Московская финансово-промышленная академия
Храмцов П.Б.
Информационные сети
Москва, 2004
УДК 004.
ББК 32.973.202
Х 897
Храмцов П.Б. Информационные сети / Московская финансово-промышленная академия. - М., - 2004. - 290 с.
Рекомендовано Учебно-методическим объединением по образованию в области прикладной информатики в качестве учебного пособия для студентов высших учебных заведений, обучающихся по специальности 351400 «Прикладная информатика (по областям)» и другим междисциплинарным специальностям.
© Храмцов П.Б., 2004
© Московская финансово-промышленная академия, 2004
Содержание
1.2. Подключение локальной или корпоративной сети к Internet
1.3. Маршрутизация в сетях TCP/IP
1.6. Организация информационного обслуживания на основе технологий Internet
1.7. Проблемы безопасности сетей TCP/IP
Раздел 2. Основы межсетевого обмена в сетях TCP/IP
2.1. Структура стека протоколов TCP/IP
2.2. Основные протоколы стека TCP/IP
2.3. Принципы построения IP-адресов
2.6. Основные принципы IP-маршрутизации
2.7. Настройка операционной системы и сетевые интерфейсы
2.8. Настройка сетевых интерфейсов
2.9. Маршрутизация, протоколы динамической маршрутизации, средства управления маршрутами
2.10. Анализ и фильтрация TCP/IP пакетов
Раздел 3. Информационные сервисы Internet
3.2. Электронная почта в Internet
3.3. Эмуляция удаленного терминала. Удаленный доступ к ресурсам сети
3.4. Обмен файлами. Служба архивов FTP
3.5. Администрирование серверов World Wide Web
3.6. Информационно-поисковые системы Internet
Раздел
1. Введение. Основные проблемы администрирования
сетей TCP/IP
и информационных технологий Internet
В последнее время наблюдается быстрый рост числа сетей, подключенных к сообществу компьютерных сетей Internet. Темпы этого роста носят экспоненциальный характер. Популярность Internet определяется наличием простого в использовании программного обеспечения, отработанной технологии межсетевого обмена и большого количества информационных материалов, размещенных в сети за 25 лет ее существования.
|
|

Рис. 1.1. Рост числа машин, подключенных к сети Internet (MLotter, Network Wizards)
До 80% всех информационных ресурсов Internet расположено в США. По этой причине наиболее критичные пути доступа к информационным ресурсам Internet - это каналы, связывающие российский сектор сети с США.
Фактически, именно американский сектор Internet задает основные тенденции развития сети. По этой причине до 1995 года включительно наиболее пристально изучался трафик по опорной сети (backbone) Национального Научного Фонда США (National Scientific Foundation), который являлся основой американской части Internet. К сожалению, к концу 1995 года фонд принял решение о раздаче отдельных частей этой опорной сети в частные руки, что привело к невозможности получения статистики использования информационных ресурсов сети.
Во многом такое решение было продиктовано увеличением доли коммерческого использования сети. Если в 1994 году только 30% всего трафика приходилось на коммерческие информационные ресурсы, то в 1996 году коммерческая реклама стала составлять почти 80% всех информационных материалов, размещенных в сети. Коммерческое использование технологии Internet продолжает набирать обороты, и уже привело к появлению нового термина Intranet, который обозначает применение информационных технологий Internet для нужд компаний и корпораций в качестве основы их корпоративных информационных ресурсов.
|
|

Рис. 1.2. Динамика применения различных информационных технологий Internet
Все выше сказанное заставляет сейчас говорить не просто об организации TCP/IP сетей и подключении их к Internet, но и об организации централизованного обслуживания клиентов в рамках информационных технологий Internet.
Следует заметить, что мировые тенденции использования сети не очень сильно отличаются от отечественных реалий. Достаточно сравнить использование американского backbone и статистику по использованию российской сети Freenet, чтобы убедиться в этом.
Точно также, как и в NSFNET, в российской сети наибольшая часть трафика приходится на FTP. Это можно объяснить тем, что все большую популярность приобретают программы бета-тестирования продуктов с использованием сети. Современные дистрибутивы - это файлы объемом до десятка мегабайтов. Никакой трафик World Wide Web, не может сравниться с передачей такого количества информации, хотя уже вплотную и подошел к FTP и занимает второе место.
|
|

Рис. 1.3. Структура трафика
World Wide Web - это второй после FTP ресурс, который пользуется наибольшей популярностью среди пользователей Internet. В настоящее время объем трафика World Wide Web медленно, но верно приближается к объему трафика FTP. Происходит это главным образом за счет использования графики и перехода на режим обмена информацией в рамках продолжительной сессии.
Вслед за FTP и World Wide Web следует электронная почта. В настоящее время по почте передается не только текстовая информация, но и двоичная информация, которой являются программы, графические образы, видеоматериалы и звукозаписи.
На четвертое место в 1996 году вышел режим доступа к информационным ресурсам в режиме эмуляции удаленного терминала - telnet. Информационных ресурсов, доступ к которым осуществляется в режиме удаленного терминала в Internet, за 25 лет его существования накоплена масса. Это один из наиболее простых способов переноса локальных информационных систем в технологию Internet, т.к. он не требует переделки баз данных и программного обеспечения, которое используется при доступе.
Однако, telnet стал четвертым не потому, что безудержно растет его популярность. Просто популярность другой информационной технологии, Gopher, продолжает снижаться. Gopher вытесняется из Internet World Wide Web’ом. Однако, в силу того, что многие университеты до сих пор используют Gopher, и эта система не требует применения дорогостоящего оборудования, сервис Gopher еще долго будет существовать в Сети.
В данном коротком обзоре текущего состояния и тенденций развития информационных ресурсов Internet хотелось бы остановиться еще на одном моменте - эффективности использования сети информационными технологиями.
|
|

Рис. 1.4. Пакеты и байты (Основы межсетевого обмена в сетях TCP/IP)
Во 2 разделе мы подробно разберем особенности транспорта TCP/IP, здесь же хочется отметить, что различные информационные сервисы используют этот транспорт с разной эффективностью. Так, например FTP, основанный на принципе организации обмена в рамках сессии взаимодействия пользователя с сервером FTP-архива, использует транспорт TCP довольно эффективно, в то время как http, базовый протокол World Wide Web, делает это крайне неэффективно. В результате, до 30% ресурсов сети уходит не на информационный обмен, а на служебный трафик. Это хорошо заметно при рассмотрении графиков, на которых кроме байтов переданных по тому, или иному протоколу, указывается также и число пакетов. Чем больше разница, тем эффективнее работает система, т.к. меньше служебных обменов приходится на каждый переданный байт.
Однако тема данного материала, не информационные ресурсы Internet, а администрирование сети подключенной к Internet и сервисов Internet, в этой сети установленных. В рамках этой темы можно выделить несколько основных проблем, с которыми сталкивается администратор такой системы:
· Организация сети TCP/IP;
· Подключение локальной или корпоративной сети к Internet;
· Определение и управление маршрутами передачи информации в этой сети, или, другими словами, проблема маршрутизации;
· Получение доменного имени для организации, т.к. запомнить числовые адреса задача трудная и, с учетом числа машин в сети, не выполнимая. По вашему доменному имени всегда пользователи смогут добраться до информационных ресурсов вашей организации;
· Обмен электронной почтой как внутри организации, так и с адресатами за ее пределами;
· Организация информационного обслуживания на базе технологий Internet, плавно перетекающая в технологию Intranet;
· Проблема безопасности сети TCP/IP.
Остановимся на каждом из этих направлений деятельности администратора системы или группы администраторов более подробно.
1.1. Организация сети TCP/IP
Прежде, чем организовывать сеть TCP/IP следует достаточно хорошо разбираться в принципах ее функционирования. В отличие от многих других сетей, в TCP/IP практически на каждой машине следует иметь массу информации необходимой для ее настройки, которая по сети не передается. В этом есть как свои преимущества, так и свои недостатки.
Недостатки сводятся к довольно большой ручной работе по настройке каждой машины, каждого сетевого интерфейса. При этом предварительно должна быть продумана топология сети, ее физическая и логическая схемы, определено оборудование. Обязательным условием для организации TCP/IP сети является получение блока адресов Internet для всего множества сетевых интерфейсов. Данную процедуру принято называть «получение сетки».
Блок адресов, обычно, выделяется провайдером, через которого локальная сеть подключается к Internet.
При организации локальной сети, которая не будет подключена к Internet, можно официально никакой сетки не получать, а ее номер придумать, но если позже возникнет необходимость подключения к Internet, получить адреса все равно придется, но при этом придется также производить изменения во всех машинах локальной сети, меняя настройки сетевых интерфейсов.
После того как физическая сеть собрана, администратор должен собственноручно назначить на каждой машине адреса интерфейсам. Обычно это делается с консоли того компьютера, который настраивается для работы в сети. В последнее время появилась возможность динамической настройки с одного рабочего места всех машин сети. Однако, как и в любом деле, кроме явных преимуществ есть и срытые недостатки такого подхода. Главный из них - это учет статистики работы с каждой из машин системы. При динамическом назначении адресов машина может в разное время получать разные адреса, что не позволяет по адресу проидентифицировать машину. Многие же системы анализа трафика основываются на том, что соответствие между адресом и компьютером неизменно. Именно на этом принципе построены многие системы защиты от несанкционированного доступа.
Другой причиной, заставляющей жестко назначать адреса компьютерам сети, является необходимость организации информационных сервисов на серверах сети. TCP/IP не имеет механизма оповещения рабочих мест о месте нахождении сервиса. Широковещание вообще не очень распространено в сетях TCP/IP, в отличие от сетей Novell или Microsoft. Каждый хост знает о наличии того или иного сервиса либо из файла своей настройки (например, указываются шлюз в другие сети или сервер доменных имен), либо из файлов настроек прикладного программного обеспечения. Так, например, сервер World Wide Web не посылает никакого широковещательного сообщения о том, что он установлен на данном компьютере в данной сети.
Преимущество такого подхода заключается в низком трафике, порождаемом сетью TCP/IP. Этот трафик иногда очень значительно отличается от трафика Novell, например. Кроме этого практически любое оборудование позволяет фильтровать трафик TCP/IP, что сильно облегчает сегментацию сети и делает ее легко структурируемой.
Сеть TCP/IP обладает практически теми же базовыми сервисами, что и другие локальные сетевые технологии. Система позволяет работать в режиме удаленного терминала, организовывать распределенную файловую систему, сетевую печать и т.п.
Иногда приходится слышать, что обмен в рамках TCP/IP, например, при копировании файлов с локального диска на удаленный, смонтированный на данный локальный компьютер происходит медленнее, чем скажем в сети Microsoft или Netware. Во-первых, это сильно зависит от прикладного программного обеспечения, а во-вторых, в отличии от Netware или Microsoft для сети TCP/IP нет разницы между машинами, которые стоят в соседней комнате, или установлены на разных континентах. Для монтирования удаленной файловой системы нет необходимости в использовании межсетевого протокола для доставки протоколов локальной сети, т.к. стек TCP/IP сам по себе реализует этот межсетевой обмен.
В рамках организации сети TCP/IP в последнее время все больше внимание уделяется организации удаленных рабочих мест. Особенно это характерно для организаций, которые используют труд надомников. Здесь имеются в виду не старушки, которые вяжут носки, а потом продают их на вещевых рынках, и не телефонистки, которые принимают сообщения для мелких коммерческих организаций. Речь идет о программистах или других сотрудниках, которые используют модемную связь для оперативного обмена информацией, доступа к информационным ресурсам, или обмена электронной почтой.
Развитие средств коммуникации и наличие специального набора протоколов и программного обеспечения, их реализующего, позволяет организовать такие рабочие места в рамках сетей TCP/IP без особых проблем.
1.2. Подключение локальной или корпоративной сети к Internet
Подключение локальной сети TCP/IP к Internet осуществляется через местного провайдера. Обычно это та же организация, у которой был получен блок адресов для локальной сети.
Администратор локальной сети должен определить, какая машина локальной сети будет выполнять функции шлюза, именно так называется устройство, которое используется для соединения двух сетей. В настоящее время, все шире и шире, вместо машин используются специальные устройства, маршрутизаторы. Маршрутизаторы - это спец. компьютеры, которые распознают массу различных протоколов и способны правильно направлять пакеты информации из одной сети в другую. Стоит маршрутизатор столько же, сколько стоит самый “накрученный” персональный компьютер. Если подключаемая сеть большая и требуется мощное устройство для обслуживания ее внешнего трафика, то приобретение маршрутизатора оправдано, если же сеть небольшая, то можно обойтись персональным компьютером, на который следует установить соответствующее программное обеспечение.
Задача подключения локальной сети довольно простая, если только это не сеть, распределенная в пространстве, т.е. не Wide Area Network (WAN). Здесь проблема подключения к Internet приобретает как бы два направления:
· Собственно подключение различных сегментов к Internet;
· Организация сети компании средствами Internet.
Если говорить о подключении сегментов, то здесь для каждого из сегментов следует выполнить весь комплекс работ, который был описан в предыдущем разделе, т.е. получить блок адресов, сконфигурировать машины каждой из сетей, организовать сбор статистики и, если необходимо, систему динамической настройки машин.
При организации сети компании распределенной по большой площади средствами Internet, то здесь нужно позаботиться о надежной маршрутизации, своевременном обмене информацией и о защите этой информации от несанкционированного доступа. Кроме того, следует организовать информационное обслуживание, единое для всех частей такой распределенной структуры.
Организация распределенной структуры может быть выполнена либо путем использования своих собственных возможностей (аренда физической сети передачи данных), либо за счет использования существующей сети российских Internet-провайдеров. При выборе того или иного решения, как правило, во внимание принимается множество факторов, главными из которых могут быть факторы, не связанные с техническими решениями.
Понимание способов обмена данными через Internet важно и в том случае, когда организуют виртуальные локальные сети на базе протоколов, отличных от TCP/IP, но когда протоколы TCP/IP используются в качестве средства транспорта исходных сообщений из одного сегмента сети в другой.
Приведенный в разделе 4 перечень Internet-провайдеров и предоставляемых ими услуг призван упорядочить представление о возможностях российского сектора Internet и определить основные направления деятельности российских компаний, которые эти возможности предоставляют.
1.3. Маршрутизация в сетях TCP/IP
До тех пор пока вся локальная сеть представляет из себя простой сегмент сети Ethernet, не возникает проблем с приемом и передачей сообщений в рамках этой сети. Однако, стоит сеть разбить на несколько сегментов и установить шлюзы между ними, как сразу возникает проблема маршрутизации сообщений в этой сети.
Здесь уместно остановиться на том факте, что сеть Internet - это сеть коммутации пакетов. Это значит, что прежде чем отправить сообщение по сети, это сообщение «нарезается» на более мелкие части, которые называются пакетами, и вот эти самые пакеты и отправляются по сети. Сеть Internet интересна тем, что информацию о месте назначения каждый пакет несет в себе самом. Решение о том, в какую сторону направлять пакет принимается шлюзом в момент прохождения пакета через этот шлюз. Если в один момент времени некоторый путь от места отправления к месту назначения существует, то шлюз отправит пакет, который в этот момент времени через него проходит по этому пути. Если в следующий момент времени путь по какой-либо причине исчезнет, то шлюз отправит пакет по другому пути. При этом оба пакета могут принадлежать одному и тому же сообщению. В месте назначения пакетов не имеет значения последовательность получения пакетов, т.к. пакеты в себе несут также и информацию о своем месте внутри сообщения.
Такое свойство Internet обеспечивает надежную доставку сообщений в любую точку сети даже при ее неустойчивой работе. Однако, все это достигается не просто так, а за счет специального механизма, который называется маршрутизация. Основа маршрутизации - это таблица маршрутов на каждом из компьютеров в сети и правила изменения этой таблицы в случае изменения состояния самой сети.
Маршрутизация - это средство не только прокладки маршрутов, но и средство блокирования маршрутов пересылки пакетов по сети. Если таблицы настроены неправильно, то в лучшем случае пакеты будут доставляться медленно, а в худшем случае они будут доставляться не туда куда следует, что может привести к нарушению безопасности сети передачи данных. Очень часто средства маршрутизации используют для атак на системы, включенные в Internet. Известны, так называемые, ICMP-штормы, когда пакеты определенного вида могут блокировать прием/передачу информации по сети.
Если администратор по тем или иным причинам должен закрыть часть своей сети от доступа с других машин Internet, то в этом случае также можно использовать таблицу маршрутов, удаляя из нее определенные пути, или блокируя их другими средствами контроля сетевого трафика.
В разделе, посвященном проблемам маршрутизации, мы специально подробно остановимся на понятиях внутренней сети и автономной системы, а также на различиях в дисциплине прокладки маршрутов, базирующихся на этих понятиях.
И последнее замечание о проблемах маршрутизации связано с тем, что если администратор хочет, чтобы его система была видна из Internet, т.е. чтобы информационными ресурсами данной сети можно было пользоваться как внутри сети, так и за ее пределами, он должен данную сеть прописать в таблицах маршрутов провайдеров, к которым данная сеть подключена. Это взаимодействие носит не столько технический, сколько организационный характер и может занимать гораздо больше времени, чем доставка пакета из Москвы в Нью-Йорк.
1.4. Система доменных имен
Система доменных имен занимает одно из центральных мест среди информационных сервисов Internet. Это место столь велико, что часто пользователи сети отождествляют ошибки при работе системы доменных имен с ошибками работы самой сети.
И действительно, большинство информационных ресурсов сети пользователям известны по их доменным именам. Это справедливо как для адресов электронной почты, так и для схем доступа к информационным ресурсам World Wide Web. В любом адресе центральное место занимает доменное имя компьютера, на котором ресурс расположен.
Если речь идет о маленькой сети TCP/IP, то служба доменных имен Internet в данном случае не нужна. Можно обойтись простым соответствием между доменным именем и адресом Internet. Однако для организации больших сетей или виртуальных сетей через Internet, доменные имена становятся необходимыми, и проблема управления этими адресами ложится на плечи администратора сети.
Если же информационные ресурсы сети должны быть доступны из Internet, то требования к системе доменных имен становятся еще более жесткими. Сервис доменных имен должен быть согласован с администрацией домена, из которого для данной организации выделяется поддомен, и должны быть выполнены требования надежного функционирования сервиса. Это заставляет администратора искать возможность размещения дублирующих серверов данного сервиса на машинах за пределами своего домена или на машинах, имеющих независимое подключение к Internet в рамках одного и того же домена.
Сервис доменных имен допускает и разделенное управление поддоменами. Особенно это актуально для сетей, имеющих распределенную структуру. Очень трудно из одного места уследить за всем, что может твориться в филиале за сотни километров, гораздо проще часть прав по управлению удаленной частью сети возложить на местную администрацию. В этом случае происходит делегирование управления поддоменом.
От реактивности работы сервиса доменных имен зависит во многом работа всей сети в целом. Очень часто медленная скорость получения ответов на запросы к сервису доменных имен может приводить к отказам на обслуживание другими серверами информационных ресурсов Internet. Типичным примером может быть доступ к информационным страницам World Wide Web или архивам FTP. Время ожидания адреса ресурса у многих прикладных программ ограничено, и, как следствие, программы не начинают обслуживание по причине отсутствия адреса.
Сильное влияние на скорость работы сервиса доменных имен оказывает правильное планирование доменов и разбиение этих доменов на поддомены. Особое внимание при этом обычно уделяют обратному соответствию между адресами и именами, т.к. здесь разбиение более детальное, чем при определении соответствия между именами и адресами.
Для того, чтобы о вашем домене знали в сети, необходимо домен зарегистрировать. Для этого направляются специальные заявки в организацию, управляющую доменом, в который входит ваш домен. Заявки имеют определенный стандартом вид и обрабатываются роботом-автоматом, что иногда может приводить к серьезным задержкам в процедуре регистрации.
1.5. Обмен электронной почтой
Обычно все книги и руководства по управлению сетями TCP/IP сводятся к четырем вещам: настройка сетевых интерфейсов, маршрутизация, служба доменных имен и электронная почта. Таким образом, лишний раз подчеркивается важность этого средства коммуникации пользователей сети Internet.
Существование электронной почты в Internet имеет свою историю, которая очень сильно влияет на принципы администрирования этого информационного ресурса. На заре становления сети электронная почта пересылалась между машинами по протоколу UUCP (Unix-Unix-CoPy). В эту пору использовалась совсем другая форма адреса электронной почты, нежели та, к которой привыкли мы в настоящее время. После того, как скорость передачи данных по сети резко увеличилась и стало возможным передавать почту с той же скоростью, что и сообщения режима on-line, в Internet был принят другой стандарт протокола обмена электронной почтой - SMTP (Simple Mail Transfer Protocol). Кроме этого, была введена новая форма почтового адреса абонента электронной почты, основанная на доменном имени.
К сожалению, российский сектор Internet успел захватить период работы с электронной почтой, когда в качестве основного протокола использовался протокол UUCP. Сеть Relcom начинала как сеть электронной почты, где у пользователей устанавливалась программ UUPC - адаптированный вариант коммуникационной программы из системы UUCP.
Главной причиной того, что в Relcom использовался протокол UUCP, называют наилучшую его приспособленность для работы по медленным телефонным линиям связи, хорошие средства управления соединением и портами в системе UNIX и возможность автоматического дозвона. На самом деле это только часть причин. Система разрабатывалась специалистами, которые до этого занимались адаптацией системы Unix для отечественных компьютеров. Для связи между Unix-системами использовалась система UUCP. Разработчики отечественного клона Unix естественным образом использовали свои знания для организации системы электронной почты, тем более, что к тому времени свободно распространялись программы для организации такого взаимодействия. В мире уже во всю разворачивались новые системы на базе протокола SMTP, а Relcom приступил к внедрению системы на основе протокола UUCP.
В настоящее время ситуация изменилась. С 1995 года в стране ведется активное внедрение режима доступа к ресурсам Internet в режиме Dial-IP, т.е. доступ по протоколам TCP/IP через телефонную сеть. В качестве, транспорта используется уже не UUCP, а SLIP (Serial Line Internet Protocol) и PPP (Point-to-Point Protocol). Если в сравнении SLIP и UUCP можно говорить о каких-то преимуществах последнего, то в случае PPP таких преимуществ у UUCP нет. Кроме того, появилась масса программного обеспечения как коммерческого, так и свободно распространяемого, которое позволяет взаимодействовать с серверами электронной почты по телефонным линиям, используя новые транспортные протоколы. Однако, в стране существует не менее 100000 пользователей, которые пользуются почто Relcom, основанной на протоколе UUCP. Причем это не только частные лица, но и целые организации. Естественно, что появляется проблема согласования рассылки почты по разным протоколам и по адресам различной формы.
Кроме того, в мире существует еще не менее десятка других почтовых служб, к которым также надо обеспечить доступ из сети TCP/IP. Следовательно, администратор должен знать адреса шлюзов, на которые следует пересылать почту для этих абонентов.
Все выше перечисленные проблемы призвана решить система рассылки электронной почты на основе программы sendmail - наиболее популярного транспортного агента Internet. В Internet существуют разные транспортные агенты, например, smail или MMDF. Но в рамках этого курса мы рассмотри только sendmail. Вызвано это несколькими причинами: во-первых, sendmail - это самый популярный транспортный агент, во-вторых, даже sendmail имеет массу различий и при переходе с одной версии программы на другую следует лишний раз проверить соответствие формата файла настроек, который использовался раньше новому формату файла настроек, в-третьих, большинство провайдеров используют именно sendmail.
1.6.
Организация информационного обслуживания
на основе технологий Internet
В последнее время все чаще стали говорить об Intranet. При этом обычно понимают использование информационных технологий Internet для создания информационных систем внутри организации. Ядром такой системы является технология World Wide Web, расширенная возможностями подключения через программы, реализующими специальный формат обмена данными между сервером World Wide Web и системами управления базами данных, а также мобильными кодами нового языка Java, которые должны реализовать концепцию распределенной информационной системы.
Исходя из этого, концепция администрирования сетей TCP/IP расширяется администрированием серверов World Wide Web и настройкой этих серверов для работы с разными клиентами, условной генерацией ответов в зависимости от типа клиента, адреса машины и кодировки (языка).
При использовании World Wide Web для нужд организации обычно рассматривается два направления работ:
· размещение рекламы и другой информации для пользователей Internet;
· организация тематических интерфейсов для доступа к ресурсам сети для работников организации.
Оба направления работ тесно связаны с анализом статистики посещения информационных ресурсов сервера организации и информационных источников сети. Для этих целей применяется программное обеспечение сбора и анализа статистики и специализированные серверы, которые помогают запоминать информацию об интересах пользователей при доступе в сеть.
На основе полученной статистики происходит коррекция интерфейсных страниц пользователей и коррекция структуры навигационных страниц и их взаимосвязи между собой.
Кроме World Wide Web при работе с Internet используют и другие информационные технологии, из которых будут рассмотрены FTP-архивы и доступ в режиме удаленного терминала.
FTP-архивы Internet - это огромный распределенный архив различного сорта материалов: от программ до списков классической литературы. Как было показано ранее, трафик FTP-сервиса до 1996 года превосходил трафик любого другого информационного сервиса Internet. Для того, что бы присоединиться к этому распределенному архиву необходимо создать и поддерживать свой FTP-сервер. Для внутреннего использования FTP-архив также чрезвычайно полезен, т.к. может использоваться в качестве основного центрального депозитария материалов и программного обеспечения организации. Многие программы имеют возможность остановки через FTP. Такая процедура получила название портирования.
Режим удаленного терминала продолжает оставаться одним и главных способов первичной организации доступа к локальным информационным системам через сеть. Такое использование системы позволяет отказаться от копирования системы на каждый из компьютеров пользователей и централизованное управление информационным ресурсом.
1.7. Проблемы безопасности сетей TCP/IP
При всех своих достоинствах сети TCP/IP имеют один врожденный недостаток - отсутствие встроенных способов защиты информации от несанкционированного доступа. Дело в том, что информация при таком способе доступа как удаленный терминал, передается по сети открыто. Это означает, что если некто найдет способ просмотреть передаваемые по сети пакеты, то он может получить коллекцию идентификаторов и паролей пользователей TCP/IP сети. Способов совершить такое действие огромное множество. Аналогичные проблемы возникают и при организации доступа к архивам FTP и серверам World Wide Web. Поэтому одним из основных принципов администрирования TCP/IP сетей является выработка общей политики безопасности, которая заключается в том, что администратор определяет правила типа «кто, куда и откуда имеет право использовать те или иные информационные ресурсы».
Управление безопасностью начинается с управления таблицей маршрутов. При статическом администрировании маршрутов включение и удаление последних производится вручную, в случае динамической маршрутизации эту работу выполняют программы поддержки динамической маршрутизации.
Следующий этап - это управление системой доменных имен и определение разрешений на копирование описания домена и контроля запросов на получение IP-адресов. Нашумевшая история с сервером InfoArt - это типичная атака на этот вид информационного сервиса Internet.
Следующий барьер - это системы фильтрации TCP/IP трафика. Наиболее распространенным средством такой борьбы являются системы FireWall (межсетевые фильтры или, в просторечье, «стены»). Используя эти программы можно определить номер протокола и номер порта, по которым можно принимать пакеты с определенных адресов и отправлять пакеты на также определенные адреса. Одним из нетипичных способов использования этого типа систем являются компьютерные сетевые игры, например, F-19. «Стена» позволяет поражать противника, т.к. пропускает ваши пакеты, и быть одновременно неуязвимым для противника, т.к. его пакеты отфильтровываются системой.
И, наконец, последнее средство защиты - это шифрация трафика. Для этой цели также используется масса программного обеспечения, разработанного для организации защищенного обмена через общественные сети.
В рамках нашего курса мы будем рассматривать только такие способы, которые базируются на принципах организации обмена информацией в рамках технологии TCP/IP, например, фильтрация, и не будем рассматривать способы, общие для всех систем защиты информации, например, шифрация трафика.
Кроме того, в рамках анализа способов передачи информации по сети нами будут рассмотрены средства изучения трафика, которыми обычно и пользуются злоумышленники при поиске конфиденциальной информации.
Раздел 2. Основы межсетевого обмена в сетях TCP/IP
Сеть Internet - это сеть сетей, объединяющая как локальные сети, так и глобальные сети типа NSFNET. Поэтому центральным местом при обсуждении принципов построения сети является семейство протоколов межсетевого обмена TCP/IP.
Под термином «TCP/IP» обычно понимают все, что связано с протоколами TCP и IP. Это не только собственно сами проколы с указанными именами, но и протоколы, построенные на использовании TCP и IP, и прикладные программы.
Главной задачей стека TCP/IP является объединение в сеть пакетных подсетей через шлюзы. Каждая сеть работает по своим собственным законам, однако предполагается, что шлюз может принять пакет из другой сети и доставить его по указанному адресу. Реально, пакет из одной сети передается в другую подсеть через последовательность шлюзов, которые обеспечивают сквозную маршрутизацию пакетов по всей сети. В данном случае, под шлюзом понимается точка соединения сетей. При этом соединяться могут как локальные сети, так и глобальные сети. В качестве шлюза могут выступать как специальные устройства, маршрутизаторы, например, так и компьютеры, которые имеют программное обеспечение, выполняющее функции маршрутизации пакетов. Маршрутизация - это процедура определения пути следования пакета из одной сети в другую.
Такой механизм доставки становится возможным благодаря реализации во всех узлах сети протокола межсетевого обмена IP. Если обратиться к истории создания сети Internet, то с самого начала предполагалось разработать спецификации сети коммутации пакетов. Это значит, что любое сообщение, которое отправляется по сети, должно быть при отправке “нашинковано” на фрагменты. Каждый из фрагментов должен быть снабжен адресами отправителя и получателя, а также номером этого пакета в последовательности пакетов, составляющих все сообщение в целом. Такая система позволяет на каждом шлюзе выбирать маршрут, основываясь на текущей информации о состоянии сети, что повышает надежность системы в целом. При этом каждый пакет может пройти от отправителя к получателю по своему собственному маршруту. Порядок получения пакетов получателем не имеет большого значения, т.к. каждый пакет несет в себе информацию о своем месте в сообщении. При создании этой системы принципиальным было обеспечение ее живучести и надежной доставки сообщений, т.к. предполагалось, что система должна была обеспечивать управление Вооруженными Силами США в случае нанесения ядерного удара по территории страны.
2.1. Структура стека протоколов TCP/IP
При рассмотрении процедур межсетевого взаимодействия всегда опираются на стандарты, разработанные International Standard Organization (ISO). Эти стандарты получили название «Семиуровневой модели сетевого обмена» или в английском варианте «Open System Interconnection Reference Model» (OSI Ref.Model). В данной модели обмен информацией может быть представлен в виде стека, представленного на рисунке 2.1. Как видно из рисунка, в этой модели определяется все - от стандарта физического соединения сетей до протоколов обмена прикладного программного обеспечения. Дадим некоторые комментарии к этой модели.
Физический уровень данной модели определяет характеристики физической сети передачи данных, которая используется для межсетевого обмена. Это такие параметры, как: напряжение в сети, сила тока, число контактов на разъемах и т.п. Типичными стандартами этого уровня являются, например RS232C, V35, IEEE 802.3 и т.п.
|
|

