)
Сумма чисел рj отражает пропорциональность предпочтений, чем ближе эта величина к n (числу объектов и видов действия в матрице парных сравнений), тем более согласованны суждения
![]() . (25)
. (25)
Отклонение от согласованности выражается индексом согласованности:
![]() (26)
(26)
Для определения того, насколько точно ИС отражает согласованность суждений, его необходимо сравнить со случайным индексом согласованности (далее - СИ), который соответствует матрице со случайными суждениями, выбранными из шкалы
![]() ,
,
при условии равной вероятности выбора любого из приведённых чисел.
В табл. 28 приведены средние значения случайного индекса согласованности (СИ) для случайных матриц суждений разного порядка.
Таблица 28.
Средние значения СИ для случайных матриц суждений разного порядка
|
Размер матрицы |
Среднее значение СИ |
|
1 |
0,00 |
|
2 |
0.00 |
|
3 |
0.58 |
|
4 |
0.90 |
|
5 |
1.12 |
|
6 |
1.24 |
|
7 |
1.32 |
|
8 |
1.41 |
|
9 |
1,45 |
|
10 |
1,49 |
|
11 |
1,51 |
|
12 |
1,48 |
|
13 |
1,56 |
|
14 |
1,57 |
|
15 |
1,59 |
Отношение ИС к среднему значению СИ для матрицы того же порядка называется отношением согласованности (ОС):
![]() (27)
(27)
Значение ОС меньше или равное 0,10 считается приемлемым.
Синтез альтернатив.
Векторы приоритетов и отношения согласованности определяются для всех матриц суждений, начиная со второго уровня вниз.
Для определения приоритетов альтернатив необходимо локальные приоритеты умножить на приоритет соответствующего критерия на вышестоящем уровне и найти суммы по каждому элементу в соответствии с критериями, на которые воздействует этот элемент.
Обозначим через
![]() - вектор
приоритетов k-й матрицы, расположенной на третьем уровне;
- вектор
приоритетов k-й матрицы, расположенной на третьем уровне;
![]() - i-й
элемент вектор приоритетов k-й матрицы суждений, расположенной на
третьем уровне;
- i-й
элемент вектор приоритетов k-й матрицы суждений, расположенной на
третьем уровне;
![]() - k-й
элемент вектор приоритетов матрицы суждений, расположенной на втором уровне;
- k-й
элемент вектор приоритетов матрицы суждений, расположенной на втором уровне;
![]() - приоритет j-го
элемента третьего уровня.
- приоритет j-го
элемента третьего уровня.
Тогда приоритет j-го элемента третьего уровня определяется как
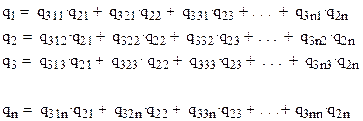 (28)
(28)
Метод мозгового штурма (мозговой штурм, мозговая атака) – оперативный метод решения проблемы на основе стимулирования творческой активности, при котором участникам обсуждения предлагают высказывать как можно большее количество вариантов решения, в том числе самых фантастичных. Затем из общего числа высказанных идей отбирают наиболее удачные, которые могут быть использованы на практике.
Этапы и правила мозгового штурма.
Правильно организованный мозговой штурм включает три обязательных этапа. Этапы отличаются организацией и правилами их проведения:
· Постановка проблемы. Предварительный этап. В начале этого этапа проблема должна быть четко сформулирована. Происходит отбор участников штурма, определение ведущего и распределение прочих ролей участников в зависимости от поставленной проблемы и выбранного способа проведения штурма.
· Генерация идей. Основной этап, от которого во многом зависит успех всего мозгового штурма. Поэтому очень важно соблюдать правила для этого этапа:
1. Главное – количество идей. Не делайте никаких ограничений.
2. Полный запрет на критику и любую (в том числе положительную) оценку высказываемых идей, так как оценка отвлекает от основной задачи и сбивает творческий настрой.
3. Необычные и даже абсурдные идеи приветствуются. Комбинируйте и улучшайте любые идеи.
· Группировка, отбор и оценка идей. Этот этап часто забывают, но именно он позволяет выделить наиболее ценные идеи и дать окончательный результат мозгового штурма. На этом этапе, в отличие от второго, оценка не ограничивается, а наоборот, приветствуется. Методы анализа и оценки идей могут быть очень разными. Успешность этого этапа напрямую зависит от того, насколько «одинаково» участники понимают критерии отбора и оценки идей.