Рис. 2.1. Семиуровневая модель протоколов межсетевого обмена OSI
К канальному уровню отнесены протоколы, определяющие соединение, например, SLIP (Strial Line Internet Protocol), PPP (Point to Point Protocol), NDIS, пакетный протокол, ODI и т.п. В данном случае речь идет о протоколе взаимодействия между драйверами устройств и устройствами, с одной стороны, а с другой стороны, между операционной системой и драйверами устройства. Такое определение основывается на том, что драйвер - это, фактически, конвертор данных из оного формата в другой, но при этом он может иметь и свой внутренний формат данных.
К сетевому (межсетевому) уровню относятся протоколы, которые отвечают за отправку и получение данных, или, другими словами, за соединение отправителя и получателя. Вообще говоря, эта терминология пошла от сетей коммутации каналов, когда отправитель и получатель действительно соединяются на время работы каналом связи. Применительно к сетям TCP/IP, такая терминология не очень приемлема. К этому уровню в TCP/IP относят протокол IP (Internet Protocol). Именно здесь определяется отправитель и получатель, именно здесь находится необходимая информация для доставки пакета по сети.
Транспортный уровень отвечает за надежность доставки данных, и здесь, проверяя контрольные суммы, принимается решение о сборке сообщения в одно целое. В Internet транспортный уровень представлен двумя протоколами TCP (Transport Control Protocol) и UDP (User Datagramm Protocol). Если предыдущий уровень (сетевой) определяет только правила доставки информации, то транспортный уровень отвечает за целостность доставляемых данных.
Уровень сессии определяет стандарты взаимодействия между собой прикладного программного обеспечения. Это может быть некоторый промежуточный стандарт данных или правила обработки информации. Условно к этому уровню можно отнеси механизм портов протоколов TCP и UDP и Berkeley Sockets. Однако, обычно в рамках архитектуры TCP/IP такого подразделения не делают.
Уровень обмена данными с прикладными программами (Presentation Layer) необходим для преобразования данных из промежуточного формата сессии в формат данных приложения. В Internet это преобразование возложено на прикладные программы.
Уровень прикладных программ или приложений определяет протоколы обмена данными этих прикладных программ. В Internet к этому уровню могут быть отнесены такие протоколы, как: FTP, TELNET, HTTP, GOPHER и т.п.
Вообще говоря, стек протоколов TCP отличается от только что рассмотренного стека модели OSI. Обычно его можно представить в виде схемы, представленной на рисунке 2.2.
|
|

Рис. 2.2. Структура стека протоколов TCP/IP
В этой схеме на уровне доступа к сети располагаются все протоколы доступа к физическим устройствам. Выше располагаются протоколы межсетевого обмена IP, ARP, ICMP. Еще выше основные транспортные протоколы TCP и UDP, которые кроме сбора пакетов в сообщения еще и определяют какому приложению необходимо данные отправить или от какого приложения необходимо данные принять. Над транспортным уровнем располагаются протоколы прикладного уровня, которые используются приложениями для обмена данными.
Базируясь на классификации OSI (Open System Integration) всю архитектуру протоколов семейства TCP/IP попробуем сопоставить с эталонной моделью (рисунок 2.3).
|
|
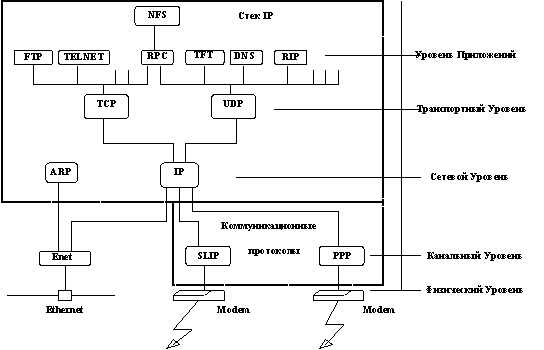
Рис. 2.3. Схема модулей, реализующих протоколы семейства TCP/IP в узле сети
Прямоугольниками на схеме обозначены модули, обрабатывающие пакеты, линиями - пути передачи данных. Прежде чем обсуждать эту схему, введем необходимую для этого терминологию.
Драйвер - программа, непосредственно взаимодействующая с сетевым адаптером.
Модуль - это программа, взаимодействующая с драйвером, с сетевыми прикладными программами или с другими модулями.
Схема приведена для случая подключения узла сети через локальную сеть Ethernet, поэтому названия блоков данных будут отражать эту специфику.
Сетевой интерфейс - физическое устройство, подключающее компьютер к сети. В нашем случае - карта Ethernet.
Кадр - это блок данных, который принимает/отправляет сетевой интерфейс.
IP-пакет - это блок данных, которым обменивается модуль IP с сетевым интерфейсом.
UDP-датаграмма - блок данных, которым обменивается модуль IP с модулем UDP.
TCP-сегмент - блок данных, которым обменивается модуль IP с модулем TCP.
Прикладное сообщение - блок данных, которым обмениваются программы сетевых приложений с протоколами транспортного уровня.
Инкапсуляция - способ упаковки данных в формате одного протокола в формат другого протокола. Например, упаковка IP-пакета в кадр Ethernet или TCP-сегмента в IP-пакет. Согласно словарю иностранных слов термин «инкапсуляция» означает «образование капсулы вокруг чужих для организма веществ (инородных тел, паразитов и т.д.)». В рамках межсетевого обмена понятие инкапсуляции имеет несколько более расширенный смысл. Если в случае инкапсуляции IP в Ethernet речь идет действительно о помещении пакета IP в качестве данных Ethernet-фрейма, или, в случае инкапсуляции TCP в IP, помещение TCP-сегмента в качестве данных в IP-пакет, то при передаче данных по коммутируемым каналам происходит дальнейшая «нарезка» пакетов теперь уже на пакеты SLIP или фреймы PPP.
|
|
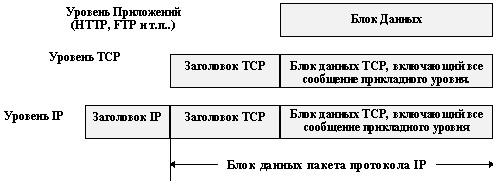
Рис. 2.4. Инкапсуляция протоколов верхнего уровня в протоколы TCP/IP
Вся схема (рисунок 2.4) называется стеком протоколов TCP/IP или просто стеком TCP/IP. Чтобы не возвращаться к названиям протоколов расшифруем аббревиатуры TCP, UDP, ARP, SLIP, PPP, FTP, TELNET, RPC, TFTP, DNS, RIP, NFS:
TCP - Transmission Control Protocol - базовый транспортный протокол, давший название всему семейству протоколов TCP/IP.
UDP - User Datagram Protocol - второй транспортный протокол семейства TCP/IP. Различия между TCP и UDP будут обсуждены позже.
ARP - Address Resolution Protocol - протокол используется для определения соответствия IP-адресов и Ethernet-адресов.
SLIP - Serial Line Internet Protocol (Протокол передачи данных по телефонным линиям).
PPP - Point to Point Protocol (Протокол обмена данными «точка-точка»).
FTP - File Transfer Protocol (Протокол обмена файлами).
TELNET - протокол эмуляции виртуального терминала.
RPC - Remote Process Control (Протокол управления удаленными процессами).
TFTP - Trivial File Transfer Protocol (Тривиальный протокол передачи файлов).
DNS - Domain Name System (Система доменных имен).
RIP - Routing Information Protocol (Протокол маршрутизации).
NFS - Network File System (Распределенная файловая система и система сетевой печати).
При работе с такими программами прикладного уровня, как FTP или telnet, образуется стек протоколов с использованием модуля TCP, представленный на рисунке 2.5.
|
|

Рис. 2.5. Стек протоколов при использовании модуля TCP
При работе с прикладными программами, использующими транспортный протокол UDP, например, программные средства Network File System (NFS), используется другой стек, где вместо модуля TCP будет использоваться модуль UDP (рисунок 2.6).
|
|

Рис. 2.6. Стек протоколов при работе через транспортный протокол UDP
При обслуживании блочных потоков данных модули TCP, UDP и драйвер ENET работают как мультиплексоры, т.е. перенаправляют данные с одного входа на несколько выходов и, наоборот, с многих входов на один выход. Так, драйвер ENET может направить кадр либо модулю IP, либо модулю ARP, в зависимости от значения поля «тип» в заголовке кадра. Модуль IP может направить IP-пакет либо модулю TCP, либо модулю UDP, что определяется полем «протокол» в заголовке пакета.
Получатель UDP-датаграммы или TCP-сообщения определяется на основании значения поля «порт» в заголовке датаграммы или сообщения.
Все указанные выше значения прописываются в заголовке сообщения модулями на отправляющем компьютере. Так как схема протоколов - это дерево, то к его корню ведет только один путь, при прохождении которого каждый модуль добавляет свои данные в заголовок блока. Машина, принявшая пакет, осуществляет демультиплексирование в соответствии с этими отметками.
Технология Internet поддерживает разные физические среды, из которых самой распространенной является Ethernet. В последнее время большой интерес вызывает подключение отдельных машин к сети через TCP-стек по коммутируемым (телефонным) каналам. С появлением новых магистральных технологий типа ATM или FrameRelay активно ведутся исследования по инкапсуляции TCP/IP в эти протоколы. На сегодняшний день многие проблемы решены и существует оборудование для организации TCP/IP сетей через эти системы.
2.2. Основные протоколы стека TCP/IP
При описании основных протоколов стека TCP/IP будем следовать модели стека описанной в предыдущем разделе. Первыми будут рассмотрены протоколы канального уровня SLIP и PPP. Это единственные протоколы этого уровня которые будут нами рассмотрены, так как были разработаны в рамках Internet и для Internet. Другие протоколы, например, NDIS или ODI, мы рассматривать не будем, т.к. они создавались под другие сети, хотя и могут использоваться в сетях TCP/IP также как, например, и пакетный протокол.
2.2.1. Протоколы SLIP и PPP
Интерес к этим двум протоколам вызван тем, что они применяются как на коммутируемых, так и на выделенных телефонных каналах. При помощи этих каналов к сети подключается большинство индивидуальных пользователей, а также небольшие локальные сети. Такие линии связи могут обеспечивать скорость передачи данных до 115200 битов за секунду.
Протокол SLIP (Serial Line Internet Protocol). Технология TCP/IP позволяет организовать межсетевое взаимодействие, используя различные физические и канальные протоколы обмена данными (IEEE 802.3 - ethernet, IEEE 802.5 - token ring, X.25 и т.п.). Однако, без обмена данными по телефонным линиям связи с использованием обычных модемов популярность Internet была бы значительно ниже. Большинство пользователей Сети используют свой домашний телефон в качестве окна в мир компьютерных сетей, подключая компьютер через модем к модемному пулу компании, предоставляющей IP-услуги или к своему рабочему компьютеру. Наиболее простым способом, обеспечивающим полный IP-сервис, является подключение через последовательный порт персонального компьютера по протоколу SLIP.
Согласно RFC-1055, впервые SLIP был включен в качестве средства доступа к IP-сети в пакет фирмы 3COM - UNET. В 1984 году Рик Адамс(Rick Adams) реализовал SLIP для BSD 4.2, и таким образом SLIP стал достоянием всего IP-сообщества.
Обычно, этот протокол применяют как на выделенных, так и на коммутируемых линиях связи со скоростями от 1200 до 19200 бит в секунду. Если модемы позволяют больше, то скорость можно “поднять”, т.к. современные персональные компьютеры позволяют передавать данные в порт со скоростью 115200 битов за секунду. Однако, при определении скорости обмена данными следует принимать во внимание, что при передаче данных по физической линии данные подвергаются преобразованиям: компрессия и защита от ошибок на линии. Такое преобразование заставляет определять меньшую скорость на линии, чем скорость порта.
Следует отметить, что среди условно-свободно распространяемых программных IP-стеков (FreeWare), Trumpet Winsock, например, обязательно включена поддержка SLIP-коммуникаций. Такие операционные системы, как FreeBSD, Linux, NetBSD, которые можно свободно скопировать и установить на своем персональном компьютере, или HP-UX, которая поставляется вместе с рабочими станциями Hewlett Packard, имеют в своем арсенале программные средства типа sliplogin (FreeBSD) или slp (HP-UX), обеспечивающими работу компьютера в качестве SLIP-сервера для удаленных пользователей, подключающихся к IP-сети по телефону. В протоколе SLIP нет определения понятия «SLIP-сервер», но реальная жизнь вносит коррективы в стандарты. В контексте нашего изложения «SLIP-клиент» - это компьютер, инициирующий физическое соединение, а «SLIP-сервер» - это машина, постоянно включенная в IP-сеть. В главе, посвященной организации IP-сетей и подключению удаленных компьютеров, будет подробно рассказано о различных способах подключения по SLIP-протоколу, поэтому, не останавливаясь на деталях такого подключения, перейдем к обсуждению самого протокола SLIP.
В отличие от Ethernet, SLIP не «заворачивает» IP-пакет в свою обертку, а «нарезает» его на «кусочки». При этом делает это довольно примитивно. SLIP-пакет начинается символом ESC (восьмеричное 333 или десятичное 219) и кончается символом END (восьмеричное 300 или десятичное 192). Если внутри пакета встречаются эти символы, то они заменяются двухбайтовыми последовательностями ESC-END (333 334) и ESC-ESC (333 335). Стандарт не определяет размер SLIP-пакета, поэтому любой SLIP-интерфейс имеет специальное поле, в котором пользователь должен указать эту длину. Однако, в стандарте есть указание на то, что BSD SLIP драйвер поддерживает пакеты длиной 1006 байт, поэтому «современные» реализации SLIP-программ должны поддерживать эту длину пакетов. SLIP-модуль не анализирует поток данных и не выделяет какую-либо информацию в этом потоке. Он просто «нарезает» ее на «кусочки», каждый из которых начинается символом ESC, а кончается символом END. Из приведенного выше описания понятно, что SLIP не позволяет выполнять какие-либо действия, связанные с адресами, т.к. в структуре пакета не предусмотрено поле адреса и его специальная обработка. Компьютеры, взаимодействующие по SLIP, обязаны знать свои IP-адреса заранее. SLIP не позволяет различать пакеты по типу протокола, например, IP или DECnet. Вообще-то, при работе по SLIP предполагается использование только IP (Serial Line IP все-таки), но простота пакета может быть соблазнительной и для других протоколов. В SLIP нет информации, позволяющей корректировать ошибки линии связи. Коррекция ошибок возлагается на протоколы транспортного уровня - TCP, UDP. В стандартном SLIP не предусмотрена компрессия данных, но существуют варианты протокола с такой компрессией. По поводу компрессии следует заметить следующее: большинство современных модемов, поддерживающих стандарты V.42bis и MNP5, осуществляют аппаратную компрессию. При этом практика работы по нашим обычным телефонным каналам показывает, что лучше отказаться от этой компрессии и работать только с автоматической коррекцией ошибок, например MNP4 или V.42. Вообще говоря, каждый должен подобрать тот режим, который наиболее устойчив в конкретных условиях работы телефонной сети (вплоть до времени года, и частоты аварий на теплотрассах).
Соединения типа «точка-точка» - протокол PPP (Point to Point Protocol). PPP - это более молодой протокол, нежели SLIP. Однако, назначение у него то же самое - управление передачей данных по выделенным или коммутируемым линиям связи. Согласно RFC-1661, PPP обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Как и в SLIP, данные «нарезаются» на фрагменты, которые называются пакетами. Пакеты передаются от узла к узлу упорядоченно. В отличие от SLIP, PPP позволяет одновременно передавать по линии связи пакеты различных протоколов. Кроме того, PPP предполагает процесс автоконфигурации обеих взаимодействующих сторон. Собственно говоря, PPP состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
При обсуждении способов транспортировки данных при межсетевом обмене часто применяется инкапсуляция, например, инкапсуляция IP в X.25. С инкапсуляцией TCP в IP мы уже встречались. Инкапсуляция обеспечивает мультиплексирование различных сетевых протоколов (протоколов межсетевого обмена, например IP) через один канал передачи данных. Инкапсуляция PPP устроенна достаточно эффективно, например, для передачи HDLC фрейма требуется всего 8 дополнительных байтов (8 октетов, согласно терминологии PPP). При других способах разбиения информации на фреймы число дополнительных байтов может быть сведено до 4 или даже 2. Для обеспечения быстрой обработки информации граница PPP пакета должна быть кратна 32 битам. При необходимости в конец пакета для выравнивания на 32-битовую границу добавляется «балласт». Вообще говоря, понятие инкапсуляции в терминах PPP - это не только добавление служебной информации к транспортируемой информации, но, если это необходимо, и разбиение этой информации на более мелкие фрагменты.
Под датаграммой в PPP понимают информационную единицу сетевого уровня, применительно к IP - IP-пакет. Под фреймом понимают информационную единицу канального уровня (согласно модели OSI). Фрейм состоит из заголовка и хвоста, между которыми содержатся данные. Датаграмма может быть инкапсулирована в один или несколько фреймов. Пакетом называют информационную единицу обмена между модулями сетевого и канального уровня. Обычно, каждому пакету ставится в соответствие один фрейм, за исключением тех случаев, когда канальный уровень требует еще большей фрагментации данных или, наоборот, объединяет пакеты для более эффективной передачи. Типичным случаем фрагментации являются сети ATM. В упрощенном виде PPP-фрейм показан на рисунке 2.7.
|
|

Рис. 2.7. PPP-фрейм
В поле «протокол» указывается тип инкапсулированной датаграммы. Существуют специальные правила кодирования протоколов в этом поле (см.ISO 3309 и RFC-1661). В поле «информация» записывается собственно пакет данных, а в поле «хвост» добавляется «пустышка» для выравнивания на 32-битувую границу. По умолчанию для фрейма PPP используется 1500 байтов. В это число не входит поле «протокол».
Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма, например). Кроме этого, протокол позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом, такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии. Любой пакет, отличный от пакета протокола управления соединением, не обрабатывается во время этого обмена. После установки параметров соединения возможен переход к идентификации. Идентификация не является обязательной. После всех этих действий происходит настройка параметров работы с протоколами межсетевого обмена (IP, IPX и т.п.). Для каждого из них используется свой протокол управления. Для завершения работы по протоколу PPP по сети передается пакет завершения работы протокола управления соединением.
Процедура конфигурации сетевых модулей операционной системы для работы по протоколу PPP более сложное занятие, чем аналогичная процедура для протокола SLIP. Однако, возможности PPP соединения гораздо более широкие. Так, например, при работе через модем модуль PPP, обычно, сам восстанавливает соединение при потере несущей частоты. Кроме того, модуль PPP сам определяет параметры своих фреймов, в то время как при SLIP их надо подбирать вручную. Правда, если настраивать оба конца, то многие проблемы не возникают из-за того, что параметры соединения известны заранее. Более подробно с протоколом PPP можно познакомиться в RFC-1661 и RFC-1548.
2.2.2. Протокол ARP. Отображение канального уровня на уровень межсетевого обмена
Прежде чем начать описание протокола ARP необходимо сказать несколько слов о протоколе Ethernet.
Технология Ethernet. Кадр Ethernet содержит адрес назначения, адрес источника, поле типа и данные. Размер адреса Ethernet - 6 байтов. Каждый сетевой адаптер имеет свой сетевой адрес. Адаптер «слушает» сеть, принимает адресованные ему кадры и широковещательные кадры с адресом FF:FF:FF:FF:FF:FF, отправляет кадры в сеть.
Технология Ethernet реализует метод множественного доступа с контролем несущей и обнаружением столкновений. Этот метод предполагает, что все устройства взаимодействуют в одной среде. В каждый момент времени передавать может только одно устройство, а все остальные только слушать. Если два или более устройств пытаются передать кадр одновременно, то фиксируется столкновение и каждое устройство возобновляет попытку передачи кадра через случайный промежуток времени. Одним словом, в каждый момент времени в сегменте узла сети находится только один кадр.
Понятно, что чем больше компьютеров подключено в сегменте Ethernet, чем больше столкновений будет зафиксировано, тем медленнее будет работать сеть. Кроме того, если в сети стоит сервер, к которому часто обращаются, то это также снизит общую производительность сети.
Важной особенностью интерфейса Ethernet является то, что каждая интерфейсная карта имеет свой уникальный адрес. Каждому производителю карт выделен свой пул адресов, в рамках которого он может выпускать карты (таблица 2.1). Согласно протоколу Ethernet, каждый интерфейс имеет 6-ти байтовый адрес. Адрес записывается в виде шести групп шестнадцатиричных цифр по две в каждой (шестнадцатеричная запись байта). Первые три байта называются префиксом, и именно они закреплены за производителем. Каждый префикс определяет 224 различных комбинаций, что равно почти 17-ти млн. адресам.
Таблица 2.1.
Префиксы адресов Ethernet интерфейсов (карт) и Производители, за которыми эти префиксы закреплены
|
Префикс |
Производитель |
Префикс |
Производитель |
|
00:00:0C |
Cisco |
08:00:0B |
Unisys |
|
00:00:0F |
NeXT |
08:00:10 |
AT&T |
|
00:00:10 |
Sytek |
08:00:11 |
Tektronix |
|
00:00:1D |
Cabletron |
08:00:14 |
Exelan |
|
00:00:65 |
Network General |
08:00:1A |
Data General |
|
00:00:6B |
MIPS |
08:00:1B |
Data General |
|
00:00:77 |
Cayman System |
08:00:1E |
Sun |
|
00:00:93 |
Proteon |
08:00:20 |
CDC |
|
00:00:A2 |
Wellfleet |
08:00:2% |
DEC |
|
00:00:A7 |
NCD |
08:00:2B |
Bull |
|
00:00:A9 |
Network Systems |
08:00:38 |
Spider Systems |
|
00:00:C0 |
Western Digital |
08:00:46 |
Sony |
|
00:00:C9 |
Emulex |
08:00:47 |
Sequent |
|
00:80:2D |
Xylogics Annex |
08:00:5A |
IBM |
|
00:AA:00 |
Intel |
08:00:69 |
Silicon Graphics |
|
00:DD:00 |
Ungermann-Bass |
08:00:6E |
Exelan |
|
00:DD:01 |
Ungermann-Bass |
08:00:86 |
Imageon/QMS |
|
02:07:01 |
MICOM/Interlan |
08:00:87 |
Xyplex terminal servers |
|
02:60:8C |
3Com |
08:00:89 |
Kinetics |
|
08:00:02 |
3Com(Bridge) |
08:00:8B |
Pyromid |
|
08:00:03 |
ACC |
08:00:90 |
Retix |
|
08:00:05 |
Symbolics |
AA:00:03 |
DEC |
|
08:00:08 |
BBN |
AA:00:04 |
DEC |
|
08:00:09 |
Hewlett-Packard |
|
|
Протокол ARP (RFC 826). Address Resolution Protocol используется для определения соответствия IP-адреса адресу Ethernet. Протокол используется в локальных сетях. Отображение осуществляется только в момент отправления IP-пакетов, так как только в этот момент создаются заголовки IP и Ethernet. Отображение адресов осуществляется путем поиска в ARP-таблице. Упрощенно, ARP-таблица состоит из двух столбцов:
|
IP-адрес |
Ethernet-адрес |
|
223.1.2.1 |
08:00:39:00:2F:C3 |
|
223.1.2.3 |
08:00:5A:21:A7:22 |
|
223.1.2.4 |
08:00:10:99:AC:54 |
В первом столбце содержится IP-адрес, а во втором Ethernet-адрес. Таблица соответствия необходима, так как адреса выбираются произвольно и нет какого-либо алгоритма для их вычисления. Если машина перемещается в другой сегмент сети, то ее ARP-таблица должна быть изменена.
Таблицу ARP можно посмотреть, используя команду arp:
quest:/usr/paul:\[8\]%arp -a
paul.polyn.kiae.su (144.206.192.34) at 0:0:1:16:2:45
polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90
arch.kiae.su (144.206.136.10) at 0:0:c:1b:ae:7b
demin.polyn.kiae.su (144.206.192.4) at 0:0:1:16:29:80
quest:/usr/paul:\[9\]%
Правда, здесь существуют нюансы. В каждый момент времени таблица ARP разная. Это хорошо видно на следующем примере:
Ix: {8} arp -a
polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent
quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32
? (144.206.140.201) at 0:0:c0:89:c4:a4
polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent
Ix.polyn.kiae.su (144.206.160.33) at (incomplete)
Ix: {9} ping apollo.polyn.kiae.su
PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes
64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.409 ms
64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.799 ms
64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.797 ms
64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.857 ms
^C
--- apollo.polyn.kiae.su ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.797/0.965/1.409 ms
Ix: {10} arp -a
polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent
quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32
? (144.206.140.201) at 0:0:c0:89:c4:a4
polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent
Ix.polyn.kiae.su (144.206.160.33) at (incomplete)
apollo.polyn.kiae.su (144.206.160.40) at 8:0:9:b:3d:b8
Ix: {11}
В приведенном примере подчеркиванием выделены команды, которые пользователь вводил из командной строки. При первом использовании команды ARP в таблице ARP нет машины apollo.polyn.kiae.su, хотя она находится в том же сегменте Ethernet, что и машина polyn.net.kiae.su, на которой выполняются команды. После выполнения команды ping в таблицу добавляется новая строка, которая задает соответствие Ethernet-адреса машины apollo и ее IP-адреса.
Кроме этого, в обоих отчетах arp есть строка с пустым именем машины, а точнее символом «?» в имени машины. В разделе 3.1 будут подробно рассмотрены вопросы определения имени машины по IP-адресу и IP-адреса по имени машины. В данном случае для машины с адресом 144.206.140.201 просто не определено соответствие между IP-адресом и именем машины.
При работе в локальной IP-сети при обращении к какому-либо ресурсу, например архиву FTP, его Ethernet-адрес ищется по IP-адресу в ARP-таблице и после этого запрос отправляется на сервер.
ARP-таблица заполняется автоматически, что хорошо видно из приведенного ранее примера. Если нужного адреса в таблице нет, то в сеть посылается широковещательный запрос типа «чей это IP-адрес?». Все сетевые интерфейсы получают этот запрос, но отвечает только владелец адреса. При этом существует два способа отправки IP-пакета, для которого ищется адрес: пакет ставится в очередь на отправку или уничтожается. В первом случае за отправку отвечает модуль ARP, а во втором случае модуль IP, который повторяет посылку через некоторое время. Широковещательный запрос выглядит так:
|
IP-адрес отправителя Ethernet-адрес отправителя |
223.1.2.1 08:00:39:00:2F:C3 |
|
Искомый IP-адрес Искомый Ethernet-адрес |
222.1.2.2 <пусто> |
Ответ машины, чей адрес ищется, будет выглядеть следующим образом:
|
IP-адрес отправителя Ethernet-адрес отправителя |
222.1.2.2 08:00:28:00:38:А9 |
|
IP-адрес получателя Ethernet-адрес получателя |
223.1.2.1 08:00:39:00:2F:C3 |
Полученный таким образом адрес будет добавлен в ARP-таблицу.
Следует отметить, что если искомого IP-адреса нет в локальной сети и сеть не соединена с другой сетью шлюзом, то разрешить запрос не удается. IP-модуль будет уничтожать такие пакеты, обычно по time-out (превышен лимит времени на разрешение запроса). Модули прикладного уровня, при этом, не могут отличить физического повреждения сети от ошибки адресации.
Однако в современной сети Internet, как правило, запрашивается информация с узлов, которые реально в локальную сеть не входят. В этом случае для разрешения адресных коллизий и отправки пакетов используется модуль IP.
Если машина соединена с несколькими сетями, т.е. она является шлюзом, то в таблицу ARP вносятся строки, которые описывают как одну, так и другую IP-сети. При использовании Ethernet и IP каждая машина имеет как минимум один адрес Ethernet и один IP-адрес. Собственно Ethernet-адрес имеет не компьютер, а его сетевой интерфейс. Таким образом, если компьютер имеет несколько интерфейсов, то это автоматически означает, что каждому интерфейсу будет назначен свой Ethernet-адрес. IP-адрес назначается для каждого драйвера сетевого интерфейса. Грубо говоря, каждой сетевой карте Ethernet соответствуют один Ethernet-адрес и один IP-адрес. IP-адрес уникален в рамках всего Internet.
2.2.3. Протокол IP
Протокол IP является самым главным во всей иерархии протоколов семейства TCP/IP. Именно он используется для управления рассылкой TCP/IP пакетов по сети Internet. Среди различных функций, возложенных на IP обычно выделяют следующие:
· определение пакета, который является базовым понятием и единицей передачи данных в сети Internet. Многие зарубежные авторы называют такой IP-пакет датаграммой;
· определение адресной схемы, которая используется в сети Internet;
· передача данных между канальным уровнем (уровнем доступа к сети) и транспортным уровнем (другими словами мультиплексирование транспортных датаграмм во фреймы канального уровня);
· маршрутизация пакетов по сети, т.е. передача пакетов от одного шлюза к другому с целью передачи пакета машине-получателю;
· «нарезка» и сборка из фрагментов пакетов транспортного уровня.
Главными особенностями протокола IP является отсутствие ориентации на физическое или виртуальное соединение. Это значит, что прежде чем послать пакет в сеть, модуль операционной системы, реализующий IP, не проверяет возможность установки соединения, т.е. никакой управляющей информации кроме той, что содержится в самом IP-пакете, по сети не передается. Кроме этого, IP не заботится о проверке целостности информации в поле данных пакета, что заставляет отнести его к протоколам ненадежной доставки. Целостность данных проверяется протоколами транспортного уровня (TCP) или протоколами приложений.
Таким образом, вся информация о пути, по которому должен пройти пакет берется из самой сети в момент прохождения пакета. Именно эта процедура и называется маршрутизацией в отличие от коммутации, которая используется для предварительного установления маршрута следования данных, по которому потом эти данные отправляют.
Принцип маршрутизации является одним из тех факторов, который обеспечил гибкость сети Internet и ее победу в соревновании с другими сетевыми технологиями. Надо сказать, что маршрутизация является довольно ресурсоемкой процедурой, так как требует анализа каждого пакета, который проходит через шлюз или маршрутизатор, в то время как при коммутации анализируется только управляющая информация, устанавливается канал, физический или виртуальный, и все пакеты пересылаются по этому каналу без анализа маршрутной информации. Однако, эта слабость IP одновременно является и его силой. При неустойчивой работе сети пакеты могут пересылаться по различным маршрутам и затем собираться в единое сообщение. При коммутации путь придется каждый раз вычислять заново для каждого пакета, а в этом случае коммутация потребует больше накладных затрат, чем маршрутизация.
Вообще говоря, версий протокола IP существует несколько. В настоящее время используется версия Ipv4 (RFC791). Формат пакета протокола представлен на рисунке 2.8.
|
|
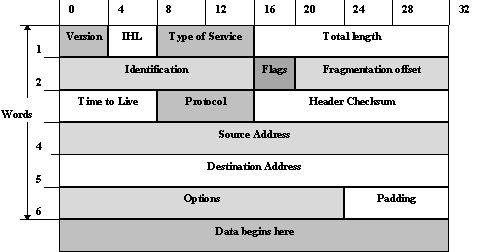
Рис. 2.8. Формат пакета Ipv4
Фактически, в этом заголовке определены все основные данные, необходимые для перечисленных выше функций протокола IP: адрес отправителя (4-ое слово заголовка), адрес получателя (5-ое слово заголовка), общая длина пакета (поле Total Lenght) и тип пересылаемой датаграммы (поле Protocol).
Используя данные заголовка, машина может определить на какой сетевой интерфейс отправлять пакет. Если IP-адрес получателя принадлежит одной из ее сетей, то на интерфейс этой сети пакет и будет отправлен, в противном случае пакет отправят на другой шлюз (см. раздел 2.6).
Если пакет слишком долго «бродит» по сети, то очередной шлюз может отправить ICMP-пакет на машину-отправитель для того, чтобы уведомить о том, что надо использовать другой шлюз. При этом, сам IP-пакет будет уничтожен. На этом принципе работает программа ping, которая используется для деления маршрутов прохождения пакетов по сети.
Зная протокол транспортного уровня, IP-модуль производит раскапсулирование информации из своего пакета и ее направление на модуль обслуживания соответствующего транспорта.
При обсуждении формата заголовка пакета IP вернемся еще раз к инкапсулированию. Как уже отмечалось, при обычной процедуре инкапсулирования пакет просто помещается в поле данных фрейма, а в случае, когда это не может быть осуществлено, то разбивается на более мелкие фрагменты. Размер максимально возможного фрейма, который передается по сети, определяется величиной MTU (Maximum Transsion Unit), определенной для протокола канального уровня. Для того, чтобы потом восстановить пакет IP должен держать информацию о своем разбиении. Для этой цели используется поля «flags» и “fragmentation offset”. В этих полях определяется, какая часть пакета получена в данном фрейме, если этот пакет был фрагментирован на более мелкие части.
Обсуждая протокол IP и вообще все семейство протоколов TCP/IP нельзя не упомянуть, что в настоящее время перед Internet возникло множество по-настоящему сложных проблем, которые требуют изменения базового протокола сети.
2.2.4. IPing - новое поколение протоколов IP
До сих пор, при обсуждении IP-технологии, основное внимание уделялось проблемам межсетевого обмена и путям их решения в рамках существующей технологии. Однако, все эти задачи, вызванные необходимостью приспособления IP к новым физическим средам передачи данных, меркнут перед действительно серьезной проблемой - ростом числа пользователей Сети. Казалось бы, что тут страшного? Число пользователей увеличивается, следовательно, растет популярность сети. Такое положение дел должно только радовать. Но проблема заключается в том, что Internet стал слишком большой, он перерос заложенные в него возможности. К 1994 году ISOC опубликовало данные, из которых стало ясно, что номера сетей класса B практически все уже выбраны, а остались только сети класса A и класса C. Класс A - это слишком большие сети. Реальные пользователи сети, такие как университеты или предприятия, не используют сети этого класса. Класс С хорош для очень небольших организаций. При современной насыщенности вычислительной техникой только мелкие конторы будут удовлетворены возможностями этого класса. Но если дело пойдет и дальше такими темпами, то класс C тоже быстро иссякнет. Самое парадоксальное заключается в том, что реально не все адреса, из выделенных пользователям сетей, реально используются. Большое число адресов пропадает из-за различного рода просчетов при организации подсетей, например, слишком широкая маска, или наоборот слишком "дальновидного планирования, когда в сеть закладывают большой запас «на вырост». Не следует думать, что эти адреса так и останутся невостребованными. Современное «железо» позволяет их утилизировать достаточно эффективно, но это стоит значительно дороже, чем простые способы, описанные выше. Одним словом, Internet, став действительно глобальной сетью, оказался зажатым в тисках своих собственных стандартов. Нужно было что-то срочно предпринимать, чтобы во время пика своей популярности не потерпеть сокрушительное фиаско.
В начале 1995 года IETF, после 3-x лет консультаций и дискуссий, выпустило предложения по новому стандарту протокола IP - IPv6, который еще называют IPing. К слову, следует заметить, что сейчас Internet-сообщество живет по стандарту IPv4. IPv6 призван не только решить адресную проблему, но и попутно помочь решению других задач, стоящих в настоящее время перед Internet.
Нельзя сказать, что до появления IPv6 не делались попытки обойти адресные ограничения IPv4. Например, в протоколах BOOTP (BOOTstrap Protocol) и DHCP (Dynamic Host Configuration Protocol) предлагается достаточно простой и естественный способ решения проблемы для ситуации, когда число физических подключений ограничено, или реально все пользователи не работают в сети одновременно. Типичной ситуацией такого сорта является доступ к Internet по коммутируемому каналу, например телефону. Ясно, что одновременно несколько пользователей физически не могут разговаривать по одному телефону, поэтому каждый из них при установке соединения запрашивает свою конфигурацию, в том числе и IP-адрес. Адреса выдаются из ограниченного набора адресов, который закреплен за телефонным пулом. IP-адрес пользователя может варьироваться от сессии. Фактически, DHCP - это расширение BOOTP в сторону увеличения числа протоколов, для которых возможна динамическая настройка удаленных машин. Следует заметить, что DHCP используют и для облегчения администрирования больших сетей, т.к. достаточно иметь только базу данных машин на одном компьютере локальной сети, и из нее загружать настройки удаленных компьютеров при их включении (под включением понимается, в данном случае не подключение к локальной компьютерной сети, а включение питания у компьютера, подсоединенного к сети).
Совершенно очевидно, что приведенный выше пример - это достаточно специфическое решение, ориентированное на специальный вид подключения к сети. Однако, не только адресная проблема определила появление нового протокола. Разработчики позаботились и о масштабируемой адресации IP-пакетов, ввели новые типы адресов, упростили заголовок пакета, ввели идентификацию типа информационных потоков для увеличения эффективности обмена данными, ввели поля идентификации и конфиденциальности информации.
Новый заголовок IP-пакета показан на рисунке 2.9.
|
|
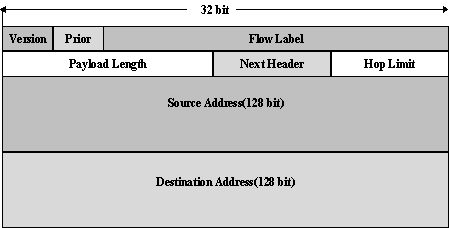
Рис. 2.9. Заголовок IPv6
В этом заголовке поле «версия» - номер версии IP, равное 6. Поле «приоритет» может принимать значения от 0 до 15. Первые 8 значений закреплены за пакетами, требующими контроля переполнения, например, 0 - несимвольная информация; 1 - информация заполнения (news), 2 - не критичная ко времени передача данных (e-mail); 4 - передача данных режима on-line (FTP, HTTP, NFS и т.п.); 6 - интерактивный обмен данными (telnet, X); 7 - системные данные или данные управления сетью (SNMP, RIP и т.п.). Поле «метка потока» предполагается использовать для оптимизации маршрутизации пакетов. В IPv6 вводится понятие потока, который состоит из пакетов. Пакеты потока имеют одинаковый адрес отправителя и одинаковый адрес получателя, и ряд других одинаковых опций. Подразумевается, что маршрутизаторы будут способны обрабатывать это поле и оптимизировать процедуру пересылки пакетов, принадлежащих одному потоку. В настоящее время алгоритмы и способы использования поля «метка потока» находятся на стадии обсуждения. Поле длины пакета определяет длину следующей за заголовком части пакета в байтах. Поле «следующий заголовок» определяет тип следующего за заголовком IP-заголовка. Заголовок IPv6 имеет меньшее количество полей, чем заголовок IPv4. Многие необязательные поля могут быть указаны в дополнительных заголовках, если это необходимо. Поле «ограничение переходов» определяет число промежуточных шлюзов, которые ретранслируют пакет в сети. При прохождении шлюза это число уменьшается на единицу. При достижении значения «0» пакет уничтожается. После первых 8 байтов в заголовке указываются адрес отправителя пакета и адрес получателя пакета. Каждый из этих адресов имеет длину 16 байт. Таким образом, длина заголовка IPv6 составляет 48 байтов.