Мозговые атаки.
Для проведения мозговой атаки обычно создают две группы:
· участники, предлагающие новые варианты решения задачи;
· члены комиссии, обрабатывающие предложенные решения.
Различают индивидуальные и коллективные мозговые атаки.
В мозговом штурме участвует коллектив из нескольких специалистов и ведущий. Перед самим сеансом мозгового штурма ведущий производит четкую постановку задачи, подлежащей решению. В ходе мозгового штурма участники высказывают свои идеи, направленные на решение поставленной задачи, причём как логичные, так и абсурдные. Если в мозговом штурме принимают участие люди различных чинов или рангов, то рекомендуется заслушивать идеи в порядке возрастания ранжира, что позволяет исключить психологический фактор «соглашения с начальством».
В процессе мозгового штурма, как правило, вначале решения не отличаются высокой оригинальностью, но по прошествии некоторого времени типовые, шаблонные решения исчерпываются, и у участников начинают возникать необычные идеи. Ведущий записывает или как-то иначе регистрирует все идеи, возникшие в ходе мозгового штурма.
Затем, когда все идеи высказаны, производится их анализ, развитие и отбор. В итоге находится максимально эффективное и часто нетривиальное решение задачи.
Успех мозгового штурма сильно зависит от психологической атмосферы и активности обсуждения, поэтому роль ведущего в мозговом штурме очень важна. Именно он может «вывести из тупика» и вдохнуть свежие силы в процесс.
Изобретателем метода мозгового штурма считается Алекс Осборн, сотрудник рекламного агентства BBD&O. Одним из продолжений метода мозгового штурма является метод синектики.
После выбора метода экспертного оценивания можно определить затраты на процедуру, которые включают оплату экспертов, аренду помещения, приобретение канцтоваров, оплату специалиста по проведению и анализу результатов экспертизы.
Подготовка информационных материалов.
Эксперты перед вынесением суждения должны разносторонне рассмотреть представленную проблему. Для проведения этой процедуры необходимо подготовить информационные материалы с описанием проблемы, имеющиеся статистические данные, справочные материалы, бланки анкет, инвентарь. Следует избегать следующих ошибок: упоминать разработчиков материалов, выделять тот или иной вариант решения, выражать отношение руководства к ожидаемым результатам. Данные должны быть разносторонние и нейтральные. Заранее необходимо разработать бланки анкет для экспертов. В зависимости от метода они могут быть с открытыми и закрытыми вопросами, ответ может даваться в виде суждении, парного сравнения, ранжированного ряда, в баллах или в виде абсолютной оценки.
Саму процедуру проводит независимый модератор процедуры, который контролирует соблюдение регламента, раздает материалы и анкеты, но сам не высказывает свое мнение.
Подбор экспертов.
Эксперты должны обладать опытом в областях, соответствующих решаемым задачам. При подборе экспертов следует учитывать момент личной заинтересованности, который может стать существенным препятствием для получения объективного суждения. С этой целью, например, применяют методы Шара, когда один эксперт, наиболее уважаемый специалист, рекомендует ряд других и далее по цепочке, пока не будет подобран необходимый коллектив.
Проведение экспертизы.
Проведение процедуры отличается в зависимости от используемого метода. Общие рекомендации:
· Препятствовать давлению авторитетов (эксперт часто боится противоречить мнению большинства или наиболее уважаемого специалиста).
· Установить и соблюдать регламент. Увеличение времени на принятие решения сверх оптимального не повышает точность ответа.
Статистический анализ результатов.
После получения ответов экспертов необходимо провести их оценку. Это позволяет оценить согласованность мнений экспертов. При отсутствии значимой согласованности экспертов необходимо выявить причины несогласованности (наличие групп) и признать отсутствие согласованного мнения (ничтожные результаты).
Оценить ошибку исследования.
Построить модель свойств объекта на основе ответов экспертов (для аналитической экспертизы). Результаты экспертного оценивания оформляются в виде отчёта. В отчете указывается цель исследования, состав экспертов, полученная оценка и статистический анализ результатов.