После 4 байтов IP-адреса стандарта IPv4, шестнадцать байт IP-адреса для IPv6 выглядят достаточными для удовлетворения любых потребностей Internet. Не все 2128 адресов можно использовать в качестве адреса сетевого интерфейса в сети. Предполагается выделение отдельных групп адресов, согласно специальным префиксам внутри IP-адреса, подобно тому, как это делалось при определении типов сетей в IPv4. Так, двоичный префикс «0000 010» предполагается закрепить за отображением IPX-адресов в IP-адреса. В новом стандарте выделяются несколько типов адресов: unicast addresses - адреса сетевых интерфейсов, anycast addresses - адреса не связанные с конкретным сетевым интерфейсом, но и не связанные с группой интерфейсов и multicast addresses - групповые адреса. Разница между последними двумя группами адресов в том, что anycast address это адрес конкретного получателя, но определяется адрес сетевого интерфейса только в локальной сети, где этот интерфейс подключен, а multicast-сообщение предназначено группе интерфейсов, которые имеют один multicast-адрес. Пока IPv6 не стал злобой дня, нет смысла углубляться в форматы новых IP-адресов. Отметим только, что существующие узлы Internet будут функционировать в сети без каких-либо изменений в их настройках и программном обеспечении. IPv6 предполагает две схемы включения «старых» адресов в новые. Предполагается расширять 4-х байтовый адрес за счет лидирующих байтов до 16-и байтового. При этом, для систем, которые не поддерживают IPv6, первые 10 байтов заполняются нулями, следующие два байта состоят из двоичных единиц, а за ними следует «старый» IP-адрес. Если система в состоянии поддерживать новый стандарт, то единицы в 11 и 12 байтах заменяются нулями.
Маршрутизировать IPv6-пакеты предполагается также, как и IPv4-пакеты. Однако, в стандарт были добавлены три новых возможности маршрутизации: маршрутизация поставщика IP-услуг, маршрутизация мобильных узлов и автоматическая переадресация. Эти функции реализуются путем прямого указания промежуточных адресов шлюзов при маршрутизации пакета. Эти списки помещаются в дополнительных заголовках, которые можно вставлять вслед за заголовком IP-пакета.
Кроме перечисленных возможностей, новый протокол позволяет улучшить защиту IP-трафика. Для этой цели в протоколе предусмотрены специальные опции. Первая опция предназначена для защиты от подмены IP-адресов машин. При ее использовании нужно кроме адреса подменять и содержимое поля идентификации, что усложняет задачу злоумышленника, который маскируется под другую машину. Вторая опция связана с шифрацией трафика. Пока IPv6 не стал реально действующим стандартом, говорить о конкретных механизмах шифрации трудно.
Завершая описание нового стандарта, следует отметить, что он скорее отражает современные проблемы IP-технологии и является достаточно проработанной попыткой их решения. Будет принят новый стандарт или нет покажет ближайшее будущее. Во всяком случае, первые образцы программного обеспечения и «железа» уже существуют.
2.2.5. ICMP (Internet Control Message Protocol)
Данный протокол на ряду с IP и ARP относят к межсетевому уровню. Протокол используется для рассылки информационных и управляющих сообщений. При этом используются следующие виды сообщений:
Flow control - если принимающая машина (шлюз или реальный получатель информации) не успевает перерабатывать информацию, то данное сообщение приостанавливает отправку пакетов по сети.
Detecting unreachаble destination - если пакет не может достичь места назначения, то шлюз, который не может доставить пакет, сообщает об этом отправителю пакета. Информировать о невозможности доставки сообщения может и машина, чей IP-адрес указан в пакете. Только в этом случае речь будет идти о портах TCP и UDP, о чем будет сказано чуть позже.
Redirect routing - это сообщение посылается в том случае, если шлюз не может доставить пакет, но у него есть на этот счет некоторые соображения, а именно адрес другого шлюза.
Checking remote host - в этом случае используется так называемое ICMP Echo Message. Если необходимо проверить наличие стека TCP/IP на удаленной машине, то на нее посылается сообщение этого типа. Как только система получит это сообщение, она немедленно подтвердит его получение.
Последняя возможность широко используется в Internet. На ее основе работает команда ping.
Ix: {2} ping apollo.polyn.kiae.su
PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes
64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.401 ms
64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.844 ms
64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.807 ms
64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.912 ms
64 bytes from 144.206.160.40: icmp_seq=4 ttl=255 time=0.797 ms
64 bytes from 144.206.160.40: icmp_seq=5 ttl=255 ti^C
--- apollo.polyn.kiae.su ping statistics ---
6 packets transmitted, 6 packets received, 0% packet loss
round-trip min/avg/max = 0.797/0.930/1.401 ms
Ix: {3}
В приведенном выше примере сообщения посылаются на машину apollo.polyn.kiae.su, которая подтверждает их получение.
Другое использование ICMP - это получение сообщения о «кончине» пакета на шлюзе. При этом используется время жизни пакета, которое определяет число шлюзов, через которые пакет может пройти. Программа, которая использует этот прием, называется traceroute. К более подробному обсуждению ее возможностей мы вернемся в разделе 2.5. Здесь же только укажем, что она использует сообщение TIME EXECEED протокола ICMP.
quest:/usr/paul:\[1\]%traceroute www.netscape.com
traceroute to www3.netscape.com (205.218.156.44), 30 hops max, 40 byte packets
1 Moscow-KIAE-4.Relcom.EU.net (144.206.136.12) 7 ms 4 ms 4 ms
2 Moscow-KIAE-3.Relcom.EU.net (193.125.152.14) 5 ms 4 ms 4 ms
3 Moscow-M9-2.Relcom.EU.net (193.124.254.37) 10 ms 8 ms 10 ms
4 StPetersburg-LE-1.Relcom.EU.net
(193.124.254.33) 53 ms 24 ms
29 ms
5 Helsinki2.FI.EU.net (134.222.4.1) 33 ms 31 ms 39 ms
6 Pennsauken1.NJ.US.EU.net (134.222.228.30) 159 ms 292 ms 125 ms
7 mcinet-2.sprintnap.net (192.157.69.48) 528 ms 419 ms 400 ms
8 core2-hssi2-0.WestOrange.mci.net
(204.70.1.49) 411 ms 495 ms
397 ms
9 borderx1-fddi-1.SanFrancisco.mci.net
(204.70.158.52) 387 ms
342 ms 231 ms
10 borderx1-fddi-1.SanFrancisco.mci.net
(204.70.158.52) 264 ms
265 ms 261 ms
11 netscape.SanFrancisco.mci.net (204.70.158.110) 250 ms 262 ms 252 ms
12 205.218.156.44 (205.218.156.44) 279 ms 295 ms 299 ms
quest:/usr/paul:\[2\]%
При посылке пакета через Internet traceroute устанавливает значение TTL (Time To Live) последовательно от 1 до 30 (значение по умолчанию). TTL определяет число шлюзов, через которые может пройти IP-пакет. Если это число превышено, то шлюз, на котором происходит обнуление TTL, высылает ICMP-пакет. Traceroute сначала устанавливает значение TTL равное единице - отвечает ближайший шлюз, затем значение TTL равно 2 - отвечает следующий шлюз и т. д. Если пакет достиг получателя, то в этом случае возвращается сообщение другого типа - Detecting unreachаble destination, т.к. IP-пакет передается на транспортный уровень, а на нем нет обслуживания запросов traceroute (см. раздел 2.5).
После протоколов межсетевого уровня перейдем к протоколам транспортного уровня и первым из них рассмотрим протокол UDP.
2.2.6. User Datagram Protocol - UDP
Протокол UDP - это один из двух протоколов транспортного уровня, которые используются в стеке протоколов TCP/IP. UDP позволяет прикладной программе передавать свои сообщения по сети с минимальными издержками, связанными с преобразованием протоколов уровня приложения в протокол IP. Однако при этом, прикладная программа сама должна заботиться о подтверждении того, что сообщение доставлено по месту назначения. Заголовок UDP-датаграммы (сообщения) имеет вид, показанный на рисунке 2.10.
|
|
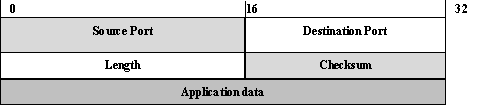
Рис. 2.10. Структура заголовка UDP-сообщения
Порты в заголовке определяют протокол UDP как мультиплексор, который позволяет собирать сообщения от приложений и отправлять их на уровень протоколов. При этом приложение использует определенный порт. Взаимодействующие через сеть приложения могут использовать разные порты, что и отражает заголовок пакета. Всего можно определить 216 разных портов. Первые 256 портов закреплены за, так называемыми «well known services», к которым относятся, например, 53 порт UDP, который закреплен за сервисом DNS.
Поле Length определяет общую длину сообщения. Поле Checksum служит для контроля целостности данных. Приложение, которое использует протокол UDP, должно само заботиться о целостности данных, анализируя поля Checksum и Length. Кроме этого, при обмене данными по UDP прикладная программа сама должна заботится о контроле доставки данных адресату. Обычно это достигается за счет обмена подтверждениями о доставке между прикладными программами.
Наиболее известными сервисами, основанными на UDP, является служба доменных имен BIND и распределенная файловая система NFS. Если возвратиться к примеру traceroute, то в этой программе также используется транспорт UDP. Собственно, именно сообщение UDP и засылается в сеть, но при этом используется такой порт, который не имеет обслуживания, поэтому и порождается ICMP-пакет, который и детектирует отсутствие сервиса на принимающей машине, когда пакет, наконец, достигает машину-адресата.
2.2.7. Transfer Control Protocol - TCP
Если для приложения контроль качества передачи данных по сети имеет значение, то в этом случае используется протокол TCP. Этот протокол еще называют надежным, ориентированным на соединение и потокоориентированным протоколом. Прежде чем обсудить эти свойства протокола, рассмотрим формат передаваемой по сети датаграммы (рисунок 2.11). Согласно этой структуре, в TCP, как и в UDP, имеются порты. Первые 256 портов закреплены за WKS, порты от 256 до 1024 закреплены за Unix-сервисами, а остальные можно использовать по своему усмотрению. В поле Sequence Number определен номер пакета в последовательности пакетов, которая составляет все сообщение, за тем идет поле подтверждения Asknowledgment Number и другая управляющая информация.
|
|
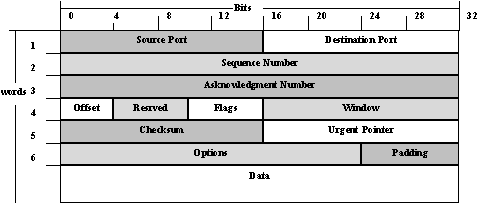
Рис. 2.11. Структура пакета TCP
Надежность TCP заключается в том, что источник данных повторяет их посылку, если только не получит в определенный промежуток времени от адресата подтверждение об их успешном получении. Этот механизм называется Positive Asknowledgement with Re-transmission (PAR). Как мы ранее определили, единица пересылки (пакет данных, сообщение и т.п.) в терминах TCP носит название сегмента. В заголовке TCP существует поле контрольной суммы. Если при пересылке данные повреждены, то по контрольной сумме модуль, вычленяющий TCP-сегменты из пакетов IP, может определить это. Поврежденный пакет уничтожается, а источнику ничего не посылается. Если данные не были повреждены, то они пропускаются на сборку сообщения приложения, а источнику отправляется подтверждение.
Ориентация на соединение определяется тем, что прежде чем отправить сегмент с данными, модули TCP источника и получателя обмениваются управляющей информацией. Такой обмен называется handshake (буквально «рукопожатие»). В TCP используется трехфазный handshake:
· Источник устанавливает соединение с получателем, посылая ему пакет с флагом «синхронизации последовательности номеров» (Synchronize Sequence Numbers - SYN). Номер в последовательности определяет номер пакета в сообщении приложения. Это не обязательно должен быть 0 или единица. Но все остальные номера будут использовать его в качестве базы, что позволит собрать пакеты в правильном порядке;
· Получатель отвечает номером в поле подтверждения получения SYN, который соответствует установленному источником номеру. Кроме этого, в поле “номер в последовательности” может также сообщаться номер, который запрашивался источником;
· Источник подтверждает, что принял сегмент получателя и отправляет первую порцию данных.
Графически этот процесс представлен на рисунке 2.12.
|
|
Рис. 2.12. Установка соединения TCP
После установки соединения источник посылает данные получателю и ждет от него подтверждений об их получении, затем снова посылает данные и т.д., пока сообщение не закончится. Заканчивается сообщение, когда в поле флагов выставляется бит FIN, что означает «нет больше данных».
Потоковый характер протокола определяется тем, что SYN определяет стартовый номер для отсчета переданных байтов, а не пакетов. Это значит, что если SYN был установлен в 0, и было передано 200 байтов, то номер, установленный в следующем пакете будет равен 201, а не 2.
Понятно, что потоковый характер протокола и требование подтверждения получения данных порождают проблему скорости передачи данных. Для ее решения используется «окно» - поле - window. Идея применения window достаточно проста: передавать данные, не дожидаясь подтверждения об их получении. Это значит, что источник предает некоторое количество данных равное window без ожидания подтверждения об их приеме, и после этого останавливает передачу и ждет подтверждения. Если он получит подтверждение только на часть переданных данных, то он начнет передачу новой порции с номера, следующего за подтвержденным. Графически это изображено на рисунке 2.13.
|
|
Рис. 2.13. Механизм передачи данных по TCP
В данном примере окно установлено в 250 байтов шириной. Это означает, что текущий сегмент - сегмент со смещением относительно SYN, равном 250 байтам. Однако, после передачи всего окна модуль TCP источника получил подтверждение на получение только первых 100 байтов. Следовательно, передача будет начата со 101 байта, а не с 251.
Таким образом, мы рассмотрели все основные свойства протокола TCP. Осталось только назвать наиболее известные приложения, которые использует TCP для обмена данными. Это в первую очередь TELNET и FTP, а также протокол HTTP, который является сердцем World Wide Web.
Прервем немного разговор о протоколах и обратим свое внимание на такую важнейшую компоненту всей системы TCP/IP как IP-адреса.
2.3. Принципы построения IP-адресов
IP-адреса определены в том же самом RFC, что и протокол IP. Именно адреса являются той базой, на которой строится доставка сообщений через сеть TCP/IP.
IP-адрес - это 4-байтовая последовательность. Принято каждый байт этой последовательности записывать в виде десятичного числа. Например, приведенный ниже адрес является адресом одной из машин РНЦ «Курчатовский Институт»:
144.206.160.32
Каждая точка доступа к сетевому интерфейсу имеет свой IP-адрес.
IP-адрес состоит из двух частей: адреса сети и номера хоста. Вообще говоря, под хостом понимают один компьютер, подключенный к Сети. В последнее время, понятие «хост» можно толковать более расширено. Это может быть и принтер с сетевой картой, и Х-терминал, и вообще любое устройство, которое имеет свой сетевой интерфейс.
Существует 5 классов IP-адресов. Эти классы отличаются друг от друга количеством битов, отведенных на адрес сети и адрес хоста в сети. На рисунке 2.14 показаны эти пять классов.
|
|
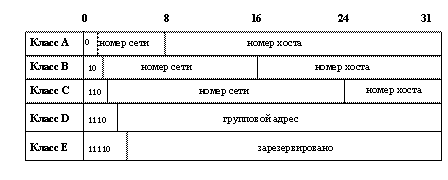
Рис. 2.14. Классы IP-адресов
Опираясь на эту структуру, можно подсчитать характеристики каждого класса в терминах числа сетей и числа машин в каждой сети.
|
Класс |
Диапазон
значений |
Возможное количество сетей |
Возможное количество узлов |
|
А |
1 - 126 |
126 |
16777214 |
|
B |
128 - 191 |
16382 |
65534 |
|
C |
192 - 223 |
2097150 |
254 |
|
D |
224 - 239 |
- |
228 |
|
E |
240 - 247 |
- |
227 |
Рис. 2.15. Характеристики классов IP-адресов
При разработке структуры IP-адресов предполагалось, что они будут использоваться по разному назначению.
Адреса класса A предназначены для использования в больших сетях общего пользования. Адреса класса B предназначены для использования в сетях среднего размера (сети больших компаний, научно-исследовательских институтов, университетов). Адреса класса C предназначены для использования в сетях с небольшим числом компьютеров (сети небольших компаний и фирм). Адреса класса D используют для обращения к группам компьютеров, а адреса класса E - зарезервированы.
Среди всех IP-адресов имеется несколько зарезервированных под специальные нужды. Ниже приведена таблица зарезервированных адресов.
|
IP-адрес |
Значение |
|
все нули |
данный узел сети |
|
номер сети | все нули |
данная IP-сеть |
|
все нули | номер узла |
узел в данной (локальной) сети |
|
все единицы |
все узлы в данной локальной IP-сети |
|
номер сети | все единицы |
все узлы указанной IP-сети |
|
127.0.0.1 |
«петля» |
Рис. 2.16. Выделенные IP-адреса
Особое внимание в таблице (рисунок 2.16) уделяется последней строке. Адрес 127.0.0.1 предназначен для тестирования программ и взаимодействия процессов в рамках одного компьютера. В большинстве случаев в файлах настройки этот адрес обязательно должен быть указан, иначе система при запуске может зависнуть (как это случается в SCO Unix). Наличие «петли» чрезвычайно удобно с точки зрения использования сетевых приложений в локальном режиме для их тестирования и при разработке интегрированных систем.
Вообще, зарезервирована вся сеть 127.0.0.0. Эта сеть класса A реально не описывает ни одной настоящей сети.
Некоторые зарезервированные адреса используются для широковещательных сообщений. Например, номер сети (строка 2) используется для посылки сообщений этой сети (т.е. сообщений всем компьютерам этой сети). Адреса, содержащие все единицы, используются для широковещательных посылок (для запроса адресов, например).
Реальные адреса выделяются организациями, предоставляющими IP-услуги, из выделенных для них пулов IP-адресов. Согласно документации NIC (Network Information Centre) IP-адреса предоставляются бесплатно, но в прейскурантах наших организаций (как коммерческих, так и некоммерческих), занимающихся Internet-сервисом предоставление IP-адреса стоит отдельной строкой.
2.4. Подсети
Важным элементом разбиения адресного пространства Internet являются подсети. Подсеть - это подмножество сети, не пересекающееся с другими подсетями. Это означает, что сеть организации (скажем, сеть класса С) может быть разбита на фрагменты, каждый из которых будет составлять подсеть. Реально, каждая подсеть соответствует физической локальной сети (например, сегменту Ethernet). Вообще говоря, подсети придуманы для того, чтобы обойти ограничения физических сетей на число узлов в них и максимальную длину кабеля в сегменте сети. Например, сегмент тонкого Ethernet имеет максимальную длину 185 м и может включать до 32 узлов. Как видно из рисунка 2.15, самая маленькая сеть - класса С - может состоять из 254 узлов. Для того, чтобы достичь этой цифры, надо объединить несколько физических сегментов сети. Сделать это можно либо с помощью физических устройств (например, репитеров), либо при помощи машин-шлюзов. В первом случае разбиения на подсети не требуется, т.к. логически сеть выглядит как одно целое. При использовании шлюза сеть разбивается на подсети (рисунок 2.17).
На рисунке 2.17 изображен фрагмент сети класса B - 144.206.0.0, состоящий из двух подсетей - 144.206.130.0 и 144.206.160.0. В центре схемы изображена машина шлюз, которая связывает подсети. Эта машина имеет два сетевых интерфейса и, соответственно, два IP-адреса.
|
|
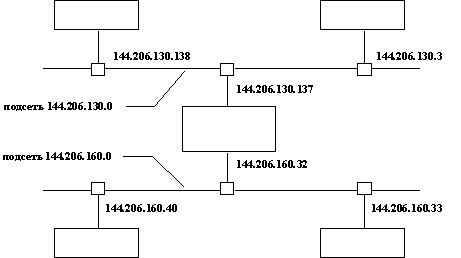
Рис. 2.17. Схема разбиения адресного пространства сети на подсети
В принципе, разбивать сеть на подсети необязательно. Можно использовать адреса сетей другого класса (с меньшим максимальным количеством узлов). Но при этом возникает, как минимум, два неудобства:
· В сети, состоящей из одного сегмента Ethernet, весь адресный пул сети не будет использован, т.к., например, для сети класса С (самой маленькой с точки зрения количества узлов в ней), из 254 возможных адресов можно использовать только 32;
· Все машины за пределами организации, которым разрешен доступ к компьютерам сети данной организации, должны знать шлюзы для каждой из сетей. Структура сети становится открытой во внешний мир. Любые изменения структуры могут вызвать ошибки маршрутизации. При использовании подсетей внешним машинам надо знать только шлюз всей сети организации. Маршрутизация внутри сети - это ее внутреннее дело.
Разбиение сети на подсети использует ту часть IP-адреса, которая закреплена за номерами хостов. Администратор сети может замаскировать часть IP-адреса и использовать ее для назначения номеров подсетей. Фактически, способ разбиения адреса на две части, теперь будет применяться к адресу хоста из IP-адреса сети, в которой организуется разбиение на подсети.
Маска подсети - это четыре байта, которые накладываются на IP-адрес для получения номера подсети. Например, маска 255.255.255.0 позволяет разбить сеть класса В на 254 подсети по 254 узла в каждой. На рисунке 2.18 приведено маскирование подсети 144.206.160.0 из предыдущего примера.
На приведенной схеме (рисунок 2.18) сеть класса B (номер начинается с 10) разбивается на подсети маской 255.255.224.0. При этом первые два байта задают адрес сети и не участвуют в разбиении на подсети. Номер подсети задается тремя старшими битами третьего байта маски. Такая маска позволяет получить 6 подсетей. Для нумерации подсети нельзя использовать номер 000 и номер 111. Номер 160 задает 5-ю подсеть в сети 144.206.0.0. Для нумерования машин в подсети можно использовать оставшиеся после маскирования 13 битов, что позволяет создать подсеть из 8190 узлов. Честно говоря, в настоящее время такой сети в природе не существует и РНЦ «Курчатовский Институт», которому принадлежит сеть 144.206.0.0, рассматривает возможность пересмотра маски подсетей. Перестроить сеть, состоящую из более чем 400 машин, не такая простая задача, так как ей управляет 4 администратора, которые должны изменить маски на всех машинах сети. Ряд компьютеров работает в круглосуточном режиме и все изменения надо произвести в тот момент, когда это минимально скажется на работе пользователей сети. Данный пример показывает насколько внимательно следует подходить к вопросам планирования архитектуры сети и ее разбиения на подсети. Многие проблемы можно решить за счет аппаратных средств построения сети.
|
|

Рис. 2.18. Схема маскирования и вычисления номера подсети
К сожалению, подсети не только решают, но также и создают ряд проблем. Например, происходит потеря адресов, но уже не по причине физических ограничений, а по причине принципа построения адресов подсети. Как было видно из примера, выделение трех битов на адрес подсети не приводит к образованию 8-ми подсетей. Подсетей образуется только 6, так как номера сетей 0 и 7 использовать в силу специального значения IP-адресов, состоящих из 0 и единиц, нельзя. Таким образом, все комбинации адресов хоста внутри подсети, которые можно было бы связать с этими номерами, придется забыть. Чем шире маска подсети (чем больше места отводится на адрес хоста), тем больше потерь. В ряде случаев приходится выбирать между приобретением еще одной сети или изменением маски. При этом физические ограничения могут быть превышены за счет репитеров, хабов и т. п.
2.5. Порты и сокеты
После того, как мы разобрались с основными протоколами и IP-адресами, не плохо было бы понять, как все это вместе стыкуется и работает. В заголовках протоколов нет наименований протоколов, а есть только номера. Кроме того, данные каждому приложению также доставляются с использованием номеров, которые называются портами. Пара - протокол и порт - позволяет стеку протоколов TCP/IP доставить данные нуждающемуся в них приложению. Увидеть номера протоколов можно в файле /etc/protocols или прочитать в RFC Assigned Numbers.
Содержание файла /etc/protocols:
Ix: {3} more protocols
#
# Internet (IP) protocols
#
# $Id: protocols,v 1.2.8.1 1995/08/30 06:19:30 davidg Exp $
# from: @(#)protocols 5.1 (Berkeley) 4/17/89
#
# Updated for FreeBSD based on RFC 1340, Assigned Numbers (July 1992).
#
ip 0 IP # internet protocol, pseudo protocol number
icmp 1 ICMP # internet control message protocol
igmp 2 IGMP # Internet Group Management
ggp 3 GGP # gateway-gateway protocol
ipencap 4 IP-ENCAP # IP encapsulated in IP (officially «IP»)
st 5 ST # ST datagram mode
tcp 6 TCP # transmission control protocol
egp 8 EGP # exterior gateway protocol
pup 12 PUP # PARC universal packet protocol
udp 17 UDP # user datagram protocol
hmp 20 HMP # host monitoring protocol
xns-idp 22 XNS-IDP # Xerox NS IDP
rdp 27 RDP # «reliable datagram» protocol
iso-tp4 29 ISO-TP4 # ISO Transport Protocol class 4
xtp 36 XTP # Xpress Tranfer Protocol
idpr-cmtp 39 IDPR-CMTP # IDPR Control Message Transport
rsvp 46 RSVP # Resource ReSerVation Protocol
vmtp 81 VMTP # Versatile Message Transport
ospf 89 OSPFIGP # Open Shortest Path First IGP
ipip 94 IPIP # Yet Another IP encapsulation
encap 98 ENCAP # Yet Another IP encapsulation
Как видно из содержания файла protocols, практически всем основным протоколам присвоены номера. Другой группой магических цифр являются номера портов, которые закреплены за информационными сервисами Internet.
Информационный сервис - это прикладная программа, которая осуществляет обслуживание на определенном порте TCP или UDP. Собственно WKS - это и есть совокупность этих сервисов Internet. К сервисам относятся: доступ в режиме удаленного терминала, доступ к файловым архивам FTP, доступ к серверам World Wide Web и т. п. Распределение сервисов по портам можно найти в файле /etc/services. Сам файл сервисов очень большой, поэтому приведем только небольшой его фрагмент с наиболее интересными и популярными сервисами.
Фрагмент содержания файла /etc/services:
quest:/etc:\[2\]>cat services
tcpmux 1/tcp # TCP port service multiplexer
echo 7/tcp
echo 7/udp
...
ftp 21/tcp
# 22 - unassigned
telnet 23/tcp
# 24 - private
smtp 25/tcp mail
# 26 - unassigned
time 37/tcp timserver
time 37/udp timserver
rlp 39/udp resource # resource location
whois 43/tcp nicname
domain 53/tcp nameserver # name-domain server
domain 53/udp nameserver
bootps 67/tcp # BOOTP server
bootps 67/udp
bootpc 68/tcp # BOOTP client
bootpc 68/udp
tftp 69/udp
gopher 70/tcp # Internet Gopher
gopher 70/udp
finger 79/tcp
www 80/tcp http # WorldWideWeb HTTP
www 80/udp # HyperText Transfer Protocol
Среди сервисов, определенных в этом фрагменте, есть не только информационные сервисы типа World Wide Web или Gopher, но и протокол маршрутизации RIP, и протокол удаленной загрузки bootp, и сервис доменных имен BIND, и другие протоколы, которые нацелены на повышение работы сети и чрезвычайно полезны при администрировании сети.
При работе через стек протоколов TCP/IP сообщения, которыми обмениваются приложения, сначала инкапсулируются в сегменты TCP или дейтаграммы UDP, при этом указывается соответствующий порт транспортного протокола. Потом транспортные протоколы мультиплексируются в IP, который запоминает номер протокола. Все IP-пакеты передаются по сети получателю, где происходит обратная операция изъятия информации из оболочки TCP/IP. Сначала по номеру протокола в модуле IP выделенные данные пересылаются соответствующему протоколу транспортного уровня. На транспортном уровне по номеру порта получателя определяется, какому сервису данные посланы. Все это графически изображено на рисунке 2.19.
|
|