Решение задачи классификации является одним из важнейших применений нейронных сетей. Задача классификации представляет собой задачу отнесения образца к одному из нескольких попарно не пересекающихся множеств. Примером таких задач может быть, например, задача определения кредитоспособности клиента банка, медицинские задачи, в которых необходимо определить, например, исход заболевания, решение задач управления портфелем ценных бумаг (продать купить или «придержать» акции в зависимости от ситуации на рынке), задача определения жизнеспособных и склонных к банкротству фирм.
Цель классификации.
При решении задач классификации необходимо отнести имеющиеся статические образцы (характеристики ситуации на рынке, данные медосмотра, информация о клиенте) к определенным классам. Возможно несколько способов представления данных. Наиболее распространенным является способ, при котором образец представляется вектором. Компоненты этого вектора представляют собой различные характеристики образца, которые влияют на принятие решения о том, к какому классу можно отнести данный образец. Например, для медицинских задач в качестве компонентов этого вектора могут быть данные из медицинской карты больного. Таким образом, на основании некоторой информации о примере, необходимо определить, к какому классу его можно отнести. Классификатор таким образом относит объект к одному из классов в соответствии с определенным разбиением N-мерного пространства, которое называется пространством входов, и размерность этого пространства является количеством компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В реальных задачах часто возникает ситуация, когда количество образцов ограничено, что осложняет определение сложности задачи. Возможно выделить три основных уровня сложности. Первый (самый простой) – когда классы можно разделить прямыми линиями (или гиперплоскостями, если пространство входов имеет размерность больше двух) – так называемая линейная разделимость. Во втором случае классы невозможно разделить линиями (плоскостями), но их возможно отделить с помощью более сложного деления – нелинейная разделимость. В третьем случае классы пересекаются и можно говорить только о вероятностной разделимости.
В идеальном варианте после предварительной обработки мы должны получить линейно разделимую задачу, так как после этого значительно упрощается построение классификатора. К сожалению, при решении реальных задач мы имеем ограниченное количество образцов, на основании которых и производится построение классификатора. При этом мы не можем провести такую предобработку данных, при которой будет достигнута линейная разделимость образцов.
Использование нейронных сетей в качестве классификатора.
Сети с прямой связью являются универсальным средством аппроксимации функций, что позволяет их использовать в решении задач классификации. Как правило, нейронные сети оказываются наиболее эффективным способом классификации, потому что генерируют фактически большое число регрессионных моделей (которые используются в решении задач классификации статистическими методами).
К сожалению, в применении нейронных сетей в практических задачах возникает ряд проблем. Во-первых, заранее не известно, какой сложности (размера) может потребоваться сеть для достаточно точной реализации отображения. Эта сложность может оказаться чрезмерно высокой, что потребует сложной архитектуры сетей. Так Минский в своей работе «Персептроны» доказал, что простейшие однослойные нейронные сети способны решать только линейно разделимые задачи. Это ограничение преодолимо при использовании многослойных нейронных сетей. В общем виде можно сказать, что в сети с одним скрытым слоем вектор, соответствующий входному образцу, преобразуется скрытым слоем в некоторое новое пространство, которое может иметь другую размерность, а затем гиперплоскости, соответствующие нейронам выходного слоя, разделяют его на классы. Таким образом сеть распознает не только характеристики исходных данных, но и «характеристики характеристик», сформированные скрытым слоем.
Подготовка исходных данных.
Для построения классификатора необходимо определить, какие параметры влияют на принятие решения о том, к какому классу принадлежит образец. При этом могут возникнуть две проблемы. Во-первых, если количество параметров мало, то может возникнуть ситуация, при которой один и тот же набор исходных данных соответствует примерам, находящимся в разных классах. Тогда невозможно обучить нейронную сеть, и система не будет корректно работать (невозможно найти минимум, который соответствует такому набору исходных данных). Исходные данные обязательно должны быть непротиворечивы. Для решения этой проблемы необходимо увеличить размерность пространства признаков (количество компонент входного вектора, соответствующего образцу). Но при увеличении размерности пространства признаков может возникнуть ситуация, когда число примеров может стать недостаточным для обучения сети, и она вместо обобщения просто запомнит примеры из обучающей выборки и не сможет корректно функционировать. Таким образом, при определении признаков необходимо найти компромисс с их количеством.
Далее необходимо определить способ представления входных данных для нейронной сети, т.е. определить способ нормирования. Нормировка необходима, поскольку нейронные сети работают с данными, представленными числами в диапазоне 0..1, а исходные данные могут иметь произвольный диапазон или вообще быть нечисловыми данными. При этом возможны различные способы, начиная от простого линейного преобразования в требуемый диапазон и заканчивая многомерным анализом параметров и нелинейной нормировкой в зависимости от влияния параметров друг на друга.