Рис. 2.19. Использование
номеров портов и номеров протоколов для
передачи данных
Однако, этим механизм взаимодействия приложений в рамках TCP/IP не исчерпывается. Дело в том, что кроме статически назначенных WKS существуют еще динамически назначаемые сервисы.
Динамически назначаемые номера портов TCP и UDP используются для того, чтобы можно было организовать обслуживание множества запросов по сети к одному WKS. В том же примере стрелочки только в одном направлении указаны не случайно. К серверу протокола HTTP могут обращаться сразу несколько клиентов, следовательно, должен быть механизм, который бы позволил распараллелить их обслуживание. Таким механизмом служит динамическое назначение портов (рисунок 2.20). Происходит это назначение в момент установки соединения. Клиент, запрашивая обслуживание, обращается к сервису по номеру порта WKS, но при этом сообщает, что принимать ответы он будет по номеру порта, отличному от WKS. Таким образом, сервер может обслуживать запросы к одному и тому же порту WKS, используя разные порты при ответе. Образующаяся при этом пара (IP-адрес, номер порта) называется сокетом (буквально “розетка”). Таким образом, можно сказать, что http-сервер для обслуживания использует сокет, например, 144.206.130.137;80, а клиент, который к нему обращается, сокет 144.206.130.138;8080. Графически определение сокета можно продемонстрировать на примере протокола TCP.
|
|
Рис. 2.20. Динамическое назначение портов. Образование сокетов
Описывая взаимодействие в рамках TCP/IP обмена, мы до сих пор обходили стороной вопросы, связанные с тем, как пакет реально транспортируется по сети. Все наши примеры ограничивались работой в рамках локальной сети. Теперь пора поговорить о том, как осуществляется передача пакетов по сети, или в терминах сетевого обмена - маршрутизация.
2.6. Основные принципы IP-маршрутизации
Как уже было сказано раньше, протокол IP не является протоколом, ориентированным на соединение. Следовательно, решение о направлении IP-пакета на тот или иной сетевой интерфейс принимается шлюзом в момент прохождения через него пакета. Данное решение принимается на основании таблицы маршрутов, имеющейся на каждом компьютере, который поддерживает стек протоколов TCP/IP.
Прежде чем перейти к описанию самой процедуры, введем пример сети, на которой будем рассматривать маршрутизацию пакетов (рисунок 2.21).
|
|

Рис. 2.21. Пример фрагмента локальной сети
На рисунке 2.21 изображены два фрагмента подсетей (144.206.160.0 и 144.206.128.0) сети класса B (144.206.0.0). Машина с интерфейсами, которые имеют адреса 144.206.160.32 и 144.206.130.137 - это шлюз между двумя подсетями, а машина с адресом сетевого интерфейса 144.206.130.3 - это шлюз сети с другой сетью, которая подключена к Internet.
Рассмотрим сначала путь пакета от машины с адресом 144.206.160.40 к машине с адресом 144.206.160.33. Предположим, что к этой машине пользователь 144.206.160.40 еще не обращался. В рамках такого обмена машине достаточно знать только свой IP-адрес. Прежде чем отправить пакет, модуль ARP проверит, существует ли соответствие между IP-адресом получателя и физическим адресом какого-либо интерфейса включенного в локальную сеть. В нашем случае такого соответствия еще нет, поэтому в сеть будет отправлен широковещательный запрос на получение физического адреса по заданному IP-адресу. В ответ машина 144.206.160.33 сообщит свой адрес, после чего пакет будет отправлен в сеть. В поле физического адреса в фрейме протокола канального уровня будет указан адрес машины 144.206.160.33. Вообще говоря, такая процедура была разработана для Ethernet, но в последнее время ARP стали применять и для других физических сред, в частности, для FrameRelay.
Теперь отправим пакет машине из другой подсети 144.206.130.138. В этом случае на широковещательный запрос мы ответа не получим. Но пакет отправлять как-то надо. Для этой цели в описании маршрутов пакетов всегда есть IP-адрес, на который следует отправлять пакеты по умолчанию, если нет другого способа их рассылки. Естественно, что это адрес шлюза. Для машины 144.206.160.40 таким адресом является адрес 144.206.160.32. Физический адрес этого интерфейса получают точно также, как мы до этого получили физический адрес интерфейса 144.206.160.33. Принципиальное различие здесь заключается в том, что в первом случае адреса получателя и отправителя во фрейме физического протокола совпадали с адресами, которые указаны для IP-адресов из IP-пакета в таблице ARP. В случае шлюза здесь можно обнаружить несоответствие. Во фрейме в качестве получателя будет указан адрес интерфеса 144.206.160.32, в то время как в IP-пакете будет указан IP-адрес 144.206.130.138. Но ведь этому IP-адресу соответствует совсем другой физический адрес. Если быть более точным, то другой адрес будет соответствовать в сети Ethernet, если же речь идет о FrameRelay, то там может применяться относительная система адресации, что может приводить к равенству физических адресов.
Получив таким образом пакет, модуль IP машины шлюза определяет, что это не его адрес указан в IP-пакете. После такого открытия IP-модуль шлюза принимает решение о дальнейшей отправке пакета. Отправлять пакет в тот же интерфейс, из которого он получен - бессмысленно, поэтому модуль IP никогда не отправляет пакеты назад. Следовательно, происходит поиск нужного интерфейса и через него снова рассылается широковещательный запрос ARP. В нашем случае такой запрос вернет для IP-адреса 144.206.130.138 физический адрес машины, и пакет будет отправлен по этому адресу.
Если пакет отправляется в Internet, то шлюз не найдет физического адреса машины, и будет вынужден воспользоваться адресом рассылки по умолчанию. Таким образом, пакет попадет на шлюз через 144.206.130.3, и там будет решаться его судьба.
При рассмотрении стека протоколов TCP/IP на компьютере с одним сетевым интерфейсом было не очень понятно, зачем IP дублирует физический адрес, например, Ethernet, ведь каждому адресу Ethernet ставился в соответствие один IP-адрес. При рассмотрении архитектуры стека протоколов шлюза этот вопрос становится более понятным.
Из рисунка 2.22 видно, что таблица ARP создается для каждого интерфейса. Для получения таких таблиц можно использовать команду arp, где в качестве аргумента надо указать имя интерфейса. Модуль IP для шлюза общий и таблица маршрутов, а именно, она и используется модулем для перенаправления пакетов на интерфейсы, также общая.
Прежде чем перейти к описанию таблицы маршрутов и способам управления ею, обратим свое внимание на способы настройки сетевых интерфейсов, т.к. без них никакой стек протоколов работать с сетью не будет.
|
|

Рис. 2.22. Архитектура шлюза 144.206.130.137-144.206.160.32
2.7. Настройка операционной системы и сетевые интерфейсы
Прежде чем начать описание настроек сетевых интерфейсов, обратим свое внимание на особенности операционной системы, которая должна работать с сетью TCP/IP. Чаще всего при этом подразумевается операционная система Unix. Мы не будем отступать от этой традиции. Рассмотрим настройку ОС вручную, а не с использованием диалоговых средств, которые широко применяются в HP-UX, IRIX, SCO и т. п. В Unix все равно все сводится к выполнению тех же самых команд, но только программами или скриптами. Администратор всегда может воспользоваться интерфейсом командной строки, чтобы поправить настройки, выполненные ранее рекомендованными в руководстве по администрированию средствами.
Для того, чтобы система работала со стеком протоколов TCP/IP необходимо соответствующим образом настроить ядро системы. В системах клона BSD конфигурация определяется в фале типа /usr/sys/conf, Например, во FreeBSD 2.x, - это файл /sys/i386/conf/GE-NERIC, если речь идет о только что установленной системе.
Обычно, на основе этого файла делают копию, которую называют local, и в этой копии проводят изменения настроек. В этом файле следует определить, чаще всего раскомментировать, строки, которые определяют сетевые интерфейсы, например, ed0 или ed1, если речь идет о Ethernet. Кроме этого, если машина будет работать шлюзом, нужно указать опцию GATEWAY, если нужно использовать распределенную файловую систему, то нужно заказать также соответствующие опции. Для таких протоколов, как SLIP и PPP, нужно определить еще и псевдоустройства. Ниже приведен пример такого файла конфигурации, точнее фрагмент.
Файл конфигурации ядра FreeBSD 2.x.
quest:/usr/src/sys/i386/conf:\[6\]>cat QUEST
options NFS #Network File System
options GATEWAY #Host is a Gateway (forwards packets)
device sio0 at isa? port «IO_COM1» tty irq 4 vector siointr
device sio1 at isa? port «IO_COM2» tty irq 3 vector siointr
device lpt0 at isa? port? tty irq 7 vector lptintr
device ed0 at isa? port 0x280 net irq 9 iomem 0xd8000 vector edintr
device ed1 at isa? port 0x300 net irq 5 iomem 0xd8000 vector edintr
pseudo-device loop
pseudo-device ether
pseudo-device log
pseudo-device sl 2
Из этого фрагмента видно, что данная машина позволяет работать с распределенной файловой системой, является шлюзом, имеет два сетевых интерфейса Ethernet: ed0 и ed1, а также еще два интерфейса на последовательных портах: sl0 и sl1, что соответствует портам sio0 и sio1.
Для того, чтобы данная конфигурация была реализована, надо пересобрать ядро. Для этого выполняется процедура генерации make-файлов, и после этого выполняется программа make. Как только новое ядро собрано, его можно копировать в корень на место существующего ядра, но при этом надо не забыть сохранить старое ядро. Обычно Unix позволяет указать при загрузке имя файла ядра, что позволит загрузиться на машине, новое ядро которой оказалось неработоспособным.
В системах клона System 5, настройки ядра распределены по многим фалам. Здесь лучше воспользоваться стандартными средствами конфигурации типа SAM в HP-UX, т.к. можно просто забыть что-нибудь подправить.
При настройках Windows NT систему можно сконфигурировать для работы с сетями TCP/IP как при установке, так и потом, по мере необходимости. Правда, отложенная конфигурация приведет к перезагрузке системы. Настраивается сеть из меню network в меню control panel. Там также определяется тип интерфейса и копируется с дистрибутива драйвер для данного интерфейса. Потом для интерфейса определяется семейство протоколов, где среди протоколов Microsoft можно найти и TCP/IP. Далее интерфейсу назначается IP-адрес, определяется шлюз и сервер доменных имен. Другие параметры, типа сервиса WINS (Windows Internet Name System), мы рассматривать не будем, т.к. это касается только Windows, а не Internet вообще.
При установке стека TCP/IP на машины с операционной системой MS-DOS следует иметь в виду, что здесь надо установить все выше описанное, но только в отличии от выше перечисленных операционных систем все программное обеспечение является прикладными задачами, а не частью операционной системы, поэтому никакой перенастройки ядра не происходит. Общая схема машины с OC MS-DOS, поддерживающей стек TCP/IP будет выглядеть так, как показано на рисунке 2.23.
|
|

Рис. 2.23. Структура стека программного обеспечения для поддержки стека протоколов TCP/IP на персональном компьютере
Естественно, что все эти модули, которые представлены на рисунке 2.23, должны быть указаны в файлах config.sys и autoexec.bat. Примеры содержания файлов autoexec.bat и config.sys приведены ниже и основаны они на настройке персонального компьютера notebook, который работает с сетью либо через сетевой PCMCI-адаптер Ethernet, либо через PCMCI-модем, что и отражено в вариантной загрузке.
Пример файла autoexec.bat
@ECHO OFF
set tz=MSK
set temp=c:\temp
set tmp=c:\temp
PATH C:\WINWORD;C:\;C:\NC5;C:\WINDOWS;C:\DOS;C:\UT;C:\ME;c:\spelchek\g4;c:\spelchek\logs;c:\photo;
goto %config%
:Network
PATH %PATH%c:\network\tel;c:\network\xfs;
:Dial-in
:Local
LH CYRILLIC
LH C:\DOS\SHARE.EXE /l:500 /f:5100
nc
При работе через сетевой адаптер все интерфейсы устанавливаются только в config.sys, а в autoexec.bat подправляется только переменная окружения PATH.
Содержание файла config.sys
[menu]
menuitem=Local, Load Computer without any drivers.
menuitem=Network, Start Computer with Ethernet Network Conection.
menuitem=Dial-in, Start Computer in Local Mode with Dial-in Connection.
[common]
rem common statments
[Local]
rem ordinal
[Network]
rem network interface installation
device=c:\network\pktdrv\accopen.exe /int=5 /port=300 /mem=0000
DEVICE=C:\DOS\HIMEM.SYS
DEVICE=c:\dos\emm386.exe noems
[Dial-in]
DEVICE=C:\DOS\HIMEM.SYS
DEVICE=c:\dos\emm.386.exe noems
; PCMCI modem
DEVICEHIGH=C:\PCMCIA\SSVADEM.SYS
DEVICEHIGH=C:\PCMCIA\AMICS.SYS
DEVICEHIGH=C:\PCMCIA\PCMODEM.SYS
Впрочем, для различных систем и для различных пакетов, настройки могут довольно сильно отличаться, но структура всегда будет одной и той же.
Таким образом, после сборки нового ядра в системах Unix и Windows NT, или после выполнения настройки MS-DOS в системе появляются сетевые интерфейсы, стек протоколов TCP/IP и возможность совместной настройки интерфейсов и стека протоколов.
2.8. Настройка сетевых интерфейсов
Настройкой сетевых интерфейсов называют определение параметров обмена данными через сетевой интерфейс и присвоение ему IP-адреса. Сначала разберем, как это делается для интерфесов Ethernet, а потом уже для последовательных портов.
2.8.1. Настройка Ethernet-интерфейса
В данном случае никаких параметров настраивать не надо. Следует только назначить IP-адрес. Делается это по команде ifconfig:
/usr/paul>ifconfig ed0 inet 144.206.130.138 netmask 255.255.224.0
В данном случае интерфесу ed0 назначается адрес 144.206.130.138, при этом на сети установлена маска 255.255.224.0. В общем случае команда ifconfig имеет следующий формат:
ifconfig interface address_family [address [dest_address]] [parameters]
В этой команде параметры означают следующее:
interface - имя сетевого интерфейса;
address_famaly - тип адреса. В нашем случае - это inet, т.е. адрес Internet. Данное значение задается по умолчанию;
address - IP-адрес источника. Обычно в этом поле указывают IP-адрес который назначается сетевому интерфейсу. Если речь идет об интерфейсе Ethernet то этого адреса достаточно для его настройки.
dest_address - IP-адрес получателя. Данный адрес указывается для интерфейсов типа «точка-точка», например, для SLIP (sl0) или PPP (ppp0). В таких соединениях к концам линии связи подключены только два интерфейса, и надо задать адрес обоих. В предыдущем поле (address) задают адрес своего интерфейса, а в данном поле интерфейса, установленного на другом конце линии.
В качестве параметров можно указать маску сети, как это сделано в примере. Этот параметр - обязательный. Существуют и другие параметры, например адрес широковещания, но их используют редко и обычно в данном случае их значения назначаются по умолчанию, так, например, адрес широковещания по умолчанию ограничен локальной сетью, и это правильно, т.к. нет нужды “светиться” за пределами своего шлюза.
Команда ifconfig может быть использована и для получения информации об интерфейсе. Для этого в ней надо указать только имя:
quest:/usr/src/sys/i386/conf:\[14\]>ifconfig ed1
ed1: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX>
inet 144.206.130.138 netmask ffffe000 broadcast 144.206.159.255
quest:/usr/src/sys/i386/conf:\[15\]>
В данном случае была запрошена информация об интерфейсе ed1. Из отчета видно, какие флаги установлены для данного интерфейса и какой адрес ему назначен. С точки зрения администратора важно, что этот интерфейс в данный момент работоспособен (флаг UP) и не используется для сканирования пакетов в сети. Сканированию пакетов мы уделим достаточно внимания в разделе, посвященном вопросам безопасности сети.
Однако более исчерпывающую статистику можно получить при помощи команды netstat:
quest:/usr/src/sys/i386/conf:\[19\]>netstat -ain
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
ed0 1500 <Link>0.0.1b.12.32.46 52848 0 45380 0 0
ed0 1500 144.206.192 144.206.192.1 52848 0 45380 0 0
ed1 1500 <Link>0.0.1b.12.32.32 659682 2354 45708 276 4423
ed1 1500 144.206.128 144.206.130.138 659682 2354 45708 276 4423
lo0 65535 <Link> 138 0 138 0 0
lo0 65535 127 127.0.0.1 138 0 138 0 0
sl0* 296 <Link> 0 0 0 0 0
sl1* 296 <Link> 0 0 0 0
В данном отчете перечислены все сетевые интерфейсы, минимальные размеры фреймов, которые могут передаваться через них, сети и IP-адреса данного хоста на этих сетях, сколько пакетов через интерфейс было принято, сколько из них было поврежденных, сколько пакетов было отправлено и сколько из них было поврежденных и, в заключении, число коллизий, зарегистрированное интерфейсом. Кроме того, в данном отчете указаны еще и Ethernet-адреса интерфейсов.
Кроме этого, следует обратить внимание интерфейс lo0, который закреплен за петлей 127.0.0.1. Для этого интерфейса также нужна команда ifconfig.
/usr/paul> ifconfig lo0 inet localhost
В данном случае имя localhost будет заменено на 127.0.01.
Но Ethernet - это только один из интерфейсов, которые могут быть использованы при подключении к сети. Кроме него довольно популярны интерфейсы подключения через последовательные порты.
2.8.2. Настройка SLIP
С последовательным портом работают через псевдоустройство sl0, которое и является интерфейсом последовательного порта. Для сцепления sl0 c устройством служит команда slattach:
/usr/paul/slattach /dev/cuaa0 144.206.160.100 144.206.160.101
Однако, формат slattach от одной системы к другой существенно изменяется. Так в ряде случаев сначала выдается команда slattach, которая присоединяет интерфейс к порту, а затем на нее выдается команда ifconfig для интерфейса sl.
/usr/paul>slattach -c -s 38400 /dev/sio01
/usr/paul>ifconfig sl1 inet 144.206.160.100 144.206.160.101 netmask 255.255.224.0
В данном случае определен интерфейс для обмена данными по протоколу SLIP с компрессией, со скоростью на порту 38400, через порт /dev/sio01.
Как показывает практика, доступ по протоколу SLIP обычно организуют для удаленных пользователей, которые через данный шлюз хотят работать с Internet. Однако, не всегда можно «зацепиться» за модем надежно. Кроме того, на одном и том же порту могут обслуживаться как терминальные пользователи, так и пользователи Internet, а кроме того, туда же можно подключать и пользователей UUCP. В этом случае гораздо разумнее вместо slattach воспользоваться командой sliplogin. Данная команда также имеется не во всех операционных системах. Но обычно во всех есть ее аналог.
Суть sliplogin заключается в том, что пользователь, который дозвонился и работает в режиме удаленного терминала, имеет возможность самостоятельно запустить из этого режима присоединение sl интерфейса и его настройку на IP-адреса и параметры сессии. Это же дает возможность провайдерам, устанавливая стеки TCP/IP на персональных компьютерах, включать в их настройки скрипты, которые автоматически производят аутентификацию в удаленной машине и конфигурирование интерфейса для работы по SLIP.
Выглядит это следующим образом:
· сначала дозваниваются до удаленной машины;
· затем вводят идентификатор и пароль;
· после входа в режим командной строки запускается команда sliplogin;
· после этого следует перейти в режим работы по SLIP.
Из этого режима обычно самостоятельно не выходят: либо обрывается связь, либо происходит какое-нибудь другое чрезвычайное событие. Поэтому систему настраивают таким образом, чтобы она сама завершала задачу и клала трубку на модеме.
Sliplogin управляется тремя файлами slip.hosts, slip.login и slip.logout. В файле slipl.host перечисляются пользователи, которым разрешено запускать sliplogin, и какие адреса при этом назначаются, а также тип протокола SLIP (с компрессией или без нее). Ниже приведен пример такого файла:
quest:/etc:\[7\]>cat slip.hosts
paul 144.206.192.99 144.206.192.100 255.255.224.0
; alex 144.206.130.138 144.206.192.102 255.255.224.0 compress
dimag 144.206.192.99 144.206.192.103 255.255.224.0
dima 144.206.192.99 144.206.192.104 255.255.224.0
vovka 144.206.192.99 144.206.192.105 255.255.224.0
maverick 144.206.192.99 144.206.192.106 255.255.224 0
arch1996 144.206.192.99 144.206.192.107 255.255.224.0
Однако, этого мало. Фактически, sliplogin выполняет slattach на порт, через который работает пользователь, но после этого этот порт надо сконфигурировать. Для этой цели служит скрипт slip.login:
quest:/etc:\[8\]>cat slip.login
#!/bin/sh
/sbin/ifconfig sl$1 $4 $5 netmask $6 >> /tmp/sliplogin.log
exit 0
quest:/etc:\[9\]>
После того, как соединение разорвалось, следует убрать все процессы которые им были вызваны. Для этой цели служит скрипт sliplogout.
quest:/etc:\[9\]>cat slip.logout
#!/bin/sh
PATH=:/bin:/sbin:/usr/bin:/usr/sbin:
export PATH
(ps ax | egrep 'sliplogin | slattach' | grep $3 |grep -v grep | awk '{print $1;}' | xargs kill ) >> /tmp/sliplogin.log
quest:/etc:\[10\]>
Смысл написанного в этом файле заключается в том, что бы найти все остатки от sliplogin и по команде kill прервать их выполнение.
Однако для выделенных телефонных каналов обычно применяется другой протокол, а именно PPP.
2.8.3. Настройка интерфейса PPP
В различных системах настройка интерфейсов PPP производится по-разному. Поэтому мы снова будем основываться на примере BSDI и FreeBSD. Для работы через PPP в этих системах используется либо демон pppd, либо прикладная программа ppp. Обычно демон используется для выделенных линий и для приема звонков на выделенном под PPP порте. Программа ppp используется для запуска из командной строки.
Для того, чтобы использовать демона в файле конфигурации ядра, необходимо определить псевдоустройство ppp(0-1). Демона помещают в файл начальной загрузки. Настройки демона производятся при помощи файла настроек:
vega-gw: {6} cat options
/dev/cuaa2
57600
194.190.135.22:194.190.135.21
netmask 255.255.255.252
passive
defaultroute
#debug
local
#kdebug 7
В данном примере мы используем файл /etc/ppp/options. В нем определяется порт, через который настраивается интерфейс, скорость на порте, адрес интерфейса и адрес ответного интерфейса провайдера, маска, установленная на сети провайдера, команда passive, которая заставляет оставлять данный интерфейс постоянно в таблице маршрутов, определение его как шлюза по умолчанию, и определяет его управление с локальной машины. Кроме этого, в данном файле есть еще и закомментированные опции, которые использовались автором во время отладки соединения. Включение этих двух опций приводит к полному дампированию пакетов PPP, что позволяет выяснить причины отсутствия соединения или плохого соединения.
В данном случае мы отлаживали соединение с relarn, где на конце relarn пакеты принимал маршрутизатор CISCO.
Если надо устанавливать соединение с удаленной машины со шлюзом, то вместо SLIP можно также использовать PPP. Но только в этом случае лучше всего использовать программу ppp. Она также настраивается через свой файл конфигурации, пример которого приведен ниже:
vega-gw: {7} cat ppp.conf
default:
set device /dev/cuaa0
set speed 38400
disable lqr
deny lqr
# set debug level LCP
relarn:
set ifaddr 194.190.135.22 194.190.135.21
add 0 255.255.255.252 194.190.135.21
Надеюсь, что значение параметров в этом файле понятно и без лишних комментариев.
Главной особенностью программы ppp является то, что ее можно запустить в интерактивном режиме, по мере ее работы менять тип информации, который подлежит отладке.
При использовании и ppp, и pppd команды ifconfig на интерфейсы выдавать не надо, т.к. эти команды сами производят их настройку.
В заключение разговора о настройке интерфейсов приведем пример таблицы интерфейсов с машины, где работает сразу три разных интерфейса:
vega-gw: {9} netstat -ain
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
ed1 1500 <Link>00.20.c5.00.35.c4 10574 0 10223 0 2
ed1 1500 194.226.43 194.226.43.1 10574 0 10223 0 2
lp0* 1500 <Link> 0 0 0 0 0
lo0 16384 <Link> 357 0 357 0 0
lo0 16384 127 127.0.0.1 357 0 357 0 0
ppp0 1500 <Link> 58000 0 55347 0 0
ppp0 1500 194.190.135 194.190.135.22 58000 0 55347 0 0
ppp1* 1500 <Link> 0 0 0 0 0
sl0* 552 <Link> 20570 1 21281 0 0
sl0* 552 194.226.43 194.226.43.99 20570 1 21281 0 0
sl1* 552 <Link> 0 0 0 0 0
tun0* 1500 <Link> 0 0 0 0 0
В этой таблице можно найти интерфейс Ethernet (ed1), интерфейс PPP (ppp0) и интерфейс SLIP (sl1), которые находятся в активном состоянии и принимают и отправляют пакеты.
Через интерфейс ed1 (IP-адрес: 144.226.43.1) доступна сеть 144.226.43.0, через интерфейс ppp0 (IP-адрес: 194.190.135.22) доступна сеть 144.190.135.0, которая является путем в Internet, через sl0 (IP-адрес: 194.226.43.99) работает удаленный пользователь.
2.9. Маршрутизация, протоколы динамической маршрутизации, средства управления маршрутами
Во всех предыдущих разделах сам механизм управления маршрутами, порождения пакетов по сети старательно обходился стороной, т.к. это предмет особого разговора. Программы управления маршрутами довольно сложны, а функции, которые они выполняют, являются критичными для всей системы в целом.
Основывается система маршрутизации на таблице маршрутов, которая определяет куда пакет с данным IP-адресом следует направлять. Ниже приведен пример такой таблицы, полученный при помощи команды netstat.
Пример 2.1. Таблица маршрутов
quest:/usr/src/sys/i386/conf:\[16\]>netstat -rn
Routing tables
Destination Gateway Flags Refs Use IfaceMTU Rtt
Netmasks:
(root node)
(0) 0000 ff00
(0) 0000 ffff e000
(root node)
Route Tree for Protocol Family inet:
(root node) =>
default 144.206.136.12 UG 1 1081 ed1 - -
127 127.0.0.1 UR 0 0 lo0 - -
127.0.0.1 127.0.0.1 UH 0 51 lo0 - -
144.206 144.206.131.5 UG 0 0 ed1 - -
144.206.64 144.206.136.230 UG 0 0 ed1 - -
144.206.96 144.206.130.135 UG 0 0 ed1 - -
144.206.128 144.206.130.138 U 2 9900 ed1 - -
144.206.192 144.206.192.1 U 2 26203 ed0 - -
194.226.56 144.206.130.207 UGD 0 0 ed1 - -
(root node)
quest:/usr/src/sys/i386/conf:\[17\]>
В данном примере в левой колонке указаны адреса возможных IP-адресов, которые система принимает из сети, далее идет адрес шлюза для данных адресов, затем флаги маршрутизации, степень использования данного маршрута и интерфейс, на котором данный маршрут обслуживается.
Однако, наша таблица не дает ответа на степень изменчивости данной таблицы. Для этого нам придется снова вернуться к изучению протоколов, но только теперь уже протоколов маршрутизации.
2.9.1. Статическая маршрутизация
В принципе, возможна работа без применения вообще каких-либо протоколов маршрутизации. В этом случае маршрутизацию называют статической. Таблица маршрутов в этом случае строится при помощи команд ifconfig, которые вписывают строки, отвечающие за рассылку сообщений в локальной сети, и команды route, которая используется для внесения изменений вручную.
Вообще говоря, из всей статической маршрутизации выделяют, так называемую, минимальную маршрутизацию. Такая маршрутизация возникает тогда, когда локальная сеть не имеет выхода в Internet и не состоит из подсетей. В этом случае достаточно выполнить команды ifconfig для интерфейса lo и интерфейса Ethernet и все будет работать:
/usr/paul>ifconfig lo inet 127.0.0.1
/usr/paul>ifconfig ed1 inet 144.226.43.1 netmask 255.255.255.0
В таблице маршрутов появятся только эти две строки, но так как сеть ограничена, и пакеты не надо отправлять в другие сети, то модуль ARP будет прекрасно справляться с доставкой пакетов по сети.
Если же сеть подключена к Internet, то в таблицу маршрутов надо ввести, по крайней мере, еще одну строку - адрес шлюза. Делается это при помощи команды route.
Команда route имеет следующий вид:
route <команда> <сеть или хост> <шлюз> <метрика>
В поле «команда» указывается команда работы с таблицей маршрутов:
· add - добавить маршрут
· delete - удалить маршрут;
· get - получить информацию о маршруте.
В поле «сеть или хост» указывается адрес отправки пакета.
В поле «шлюз» указывается IP-адрес, через который следует отправлять пакеты, предназначенные хосту или сети из предыдущего поля.
Поле «метрика» определяет расстояние в числе шлюзов, которые данный пакет пройдет, если его направить по данному маршруту.
Типичным примером применения команды route является назначение шлюза по умолчанию:
/usr/paul>route add default 144.206.160.32
В данном примере все пакеты, адресаты которых не были найдены в локальной сети, отправляются на сетевой интерфейс с адресом 144.206.160.32. Метрика при этом принимается по умолчанию равная 1. Таким образом, указывается, что это адрес шлюза.
Для того, чтобы получить таблицу маршрутов, приведенную в примере 2.1, нужно выполнить следующие команды:
/usr/paul>route add 144.206.0.0 144.206.136.5 netmask 255.255.224.0
/usr/paul>route add 144.206.96.0 144.206.130.135 netmask 255.255.224.0
/usr/paul>route add 144.206.128 144.206.130.138 netmask 255.255.224.0
/usr/paul>route add 144.206.192.0 144.206.192.1 netmask 255.255.224.0
Если сравнить эти записи с примером 2.1, то можно заметить, что одной строчки в списке команд не хватает. Это строка, которая описывает маршрут к сети 194.226.56 через шлюз 144.206.130.207. Дело в том, что поле флагов отчета netstat говорит нам, что такого маршрута в первоначальной таблице не было.
В поле флагов отчета netstat мы можем встретить следующие флаги:
U - говорит о том, что маршрут активен и может использоваться для маршрутизации пакетов;
H - говорит о том, что этот маршрут используется для посылки пакетов определенному в маршруте хосту;
G - говорит о том, что пакеты направляются на шлюз, который ведет к адресату;
D - этот флаг определяет тот факт, что данный маршрут был добавлен в таблицу по той причине, что с одного из шлюзов пришел ICMP-пакет, указывающий адрес правильного шлюза, который в нашей таблице отсутствовал.
Строчка, которая описывает не указанный в командах маршрут в таблице маршрутов выглядит следующим образом:
Destination Gateway Flags Refs Use IfaceMTU Rtt
194.226.56 144.206.130.207 UGD 0 0 ed1 - -
Поле флагов содержит флаги: U-маршрут активен, G-пакеты направляются на шлюз и D-маршрут получен по сообщению ICMP о перенаправлении пакетов. Следовательно, первоначально такого маршрута в таблице маршрутов не было.
Если пользователи системы часто ходят в сеть 194.226.56.0, то в таблицу такой маршрут следует добавить:
/usr/paul>route add 194.226.56.0 144.206.130.207 netmask 255.255.224.0
При помощи команды route можно не только добавлять маршруты в таблицу маршрутов, но и удалять их от туда. Делается это по команде delete. Например, если нам надо изменить значение шлюза по умолчанию, то мы можем выполнить следующую последовательность команд:
/usr/paul>route delete default
/usr/paul/route add default 144.206.136.10 netmask 255.255.224.0
В данном случае сначала мы удалим из таблицы (пример 2.1) маршрут умолчания, а затем добавим туда новый. При удалении маршрута достаточно назвать только адрес назначения, чтобы route идентифицировала маршрут, который следует удалить.
Можно по команде route получить информацию и о конкретном маршруте, но удобнее все-таки пользоваться командой netstat. В последней и информации указывается больше, и можно получить такую информацию, о которой вы просто можете даже не подозревать, если приходят ICMP-сообщения или используется динамическая маршрутизация.
В заключение обсуждения вопросов статической маршрутизации хотелось бы сделать небольшое замечание по поводу Windows NT. До версии 4.0 в Windows NT штатно существовала только статическая маршрутизация. Для сетей локальных с надежными линиями связи этого вполне достаточно. Фактически, администратору нужно только указать IP-адреса на каждом из сетевых интерфесов, указать адрес шлюза по умолчанию и поднять флажок пересылки пакетов с одного интерфейса на другой. После этого все должно работать. Если локальная сеть подключается к провайдеру, то, как правило, все сводится к получению адреса из сети провайдера для внешнего интерфейса, т.е. интерфейса, который будет связывать вас с адресом шлюза провайдера и адресом своей сети или подсети. Если только провайдер не затеет изменения структуры своей сети, вес будет работать годами без каких-либо изменений. Для таких сетей шлюз на основе Windows NT можно организовать. Однако, не все так просто, когда речь идет о сети или подсети, которые подключаются в качестве части сети, которая не организована по иерархическому принципу. В этом случае возможно изменение наилучших маршрутов гораздо чаще, чем один раз в десятилетие и в этом случае статическая маршрутизация может оказаться недостаточной. Кроме того, важным фактором повышения надежности сетевого взаимодействия является наличие нескольких маршрутов к одним и тем же информационным ресурсам. В случае отказа одного из них можно использовать другие. Но проблема заключается в том, что система всегда использует тот маршрут, который первым встретился в таблице маршрутов, хотя и существуют мультимаршрутные системы, но они распространены, мягко говоря, не очень широко. Следовательно, маршруты из таблицы надо удалять и вносить. Если сеть работает не устойчиво, то это превращается в головную боль администратора. Вот почему до версии Windows NT 4.0 рассматривать эту систему в качестве реального претендента на маршрутизатор не представляется возможным. В Windows NT 4.0 появилась поддержка динамической маршрутизации в лице протокола RIP, но поддержки других протоколов маршрутизации пока еще нет.
Таким образом, мы подошли к проблеме автоматического управления таблицей маршрутов на основе информации, получаемой из сети. Такая процедура называется динамической маршрутизацией.
2.9.2. Динамическая маршрутизация
Прежде чем вникать в подробности и особенности динамической маршрутизации, обратим внимание на двухуровневую модель, в рамках которой рассматривается все множество машин Internet. В рамках этой модели весь Internet рассматривают как множество автономных систем (autonomous system - AS). Автономная система - это множество компьютеров, которое образуют довольно плотное сообщество, где существует множество маршрутов между двумя компьютерами, принадлежащими этому сообществу. В рамках этого сообщества можно говорить об оптимизации маршрутов с целью достижения максимальной скорости передачи информации. В противоположность этому плотному конгломерату, автономные системы связаны между собой не так тесно как компьютеры внутри автономной системы. При этом и выбор маршрута из одной автономной системы может основываться не на скорости обмена информацией, а надежности, безотказности и т.п.
|
|
Рис. 2.24. Схема взаимодействия автономных систем
Сама идеология автономных систем возникла в тот период, когда ARPANET представляла иерархическую систему. В то время было ядро системы, к которому подключались внешние автономные системы. Информация из одной автономной системы в другую могла попасть только через маршрутизаторы ядра. Такая структура до сих пор сохраняется в MILNET.
На рисунке 2.24 автономные системы связаны только одной линией связи, что больше соответствует тому, как российский сектор подключен к Internet. В классических публикациях по Internet взаимодействие автономных частей чаще обозначают пересекающимися кругами, подчеркивая тот факт, что маршрутов из одной автономной системы в другую может быть несколько.
Обсуждение этой модели Internet необходимо только для того, чтобы объяснить наличие двух типов протоколов динамической маршрутизации: внешних и внутренних.
Внешние протоколы служат для обмена информацией о маршрутах между автономными системами.
Внутренние протоколы служат для обмена информацией о маршрутах внутри автономной системы.
В реальной практике построения локальных сетей, корпоративных сетей и их подключения к провайдерам нужно знать, главным образом, только внутренние протоколы динамической маршрутизации. Внешние протоколы динамической маршрутизации необходимы только тогда, когда следует построить закрытую большую систему, которая с внешним миром будет соединена только небольшим числом защищенных каналов данных.
К внешним протоколам относятся Exterior Gateway Protocol (EGP) и Border Gateway Protocol (BGP).
EGP предназначен для анонсирования сетей, которые доступны для автономных систем за пределами данной автономной системы. По данному протоколу шлюз одной AS передает шлюзу другой AS информацию о сетях из которых состоит его AS. EGP не используется для оптимизации маршрутов. Считается, что этим должны заниматься протоколы внутренней маршрутизации.
BGP - это другой протокол внешней маршрутизации, который появился позже EGP. В своих сообщениях он уже позволяет указать различные веса для маршрутов, и, таким образом, способствовать выбору наилучшего маршрута. Однако, назначение этих весов не определяется какими-то независимыми факторами типа времени доступа к ресурсу или числом шлюзов на пути к ресурсу. Предпочтения устанавливаются администратором и потому иногда такую маршрутизацию называют политической маршрутизацией, подразумевая, что она отражает техническую политику администрации данной автономной системы при доступе из других автономных систем к ее информационным ресурсам. Протокол BGP используют практически все российские крупные IP-провайдеры, например крупные узлы сети Relcom.
К внутренним протоколам относятся протоколы Routing Information Protocol (RIP), HELLO, Intermediate System to Intermediate System (IS-IS), Shortest Path First (SPF) и Open Shortest Path First (OSPF).
Протокол RIP (Routing Information Protocol) предназначен для автоматического обновления таблицы маршрутов. При этом используется информация о состоянии сети, которая рассылается маршрутизаторами (routers). В соответствии с протоколом RIP любая машина может быть маршрутизатором. При этом, все маршрутизаторы делятся на активные и пассивные. Активные маршрутизаторы сообщают о маршрутах, которые они поддерживают в сети. Пассивные маршрутизаторы читают эти широковещательные сообщения и исправляют свои таблицы маршрутов, но сами при этом информации в сеть не предоставляют. Обычно в качестве активных маршрутизаторов выступают шлюзы, а в качестве пассивных - обычные машины (hosts).
В основу алгоритма маршрутизации по протоколу RIP положена простая идея: чем больше шлюзов надо пройти пакету, тем больше времени требуется для прохождения маршрута. При обмене сообщениями маршрутизаторы сообщают в сеть IP-номер сети и число «прыжков» (hops), которое надо совершить, пользуясь данным маршрутом. Надо сразу заметить, что такой алгоритм справедлив только для сетей, которые имеют одинаковую скорость передачи по любому сегменту сети. Часто в реальной жизни оказывается, что гораздо выгоднее воспользоваться оптоволокном с 3-мя шлюзами, чем одним медленным коммутируемым телефонным каналом.
Другая идея, которая призвана решить проблемы RIP, - это учет не числа hop’ов, а учет времени отклика. На этом принципе построен, например, протокол OSPF. Кроме этого OSPF реализует еще и идею лавинной маршрутизации. В RIP каждый маршрутизатор обменивается информацией только с соседями. В результате, информации о потере маршрута в сети, отстоящей на несколько hop’ов от локальной сети, будет получена с опозданием. Лавинная маршрутизация позволяет решить эту проблему за счет оповещения всех известных шлюзов об изменениях локального участка сети.
К сожалению, многовариантную маршрутизацию поддерживает не очень много систем. Различные клоны Unix и NT, главным образом ориентированы на протокол RIP. Достаточно посмотреть на программное обеспечение динамической маршрутизации, чтобы убедится в этом. Программа routed поддерживает только RIP, программа gated поддерживает RIP, HELLO, OSPF, EGP и BGP, в Windows NT поддерживается только RIP.
Поэтому мы рассмотрим возможность динамического управления таблицей маршрутов только по протоколу RIP.
2.9.3. Программа routed
Программа routed поставляется с любым клоном Unix и используется в качестве демона протокола RIP по умолчанию. Как правило, она используется без аргументов и запускается в момент загрузки операционной системы. Однако, если машина не является шлюзом, то имеет смысл указать флаг «-q». Этот флаг означает, что routed не будет посылать информации в сеть, а только будет слушать информацию от других машин. Обычно, активными являются шлюзы, а все остальные системы являются пассивными.
Однако, часто бывает полезно при начальной загрузке инициализировать таблицу маршрутов и определить строки, которые из нее не следует удалять ни при каких условиях. Самый типичный случай - назначение шлюза по умолчанию. Для этой цели можно использовать файл /etc/gateways, который программа routed просматривает при запуске и использует для первоначальной настройки таблицы маршрутов. Содержание этого файла может выглядеть следующим образом:
net 0.0.0.0 gateway 144.206.136.10 netric 1 passive
В данном примере адрес 0.0.0.0 используется для определения адреса умолчания, машина 144.206.136.10 - это шлюз по умолчанию, метрика определяет число hop’ов до этого шлюза, а параметр «passive» - говорит о том, что даже если с этого шлюза никакой информации о маршрутах не приходит, то его все равно не надо удалять из таблицы маршрутов. Последний параметр указывается в том случае, если шлюз только один, если же возможно использование другого шлюза и эти шлюзы активно извещают машины сети о своих таблицах маршрутов, то следует вместо passive использовать active:
net 0.0.0.0 gateway 144.206.136.10 netric 1 active
В этом случае пассивный шлюз из таблицы маршрутов будет удален, а тот, который может исполнять функции реального шлюза будет в таблицу включен. В сети kiae изменение шлюза по умолчанию можно наблюдать по несколько раз в день.
Когда используется только Ethernet, то программа routed может использоваться и на машинах шлюзах, но если система связана с внешним миром через SLIP или PPP, то использование routed может привести к потере самого главного маршрута. Он будет удален из таблицы из соображений неактивности. В этом случае лучше всего использовать программу gated.
2.9.4. Программа gated
Gated - это коллективный продукт американских университетов, который был разработан для работы сети NFSNET. Права copyright закреплены за Корнельским университетом, хотя части кода являются собственностью других университетов и ассоциаций.
Gated - это модульная программа предназначенная организации много функционального шлюза, который мог бы обслуживать как внутреннюю маршрутизацию, так и внешнюю. Gated поддерживает протоколы RIP (версии 1 и 2), HELLO, OSPF версии 2, EGP версии 2 и BGP версий от 2 до 4. Все перечисленные возможности относятся к версии 3.5. На системах типа HP-UX 9.x или IRIX 6.x могут стоять и более ранние версии, которые всего этого набора протоколов могут и не поддерживать.
Рассмотрим два основных примера использования gated в локальной сети: вместо routed на обычной машине и на машине-шлюзе в другую сеть. При этом будем опираться на следующую схему, изображенную на рисунке 2.25.
|
|