Кодирование выходных значений.
Задача классификации при наличии двух классов может быть решена на сети с одним нейроном в выходном слое, который может принимать одно из двух значений 0 или 1, в зависимости от того, к какому классу принадлежит образец. При наличии нескольких классов возникает проблема, связанная с представлением этих данных для выхода сети. Наиболее простым способом представления выходных данных в таком случае является вектор, компоненты которого соответствуют различным номерам классов. При этом i-я компонента вектора соответствует i-му классу. Все остальные компоненты при этом устанавливаются в 0. Тогда, например, второму классу будет соответствовать 1 на 2 выходе сети и 0 на остальных. При интерпретации результата обычно считается, что номер класса определяется номером выхода сети, на котором появилось максимальное значение. Например, если в сети с тремя выходами мы имеем вектор выходных значений (0.2,0.6,0.4), то мы видим, что максимальное значение имеет вторая компонента вектора, значит класс, к которому относится этот пример, – 2. При таком способе кодирования иногда вводится также понятие уверенности сети в том, что пример относится к этому классу. Наиболее простой способ определения уверенности заключается в определении разности между максимальным значением выхода и значением другого выхода, которое является ближайшим к максимальному. Например, для рассмотренного выше примера уверенность сети в том, что пример относится ко второму классу, определится как разность между второй и третьей компонентой вектора и равна 0.6-0.4=0.2. Соответственно чем выше уверенность, тем больше вероятность того, что сеть дала правильный ответ. Этот метод кодирования является самым простым, но не всегда самым оптимальным способом представления данных.
Известны и другие способы. Например, выходной вектор представляет собой номер кластера, записанный в двоичной форме. Тогда при наличии 8 классов нам потребуется вектор из 3 элементов, и, скажем, 3 классу будет соответствовать вектор 011. Но при этом в случае получения неверного значения на одном из выходов мы можем получить неверную классификацию (неверный номер кластера), поэтому имеет смысл увеличить расстояние между двумя кластерами за счет использования кодирования выхода по коду Хемминга, который повысит надежность классификации.
Другой подход состоит в разбиении задачи с k классами на k*(k-1)/2 подзадач с двумя классами (2 на 2 кодирование) каждая. Под подзадачей в данном случае понимается то, что сеть определяет наличие одной из компонент вектора. Т.е. исходный вектор разбивается на группы по два компонента в каждой таким образом, чтобы в них вошли все возможные комбинации компонент выходного вектора. Число этих групп можно определить как количество неупорядоченных выборок по два из исходных компонент. Из комбинаторики
![]()
Тогда, например, для задачи с четырьмя классами мы имеем 6 выходов (подзадач) распределенных следующим образом:
Таблица 29.
|
N подзадачи (выхода) |
Компоненты выхода |
|
1 |
1-2 |
|
2 |
1-3 |
|
3 |
1-4 |
|
4 |
2-3 |
|
5 |
2-4 |
|
6 |
3-4 |
Где 1 на выходе говорит о наличии одной из компонент. Тогда мы можем перейти к номеру класса по результату расчета сетью следующим образом: определяем, какие комбинации получили единичное (точнее близкое к единице) значение выхода (т.е. какие подзадачи у нас активировались), и считаем, что номер класса будет тот, который вошел в наибольшее количество активированных подзадач (см. таблицу).
Таблица 30.
|
N класса |
Акт. Выходы |
|
1 |
1,2,3 |
|
2 |
1,4,5 |
|
3 |
2,4,6 |
|
4 |
3,5,6 |
Это кодирование во многих задачах дает лучший результат, чем классический способ кодирование.
Выбор объема сети.
Правильный выбор объема сети имеет большое значение. Построить небольшую и качественную модель часто бывает просто невозможно, а большая модель будет просто запоминать примеры из обучающей выборки и не производить аппроксимацию, что, естественно, приведет к некорректной работе классификатора. Существуют два основных подхода к построению сети – конструктивный и деструктивный. При первом из них вначале берется сеть минимального размера, и постепенно увеличивают ее до достижения требуемой точности. При этом на каждом шаге ее заново обучают. Также существует так называемый метод каскадной корреляции, при котором после окончания эпохи происходит корректировка архитектуры сети с целью минимизации ошибки. При деструктивном подходе вначале берется сеть завышенного объема, и затем из нее удаляются узлы и связи, мало влияющие на решение. При этом полезно помнить следующее правило: число примеров в обучающем множестве должно быть больше числа настраиваемых весов. Иначе вместо обобщения сеть просто запомнит данные и утратит способность к классификации – результат будет неопределен для примеров, которые не вошли в обучающую выборку.
Выбор архитектуры сети.
При выборе архитектуры сети обычно опробуется несколько конфигураций с различным количеством элементов. При этом основным показателем является объем обучающего множества и обобщающая способность сети. Обычно используется алгоритм обучения Back Propagation (обратного распространения) с подтверждающим множеством.
Алгоритм построения классификатора на основе нейронных сетей.
1. Работа с данными.
· Составить базу данных из примеров, характерных для данной задачи.
· Разбить всю совокупность данных на два множества: обучающее и тестовое (возможно разбиение на 3 множества: обучающее, тестовое и подтверждающее).
2. Предварительная обработка.
· Выбрать систему признаков, характерных для данной задачи, и преобразовать данные соответствующим образом для подачи на вход сети (нормировка, стандартизация и т.д.). В результате желательно получить линейно отделяемое пространство множества образцов.
· Выбрать систему кодирования выходных значений (классическое кодирование, 2 на 2 кодирование и т.д.).
3. Конструирование, обучение и оценка качества сети.
· Выбрать топологию сети: количество слоев, число нейронов в слоях и т.д.
· Выбрать функцию активации нейронов (например «сигмоида»).
· Выбрать алгоритм обучения сети.
· Оценить качество работы сети на основе подтверждающего множества или другому критерию, оптимизировать архитектуру (уменьшение весов, прореживание пространства признаков).
· Остановится на варианте сети, который обеспечивает наилучшую способность к обобщению и оценить качество работы по тестовому множеству.
4. Использование и диагностика.
· Выяснить степень влияния различных факторов на принимаемое решение (эвристический подход).
· Убедится, что сеть дает требуемую точность классификации (число неправильно распознанных примеров мало).
· При необходимости вернутся на этап 2, изменив способ представления образцов или изменив базу данных.
· Практически использовать сеть для решения задачи.
Для того, чтобы построить качественный классификатор, необходимо иметь качественные данные. Никакой из методов построения классификаторов, основанный на нейронных сетях или статистический, никогда не даст классификатор нужного качества, если имеющийся набор примеров не будет достаточно полным и представительным для той задачи, с которой придется работать системе.
Основная литература:
1. Литвак Б.Г. Управленческие решения: учебник. – М.: МФПУ «Синергия», 2012. – 512с. – (Академия бизнеса).
2. Литвак Б.Г. Управленческие решения: практикум. – М.: МФПУ «Синергия», 2012. – 448с. – (Академия бизнеса).
Дополнительная литература:
1. Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Методы и модели анализа данных: OLAP и Data Mining. 2-е изд.– СПб.: БХВ – Петербург, 2008.
2. Батыгин Г.С. Лекции по методологии социологических исследований. М. Аспект Пресс, 1995, – 286 с.
3. Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных странах: Учебник. – М.: Логос, 2008. – 392 с.
4. Смирнов Э.А. Разработка управленческих решений. – М.: ИНФРА-М, 2008. – 272 с.
5. Трахтенгерц Э.А. Компьютерная поддержка принятия решений: Научно-практическое издание. – М.: СИНТЕГ, 1998. – 376 с.
6. Фатхутдинов Р.А. Разработка управленческого решения: Учеб. пособ. – М.: Бизнес-школа, Интел-Синтез, 2007. – 272 с.
[1] Хамидуллин А. Клад, который лежит под ногами // RM MAGAZINE, № 3, 2003. URL: http://www.topsbi.ru/default.asp?artID=129 (дата обращения: 15.07.2012).
[2] Хамидуллин А. Клад, который лежит под ногами // RM MAGAZINE, № 3, 2003. URL: http://www.topsbi.ru/default.asp?artID=1299 (дата обращения: 15.07.2012).
[3] Хамидуллин А. Клад, который лежит под ногами // RM MAGAZINE, № 3, 2003. URL: http://www.topsbi.ru/default.asp?artID=129 (дата обращения: 15.07.2012).