Рис. 2.25. Подключение локальной сети к Internet и настройки gated
Gated настраивается при помощи своего файла конфигурации /etc/gated.conf. Именно в нем пишутся все команды настройки, которые gated проверяет при запуске.
При работе на обычной машине, системе надо только указать интерфейс и протокол динамической маршрутизации, который gated должна использовать:
#
# Interface shouldn`t be removed from routing table
#
interface 144.206.160.40 passive ;
#
# routing protocol is rip.
#
rip yes;
В большинстве случаев достаточно просто указать протокол, т.к. интерфейс попадет в таблицу маршрутизации после выполнения команды ifconfig.
Теперь обратимся к настройкам gated на машине-шлюзе. В принципе, можно также обойтись одним указанием на протокол RIP и все будет работать. Если же надо сохранять маршруты через интерфейсы в таблице маршрутов, то следует указать в файле конфигурации оба интерфеса:
# Interfaces shouldn`t be removed from routing table
interface 144.206.160.32 passive ;
interface 144.206.130.137 passive ;
# routing protocol is rip.
rip yes;
Однако можно использовать и более сложное описание, основанное на логике работы gated. А логика эта состоит в том, что gated объявляет соседним шлюзам по RIP, что подсеть 144.206.160.0 доступна через интерфейс 144.206.130.137, в свою очередь для подсети gated объявляет, что весь мир доступен через интерфейс 144.206.160.32. Очевидно, что это логика заимствована из архитектуры внешних протоколов маршрутизации и распространена на протоколы внутренние. Это позволяет вести описание маршрутов в едином ключе.
rip yes;
export[1] proto rip interface 144.206.130.137
{
proto direct
{
announce 144.206.160.0 metric 0 ;
} ;
} ;
export proto rip interface 144.206.160.32
{
proto rip interface 144.206.130.137
{
announce all ;
} ;
} ;
Первая команда export анонсирует подсеть 144.206.160.0 через интерфейс 144.206.130.137. При этом сообщается, что это шлюз в данную подсеть, т.е. интерфейс 144.206.130.137 расположен на машине, которая включена в эту подсеть. О том, что пакеты для подсети надо посылать непосредственно на этот интерфейс говорит предложение proto direct, а то, что интерфейс стоит на шлюзе в подсеть говорит метрика, равная 0.
Второе предложение сообщает всем машинам подсети через интерфейс 144.206.160.32 все маршруты, которые данный шлюз получает из подсети 144.206.128.0 через интерфейс 144.206.130.137. Фактически осуществляется сквозная пересылка всей информации во внутрь системы.
При написании управляющих предложений export следует всегда помнить, что внешнее предложение определяет всегда интерфейс, через который сообщается информация, а внутреннее предложение определяет источник, через который эту информацию получает gated.
Важным является и синтаксис предложений, который сильно смахивает на синтаксис языка программирования С.
Во всех руководствах по gated приводится еще один пример, когда сеть, через подсеть подключают к Internet. Здесь приведем пример из руководства к gated 3.5.
rip yes;
export proto rip interface 136.66.12.3 metric 3
{
proto rip interface 136.66.1.5
{
announce all ;
} ;
} ;
export proto ripinterface 136.66.1.5
{
proto rip interface 136.66.12.3
{
announce 0.0.0.0 ;
} ;
{ ;
В данном случае все, что gated получает из локальной сети через интерфейс 136.66.1.5, транслируется в подсеть, которая связывает данную сеть с Internet, через интерфейс 136.66.12.3 (речь идет только о маршрутах, так как gated работает только с таблицей маршрутов).
Второе предложение export определяет, куда следует отправлять информацию по умолчание из сети, чтобы она достигла адресата, расположенного за пределами данной локальной сети. Адрес 0.0.0.0, который соответствует любой машине за интерфейсом 136.66.12.3 анонсируется через интерфейс 136.66.1.5. для всей локальной сети.
И последние замечания о gated. Они касаются возможности управлять доступом к машинам локальной сети. Если маршрут доступа к машине или локальной подсети не экспортировать во внешний мир, то о машине или подсети никто и не узнает. Правда, в этом случае нельзя использовать эти машины для доступа к внешним ресурсам также.
2.10. Анализ и фильтрация TCP/IP пакетов
В одном из докладов Министерства Обороны США, выполненном по запросу Конгресса, отмечалось, что в последнее время число атак на компьютеры вооруженных сил увеличилось. При этом атакующие, главным образом, используют программы захвата и анализа трафика TCP/IP, который передается по сети Internet. Надо сказать, что проблема эта не новая. Еще во время начала проекта Athena в Масачусетском Технологическом Институте, в результате которой появилась система Керберос, одной из основных целей проекта называлась защита от захвата и анализа пакетов.
До последнего времени, в российском секторе Internet хотя и знали, что такая проблема существует, хотя провайдеры и пользовались сами сканированием, серьезных шагов по защите от этого сканирования не предпринимали. В данном случае речь идет о том, что требование тотальной защиты, как это имеет место во всех зарубежных коммерческих и правительственных сетях, не выдвигалось. Не смотря на то, что Relcom первым продемонстрировал в 1991 году возможности бесконтрольного, со стороны государства, распространения информации через Internet, ни Demos, ни AO Relcom не ставили перед собой задачи сплошной защиты своих внутренних сетей от атаки из вне при помощи просмотра содержания IP-пакетов.
Надо сказать, что довольно долгое время такая практика себя оправдывала. Серьезных нарушений в работе сети не происходило, а атаки на шлюзы и локальные подсети успешно отбивались системами фильтрации трафика. Но к осени 1996 года ситуация изменилась. И главной причиной изменения стало внедрение системы доступа к сети по dial-ip. Теперь в сети появилось большое количество случайных людей со стороны. Кроме того, внедрение Internet во многих московских вузах привело к увеличению среди пользователей сети доли студентов. При этом следует отметить, что доступ из академических и учебных заведений в Internet по большей части остается бесплатным для пользователей, а это значит, что ресурсами сети можно пользоваться круглосуточно, не заботясь о том, сколько у тебя в кармане денег.
Склонность человеческой натуры к подсматриванию и подглядыванию хорошо известна. А если за это еще и не накажут, и заниматься этим можно сколько душе угодно, то вероятность появления любопытных резко возрастает.
К осени 1996 года число зарегистрированных пользователей Dial-IP составило несколько тысяч человек только в AO Relcom. SovamTeleport начал заниматься предоставлением такого доступа на полгода раньше (с осени 1995), следовательно там число пользователей должно быть еще больше. Кроме того, многие университеты, учебные заведения и научно-исследовательские организации для своих сотрудников создали модемные пулы. Естественно, что администраторы подсетей или их близкие друзья также не могли пройти мимо возможности работать на дому. Исходя из этого, можно предположить, что только в Москве число пользователей Dial-IP составляет несколько десятков тысяч человек.
Совершенно очевидно, что среди такого количества людей обязательно найдется некто, кто посвятит все свое свободное время исследованию сети, тем более что слава всемогущих хакеров, взламывающих компьютеры Пентагона, не дает спать спокойно многим.
И вот в середине сентября 1996 года прозвенел первый звоночек. Точнее, на эту проблему обратил внимание наших провайдеров CERT (Computer Emagency Response Team). В Канаде были зарегистрированы попытки входа в систему по различным портам TCP с указанием действительно существовавших идентификаторов и паролей пользователей. Попытку зарегистрировала программа межсетевого фильтра (FilreWall), о чем и сообщила администратору. Администратор оказался человеком дотошным и стал выяснять кто и откуда пытался проникнуть в систему.
Двухнедельные занятия по изучению файлов отчетов о доступе к основным компьютерам центров управления российскими сетями показали удручающую картину. Действительно, на многих машинах наблюдались посещения в режиме привилегированных пользователей с адресов, которые не ассоциировались ни с одним из тех лиц, кому такой доступ был разрешен. Были найдены и списки идентификаторов и паролей, и инструмент, которым пользовались взломщики, и отчеты этой программы, которые хранились злоумышленниками на компьютерах за пределами российской части Internet.
Собственно определить, кто и откуда коллекционировал информацию, не представляло большого труда, но главным был вопрос о том, что в этом случае следует предпринимать. Ведь подобного прециндента в практике российского Internet-сообщества еще не было.
Во-первых, конечно надо было защищаться. Средства защиты хорошо известны - это фильтрация трафика и шифрация обменов. Благо на настоящий момент Гос.тех комиссией выдано более сотни лицензий на возможность проведения такого сорта мероприятий и сертифицировано как аппаратное, так и программное обеспечение. Но пассивная оборона - это только половина дела, хотелось еще и наказать наглецов. А вот с последним и возникли проблемы. В принципе, по новому российскому законодательству предусмотрены наказания вплоть до лишения свободы на строк до семи лет за компьютерные преступления, но для этого надо вести следственные мероприятия, передавать дело в суд и т.п. Все это не входит в компетенцию провайдеров, потому что может занять много времени, а кроме того о таких прецидентах, что-то пока ничего слышно не было.
Общение с организацией, предоставившей Dial-IP вход, также не дало гарантий от повторения подобных инцидентов. Поэтому было принято решение зафильтровать сетки, с которых осуществлялся первоначальный вход в сеть при взломе.
К чему привела эта практика, на своей шкуре почувствовали многие пользователи сети. На первый взгляд, вроде ничего страшного, ну не пускают тебя к отечественным информационным ресурсам, а мы, что называется, и не хотели. Будем ходить на Запад. Но не тут-то было.
Дело в том, что к отечественным информационным сервисам относится и служба DNS. DNS обслуживает запросы на получение по доменному имени машины ее IP-адреса. Каждый домен имеет несколько серверов, которые могут удовлетворить запрос пользователя, но только один из них является главным. Все остальные время от времени сверяют информацию в своей базе данных с информацией в базе данных главного сервера. При фильтрации обычно закрывают порты TCP. Это значит, что отвечать на запросы, которые используют 53 порт UDP, сервер будет, а вот осуществить копирование описания зоны на дублирующий сервер, которое производится по 53 порту TCP, межсетевой фильтр не даст. Как результат, дублирующие сервера будут отказывать в обслуживании, и доступ к ресурсам, из-за невозможности получить за приемлемое время IP-адрес, будет затруднен.
В результате доступ к такому информационному ресурсу, как World Wide Web, происходит через «пень-колоду». Что говорить о доступе к отечественным ресурсам. Ведь не “видно” не только тех, кто спрятался за «стенами», но и тех, кто разместил там серверы DNS. Особенно пикантной становится ситуация, если в защищенную зону попадет root-сервер DNS для доменов SU и RU.
Сколько теперь будет успокаиваться поднятая этими действиями волна - не известно, но то, что провайдеры, к которым в данном случае относятся и некоммерческие сети, должны вместе договориться об общих принципах политики безопасности - это очевидно, в противном случае ситуация будет повторяться постоянно, но уже гораздо с большими последствиями для всех заинтересованных сторон.
И попутно, хотелось бы заметить, что всякие разговоры о проблемах с сервером InfoArt, когда, как утверждалось, было подменено содержание базы данных службы доменных имен, могут являться следствием указанных выше причин. Хотя то, что события совпали по времени может быть простой случайностью.
После столь долгого вступления хотелось все же обратиться к тому средству, которым воспользовались злоумышленники. Программы, позволяющие захватывать пакеты из сети, называются sniffers (буквально – «нюхачи», но мне кажется лучше назвать их «пылесосами», т.к. сосут они все подряд, хотя есть и интеллектуальные, которые из всех пакетов выбирают только то, что нужно).
Первые такие программы использовали то, что в сетях Ethernet все компьютеры подсоединяются на один кабель. В обычном режиме карта Ethernet принимает только те фреймы, которые ей предназначены, т.е. указаны в заголовке фрейма. Однако в целях отладки многие карты можно заставить работать в режиме «пылесоса», тогда они будут принимать все фреймы, которые передаются по кабелю. Такой режим работы карты называется promiscuous mode. Если можно получить пакет в машину, то, следовательно, его можно проанализировать.
Главная проблема, связанная с «нюхачами» заключается в том, чтобы они успевали перерабатывать весь трафик, который проходит через интерфейс. Код одной из достаточно эффективных программ этого типа (Esniff) был опубликован в журнале Phrack. Esniff предназначена для работы в Sunos. Программа очень компактная и захватывает только первые 300 байтов заголовка, что вполне достаточно для получения идентификатора и пароля telnet-сессии. Программа свободно распространяется по сети и каждый желающий может ее «срисовать» по адресу ftp://coombs.anu.edu.au/pub/net/log. Существуют и другие программы этого типа и не только для платформ Sun. Это Gobler, athdump, ethload для MS-DOS или Paketman, Interman, Etherman, Loadman - для целого ряда платформ, которые включают в себя Alpha, Dec-Mips, SGI и др. «Нюхачи» существуют не только для Ethernet. Многие компании выпускают системы анализа трафика и для высокоскоростных линий передачи данных. Достаточно зайти на домашнюю страницу AltaVista и запустить запрос, состоящий из одного слова «sniffer» как вы сразу получите целый список страниц на данную тему. Лучше правда «sniffer AND security», т.к. система может понять вас буквально и выложить информацию и об органах дыхания.
Когда программы анализа трафика писались, то предполагалось, что пользоваться ими будут профессионалы, отвечающие за надежность работы сети. Однако, как это часто бывает, система оказалась обоюдоострой. Как же бороться с непрошенными гостями?
Во-первых, если система многопользовательская, то при помощи команды ifconfig можно увидеть интерфейс, который работает в режиме «пылесоса». Среди флагов появляется значение PROMISC. Однако, злоумышленник может подменить команду ifconfig, чтобы она не показывала этот режим работы. Поэтому следует убедиться в том, что программа та, которая была первоначально, а во-вторых, ее протестировать.
Обнаружить «пылесос» на других машинах сети нельзя, особенно это касается машин с MS-DOS. Поэтому от сканирования защищаются путем установки межсетевых фильтров и введения механизмов шифрации либо всего трафика, либо только идентификаторов и паролей.
Существуют и аппаратные способы защиты. Ряд сетевых адаптеров не поддерживает режим promiscuous mode. Если эти карты использовать для организации локальной сети, то можно обезопасить себя от «подглядывания».
Для того, чтобы «подглядывать» вовсе не обязательно включать режим принятия всех пакетов. Если запустить программу анализа пакетов на шлюзе, то вся информация также будет доступна, т.к. шлюз пропускает через себя все пакеты в/из локальной сети, для которой он является шлюзом.
В заключении хотелось бы сказать, вслед за Jeff Schiller и Joanne Costell из Масачусетского Технологического Института, что, для использования sniffer не надо иметь семи пядей во лбу, не надо иметь диплом о высшем образовании и вообще запустить программу и воспользоваться результатами может и младенец. То, что кто-то смог наколлекционировать чужие пароли и идентификаторы не говорит о его уме или профессиональной пригодности. Единственным последствием таких действий станет неминуемое ужесточение правил использования сети, от которого плохо станет всем.
Раздел 3. Информационные сервисы Internet
3.1. Система Доменных Имен
Числовая адресация удобна для машинной обработки таблиц маршрутов, но совершенно не приемлема для использования ее человеком. Запомнить наборы цифр гораздо труднее, чем мнемонические осмысленные имена. Для облегчения взаимодействия в Сети сначала стали использовать таблицы соответствия числовых адресов именам машин. Эти таблицы сохранились до сих пор и используются многими прикладными программами. Некоторое время даже существовало центральное хранилище соответствий, которое можно было по FTP скачать на свою машину из ftp.internic.net. Это файлы с именем hosts. Если речь идет о системе типа Unix, то этот файл расположен в директории /etc и имеет следующий вид:
|
IP-адрес |
имя машины |
синонимы |
|
127.0.0.1 |
localhost |
localhost |
|
144.206.160.32 |
Polyn |
polyn |
|
144.206.160.40 |
Apollo |
www |
Рис. 3.1. Пример таблицы имен хостов (файл /etc/hosts)
Конечно, в машине этот файл записывается не в виде таблицы, а следующим образом:
Пример 1. Содержание файла /etc/hosts
127.0.0.1 localhost
144.206.130.137 polyn Polyn polyn.net.kiae.su polynm.kiae.su
144.206.160.32 polyn Polyn polyn.net.kiae.su polyn.kiae.su
144.206.160.40 apollo Apollo www.polyn.kiae.su
Последний столбец в этой таблице является необязательным. Пользователь для обращения к машине может использовать как IP-адрес машины, так и ее имя или синоним (alias). Как видно из примера, синонимов может быть много, и, кроме того для разных IP-адресов может быть указано одно и то же имя.
Обращения, приведенные ниже, приводят к одному и тому же результату - инициированию сеанса telnet с машиной Apollo:
telnet 144.206.160.40
или
telnet Apollo
или
telnet www
В локальных сетях файлы hosts используются достаточно успешно до сих пор. Практически все операционные системы от различных клонов Unix до Windows NT поддерживают эту систему соответствия IP-адресов доменным именам.
Однако такой способ присвоения символьных имен был хорош до тех пор, пока Internet был маленьким. По мере роста сети стало затруднительным держать большие списки имен на каждом компьютере. Для того, что бы решить эту проблему, были придуманы DNS (Domain Name System).
3.1.1. Принципы организации DSN
Любая DNS является прикладным процессом, который работает над стеком TCP/IP. Таким образом, базовым элементом адресации является IP-адрес, а доменная адресация выполняет роль сервиса. Правда о том, что DNS - это прикладная задача в полном смысле этого слова приходится говорить с определенными оговорками. DNS - это информационный сервис Internet, и, следовательно, протоколы его реализующие относятся к протоколам прикладного уровня согласно стандартной модели OSI. Однако с точки зрения операционной системы поддержка DNS может входить в нее как компонента ядра, которая прикладным пользовательским процессом не является. Пользовательские программы общаются с ней при помощи системных вызовов. Такое положение вещей справедливо практически для всех Unix-систем. Другое дело системы на базе MS-DOS и Windows 3.x. В этих системах DNS (точнее ее клиентская часть) реализована как прикладная программа.
Система доменных адресов строится по иерархическому принципу. Однако иерархия эта не строгая. Фактически, нет единого корня всех доменов Internet. Если быть более точным, то такой корень в модели DNS есть. Он так и называется «ROOT». Однако, единого администрирования этого корня нет. Администрирование начинается с доменов верхнего, или первого, уровня. В 80-е годы были определены первые домены этого уровня: gov, mil, edu, com, net. Позднее, когда сеть перешагнула национальные границы США появились национальные домены типа: uk, jp, au, ch, и т.п. Для СССР также был выделен домен su. После 1991 года, когда республики союза стали суверенными, многие из них получили свои собственные домены: ua, ru, la, li, и т.п. Однако Internet не СССР, и просто так выбросить домен su из сервера имен нельзя, на основе доменных имен строятся адреса электронной почты и доступ ко многим другим информационным ресурсам Internet. Поэтому гораздо проще, оказалось, ввести новый домен к существующему, чем заменить его. Таким образом, в Москве существуют организации с доменными именами, оканчивающимися на su (например, kiae.su) и оканчивающимися на ru (msk.ru).
Если быть более точным, то новых имен с расширением su в настоящее время ни один провайдер не выделяет. Более того идет планомерная замена имен. Выявляются зарубежные информационные источники, и их администрация оповещается о замене доменных имен, после соответствующего подтверждения происходит удаление имени с расширением su.
Вслед за доменами верхнего уровня следуют домены, определяющие либо регионы (msk), либо организации (kiae). В настоящее время практически любая организация может получить свой собственный домен второго уровня. Для этого только надо направить заявку провайдеру и получить уведомление о регистрации (см. раздел 3.1.3). Далее идут следующие уровни иерархии, которые могут быть закреплены либо за небольшими организациями, либо за подразделениями больших организаций.
Всю систему доменной адресации можно представить следующим образом (рисунок 3.2):
|
|
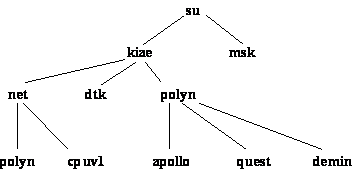
Рис. 3.2. Пример дерева доменной адресации
Наиболее популярной программой поддержки DNS является named, которая реализует Berkeley Internet Name Domain (BIND). Но эта программа не единственная. Так в системе Windows NT 4.0 есть свой сервер доменных имен, который поддерживает спецификацию BIND. Определена в документе RFC 1033-1035.
3.1.2. BIND (Berkeley Internet Name Domain)
BIND или Berkeley Internet Name Domain - это сервер доменных имен реализованный в университете Беркли, который широко применяется на Intenet’е. Он обеспечивает поиск доменных имен и IP-адресов для любого узла Сети. BIND обеспечивает рассылку сообщений электронной почты через узлы Internet. Если говорить более точно BIND обеспечивает поиск доменного адреса машины пользователя, которому адресована почта, и определение IP-адреса доменному адресу. Эта информация используется программой рассылки почтовых сообщений sendmail, которая выступает в качестве почтового сервера.
BIND реализован по схеме «клиент/сервер». Собственно BIND - это сервер, а функции клиента выполняет name resolver или просто resolver. Обычно, модули resolver’а находятся в библиотеке libc.a, если речь идет о системе UNIX, и редактируются вместе с программой, использующей вызовы gethostbyname и gethostbyaddr. Как уже отмечалось, базовым понятием для BIND является «домен». На рисунке 3.3 представлена схема описания системы доменов.
|
|
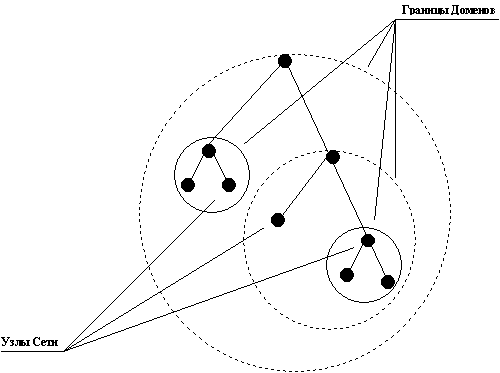
Рис. 3.3. Схема доменной адресации
На рисунке домены изображены в виде кругов. Каждый круг соответствует множеству компьютеров, которые образуют домен. Вложенные круги - это поддомены, которые, в свою очередь тоже могут быть разбиты на поддомены и т.д. При отображении этой структуры в доменные имена получается иерархия имен узлов сети.
Однако разговоры об архитектуре сервиса доменных имен и различных его реализаций совершенно беспочвенны, если только не иметь своего собственного домена. Ведь проблемы с администрированием возникают только в этом случае. В следующем разделе рассказано о том, как его получить.
3.1.3. Регистрация доменных имен
Материал, изложенный в этой главе, отражает только формальную процедуру получения доменного имени. На самом деле, в настоящее время система регистрации доменных имен находится в процессе изменения. Вводится институт независимых регистраторов, через которых и следует регистрировать домены.
Для того, чтобы получить зону надо отправить заявку в РосНИИРОС, который отвечает за делегирование поддоменов в пределах домена ru. В заявке указывается адрес компьютера-сервера доменных имен, почтовый адрес администратора сервера, адрес организации и ряд другой информации. Разберем эту заявку на примере заявки Международной лаборатории VEGA.
domain: vega.ru
descr: International Agency VEGA
descr: Kurchatov sq. 1
descr: 115470 Moscow
descr: Russian Federation
admin-c: Pavel B Khramtsov
zone-c: Pavel B Khramtsov
tech-c: Pavel B Khramtsov
nserver: vega-gw.vega.ru
nserver: ns.relarn.ru
nserver: polyn.net.kiae.su
dom-net: 194.226.43.0
changed: paul@kiae.su 961018
source: RIPN
person: Pavel B Khramtsov
address: International Agency Vega
address: Kurchatov sq. 1
address: 115470 Moscow
address: Russian Federation
phone: +7 095 1969124
fax-no: +7 095 9393670
e-mail: paul@kiae.su
changed: paul@kiae.su 961018
source: RIPN
При заполнении этой заявки следует иметь в виду, что она будет обрабатываться роботом автоматом. Этот автомат проверяет ее на наличие ошибок заполнения и противоречия с существующей базой данных делегированных доменов. Так как робот не терпит неточностей и глух к различного рода просьбам, то заполнять заявку следует аккуратно. Автомат обрабатывает заявку, выделяет в ней записи для базы данных регистрации доменов. Сами эти записи состоят из полей. Каждое поле идентифицируется в заявке именем поля, после которого ставится символ «:».
В строке описания поля «domain:» указывается имя домена, которое вы просите зарегистрировать. РосНИИРОС регистрирует только поддомены домена ru. Регистрировать следует как «прямую» зону, так и «обратную» (см. раздел 3.1.4). В нашем случае это просто зона 43.226.194.in-addr.arpa.
В строке описания поля «descr:» указывают название и адрес организации, которая запрашивает домен. Так как на одной строке эта информация не может разместиться, то команд descr может быть несколько.
В строке описания поля «admin-c:» указывается персона, которая осуществляет администрирование домена. Поле имеет обязательный формат: <имя> <первая буква отчества> <фамилия>. Таких строк может быть несколько, если лиц отвечающих за администрирование домена больше одного. Вместо указанного выше формата можно использовать также и идентификатор персоны, если таковой имеется. Идентификатор называют nic-handle, или персональный код.
Поле «zone-c:» заполняется для той персоны, чей почтовый адрес указан в записи SOA в описании зоны. Формат этого поля идентичен формату команды admin-c.
Поле «tech-c:» указывается для технического администратора домена, к которому обращаются в случае экстренных ситуаций. Формат этого поля совпадает с форматом команды admin-c. По моему глубокому убеждению, во всех полях (admin-c, zone-c и tech-c) имеет смысл указывать координаты одного и того же человека. Мало кто из российских пользователей Internet может позволить роскошь держать сразу трех разных специалистов на обслуживании сервиса доменных имен. Учитывая отечественные реалии, можно со всей ответственностью утверждать, что кроме неразберихи ни к чему другому большое количество администраторов не приводит.
В строке описания поля «nserver:» указывают доменные имена серверов зоны. Как правило, таких строк в заявке бывает несколько. Первым указывается primary или главный сервер домена. В нашем случае это vega-gw.vega.ru. На этом сервере хранится база данных домена. Вторым указывается secondary или дублирующий сервер домена. В нашем случае это ns.relarn.ru. Дублирующие сервера призваны повысить надежность работы всей системы доменных имен, поэтому дублирующих серверов может быть несколько. Если существуют другие дублирующие сервера, то указываются и они (сервер polyn.net.kiae.su из нашей заявки также является дублирующим для домена vega.ru). При указании дублирующих серверов первым следует указывать тот, который наиболее надежно обслуживает запросы к домену. В нашем примере таким является сервер ns.relarn.ru. Выбран он был по тем соображениям, что регистрация проводилась в РосНИИРОС, специалисты которого администрируют домен relarn.ru. Первоначально, дублирующим сервером был только сервер polyn.net.kiae.su. Однако, медленная скорость разрешения доменных имен в домене kiae.su всем хорошо известна. Это приводит к достаточно большим задержкам при ответах на запросы на расширение имени. Особенно долго обрабатываются обратные запросы. В результате, автомат постоянно выдавал сообщение, что сервер polyn.net.kiae.su недоступен, хотя при ручном тестировании все работало нормально. Для того, чтобы решить эту проблему было решено просить разрешения на использование ns.relarn.ru в качестве secondary сервера для домена vega.ru, справедливо полагая, что сервер доменных имен расположенный в том же домене, что и автомат, и сервер установленный на машине, использующий общий коаксиальный кабель с машиной автомата, будет отвечать гораздо оперативнее сервера, расположенного в другом домене, за несколькими репитерами и мостами. При выборе места размещения дублирующих серверов следует иметь в виду, что сначала проверяется возможность взаимодействия именно с этими серверами. Если хотя бы один из них не откликается на запросы автомата, то заявка отклоняется.
Поле «sub-dom:» описывает поддомены домена. В нашей заявке нет поля sub-net, т.к. в домене vega.ru нет поддоменов. Но если бы нам понадобилось изменять структуру домена, а именно, разбить его на зоны, то тогда следовало бы включить в заявку между строками nserver и строкой dom-net строку:
sub-net: zone1 zone2
В этом случае весь домен vega.ru разбит на два поддомена: zone1 и zone2. Например, машина quest из зоны zone1 будет иметь доменное имя quest.zone1.vega.ru, а машина query из зоны zone2 - query.zone2.vega.ru. Поддомены указываются в команде sub-dom через пробел.
Поле «dom-net:» указывает на список IP-сетей данного домена. В нашей заявке указана только одна сеть 194.226.43.0, но если у организации, которая заводит свой собственный домен, имеется в наличии несколько сетей, то эти сети можно указать в этом поле, разделяя их пробелами.
Поле «changed:» является обязательным и служит указателем на то лицо, которое последним вносило изменения в заявку. В качестве значения поля после символа «:» указывается почтовый адрес этого лица и, через пробел дата внесения изменения в формате ГГММДД (Г-год, М-месяц, Д-день).
Последняя запись в заявке - это поле source, которое отделяет различные записи во входном потоке данных программы робота. Значение этого поля - RIPN.
Вслед за записью заявки следует запись описания персоны. Именно эта запись позволяет связывать поля admin-c, zone-c, tech-c с информацией о конкретном лице, которая содержится в записи описания персоны.
Запись описания персоны начинается с поля «person:». В данном поле указывается информация о лице (персоне). Обычно, данное поле имеет следующий формат: <имя> <первая буква отчества> <фамилия>.
Поле «address:» вслед за полем «person:». Данное поле состоит из нескольких строк, каждая из которых начинается с имени поля. Первым указывается организация, во второй строке - улица и номер дома, в третьей - почтовый индекс и название города или поселка, в последней строке - название страны. Одним словом - это типичный американский почтовый адрес.
За адресом следует поле «phone:». В нем указывается номер телефона, по которому можно связаться с указанным лицом. Номер задается с указанием номера страны и кода города. Для Москвы - +7 095 ´´´ ´´ ´´. Телефонов можно указать несколько.
Все выше сказанное для поля «phone:» относится и к полю «fax-no:». В этом поле указывается номер телефакса.
Самым важным, на мой взгляд, из всех полей, определяющих координаты персоны, является поле адреса электронной почты – «e-mail:», хотя оно и не является обязательным полем заявки. Адрес электронной почты указывается как адрес электронной почты Internet. Для абонентов других сетей возможны проблемы с регистрацией их адресов, т.к. указание символов «!», «%», «::» нежелательно.
В поле «nic-hdl:» указывается персональный номер пользователя, если он у данного пользователя есть. Поле не является обязательным, но, как подчеркивается в инструкции по заполнению заявок «крайне желательно».
Последним полем в описании персоны, как и в заявке на домен, является поле «source:». В заявке можно указать несколько персон, что породит для каждой из них свою собственную запись в базе данных описания доменов. Информация о зоне и лицах, которые ответственны за ведение зоны (и не только о них) можно найти по команде:
/usr/paul>whois -h whois.ripn.net <имя зоны или персоны>
Теперь после описания самой заявки перейдем к описанию ее регистрации. После того как заявка отправлена, следует настроить и запустить сервер в локальном режиме. Администратор РосНИИРОС обычно извещает о том, что у администрации домена ru нет претензий к вашей заявке и разрешает запустить ваш сервер для тестирования. Если в домене есть уже запрашиваемый вами поддомен или у администрации домена ru есть другие возражения по поводу регистрации вашего домена, то администрация домена ru вас об этом известит.
Если у администратора домена ru нет причин для отказа в регистрации, то он разрешает запуск сервера для тестирования. Если ваш сервер уже запущен, то это сообщение вы просто примете к сведению, если нет, то нужно срочно, обычно втечение 2-х часов настроить и запустить сервер (вообще-то, запускать надо сразу как только решили отправлять заявку).
Еще раз обратите внимание на то, что заявка, отправленная на адрес ru-dns@RIPN.net попадает на автомат обработки заявок, с которым бесполезно вступать в пререкания и прения по поводу различного рода ошибок и неточностей. При этом проблемы с регистрацией могут возникать как по вине заявителя (ошибки в полях заявки, например), так и по вине регистрирующей стороны. Так, например, регистрация домена vega.ru длилась почти два месяца из-за того, что в начале были ошибки в заявке, потом были выявлены несоответствия заявки и описания зоны, затем сломался автомат регистрации, и заявка была утеряна. Затем возникли проблемы с дублирующим сервером зоны (слишком большое время отклика, из-за которого автомат отклонял заявку). При этом и сам автомат работал медленно, т.к. проблема скорости разрешения запросов на серверах имен РНЦ «Курчатовский Институт» хорошо всем известна. Поэтому лучше всего сразу узнать телефон администратора и общаться с ним непосредственно.
Именно «телефон», и об этом упоминается не случайно. Общение с администраторами по электронной почте ни к чему хорошему, в большинстве случаев, не приводит. Как правило, вы будете получать назад ваши же письма откомментированные администратором, который в момент отправки этого письма мгновенно забывает о ваших проблемах. Вообще, вся эта переписка напоминает разговор двух склеротиков, когда строк типа: «В письме от такого-то числа пользователь написал...» становится больше, чем содержательной информации. Выискивать в большом письме комментарии, которые могут занимать не больше двух слов трудно и нудно. Особенно глупо это выглядит, если вы, того не ведая, вступите в переписку с автоматом. Я никому не хочу навязывать правила поведения в сети, но должны же существовать какие-то нормы, обусловленные здравым смыслом.
При размещении сервера домена следует позаботиться о том, чтобы существовал вторичный (secondary) сервер имен вашего домена. Согласно большинству рекомендаций, следует иметь от 2-х до 4-х серверов на случай отказа основного сервера доменных имен.
Вообще говоря, можно вести переговоры о создании вторичного сервера доменных имен и с самим РосНИИРОС и с любым провайдером. Но за услуги последнего придется заплатить. Можно запустить вторичный сервер и на одном из своих компьютеров, но в этом случае вы просто выполните требования РосНИИРОС формально, так как надежности процедуре разрешения имен вашего домена такое решение не принесет.
|
|
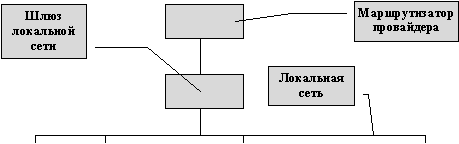
Рис.3.4. Схема подключения локальной сети к провайдеру
Действительно, если ваша сеть подключена к провайдеру через один единственный шлюз (рисунок 3.4), то все ваши компьютеры, оказываются за шлюзом. При отказе шлюза все они для внешнего пользователя сети исчезают, а это значит, что если сервер доменных имен расположен на шлюзе или одном из компьютеров вашей сети, то для внешнего пользователя и их имена исчезнут также, в отличии от IP-адресов, которые прописаны в маршрутизаторе провайдера.
На первый взгляд кажется, что если нет доступа, то и трансляция доменных имен в IP-адресе не нужна. Однако, это не совсем так. Если система не может разрешить доменное имя, то она сообщает – «unknown host», т.е. система такого компьютера не знает. Если же доменное имя успешно транслируется в IP-адрес, то, в случае потери связи, система сообщает – «host unreachable», т.е. система знает о такой машине, но в данный момент достичь эту машину нет никакой возможности.
В критических ситуациях не всегда можно быстро сообразить, что происходит в сети, поэтому разница в сообщениях важна - она позволяет избежать лишних непродуманных действий.
В РосНИИРОС регистрируют не только «прямую» зону, но также и «обратную». Это две самостоятельные заявки. Понятие «прямая» зона - это калька с английского - forward zone, а понятие «обратная» зона - reverse zone. «Прямая» зона определяет соответствие доменного имени IP-адресу, в то время, как «обратная» зона определяет обратное соответствие IP-адреса доменному имени.
3.1.4. Серверы доменных имен и механизм поиска IP-адреса
В данном разделе речь пойдет о программе, которая называется named. Именно она используется в большинстве Unix-систем в качестве реализации Berkeley Internet Name Domain - BIND.
Как и любой другой сервис прикладного уровня, а система доменных имен - это сервис прикладного уровня, программа named использует транспорт TCP и UDP (порты 53). Очень часто пользователи сообщают администратору системы, что та или иная машина системе не известна, хотя вчера с ней можно было работать. При этом, как правило, называют доменные имена компьютеров. Первое, что следует проверить в этой ситуации - реальную доступность к компьютеру по его IP-адресу. Проблема действительно является серьезной, если и по IP-адресу нельзя «достучаться» до удаленной машины, в противном случае следует искать ошибки или отказы в работе сервиса доменных имен.
Сервис BIND строится по схеме «клиент-сервер». В качестве клиентской части выступает процедура разрешения имен - resolver, а в качестве сервера, в нашем случае, программа named.
Resolver, собственно, не является какой-либо программой. Это набор процедур из системной библиотеки (libс.a), которые позволяют прикладной программе, отредактированной с ними, получать по доменному имени IP-адрес компьютера или по IP-адресу доменное имя. Сами эти процедуры обращаются к системной компоненте resolver, которая ведет диалог с сервером доменных имен и таким образом обслуживает запросы прикладных программ пользователя.
На запросы описанных выше функций в системах Unix отвечает программа named. Идея этой программы проста - обеспечить как разрешение, так называемых, «прямых» запросов, когда по имени ищут адрес, так и «обратных», когда по адресу ищут имя. Управляется named специальной базой данных, которая состоит из нескольких фалов, и содержит соответствия между адресами и именами, а также адреса других серверов BIND, к которым данный сервер может обращаться в процессе поиска имени или адреса.
Общую схему взаимодействия различных компонентов BIND можно изобразить так, как это представлено на рисунке 3.5.
|
|
Рис. 3.5. Нерекурсивная процедура на разрешение имени
Опираясь на схему нерекурсивной процедуры разрешения имени (рисунок 3.5) рассмотрим два способа разрешения запроса на получение IP-адреса по доменному имени.
В первом случае будем рассматривать запрос на получение IP-адреса в рамках зоны ответственности данного местного сервера имен:
1. Прикладная программа через resolver запрашивает IP-адрес по доменному имени у местного сервера.
2. Местный сервер сообщает прикладной программе IP-адрес запрошенного имени.
Для того, чтобы еще больше прояснить данную схему взаимодействия рассмотрим несколько примеров, когда появляется запрос на получение IP-адреса по доменному имени.
При входе в режиме удаленного терминала на компьютер polyn.net.kiae.su по команде:
/usr/paul>telnet polyn.net.kiae.su
Мы получаем в ответ:
/usr/paul>telnet polyn.net.kiae.su
trying 144.206.130.137 ...
login:
.....
Строчка, в которой указан IP-адрес компьютера polyn.net.kiae.su, показывает, что к этому времени доменное имя было успешно разрешено сервером доменных имен и прикладная программа, в данном случае telnet получила на свой запрос IP-адрес. Таким образом, после ввода команды с консоли и до появления IP-адреса на экране монитора прикладная программа осуществила запрос к серверу доменных имен и получила ответ на него.
Довольно часто можно столкнуться с ситуацией, когда после ввода команды довольно долго приходиться ждать ответа удаленной машины, но зато после первого ответа удаленный компьютер начинает реагировать на команды с такой же скоростью, как и ваш собственный. В данном случае, скорее всего в задержке виноват сервис доменных имен. Наиболее заметно такой эффект проявляется при использовании программы ftp. Например, при обращении к финскому архиву ftp.funet.fi, после ввода команды:
/usr/paul>ftp ftp.funet.fi
система долго не отвечает, но затем начинает быстро “сглатывать” и идентификатор и почтовый адрес, если входят как анонимный пользователь, и другие FTP-команды.
Другой пример того же сорта - это программа traceroute. Здесь задержка на запросы к серверу доменных имен проявляется в том, что время ответов со шлюзов, на которых “умирают” ICMP пакеты, указанное в отчете, маленькое, а задержки с отображением каждой строчки отчета довольно большие. В системе Windows 3.1 некоторые программы трассировки, показывают сначала IP-адрес шлюза, а только потом, после разрешения «обратного» запроса, заменяют его на доменное имя шлюза. Если сервис доменных имен работает быстро, то эта подмена практически незаметна, но если сервис работает медленно, то промежутки бывают довольно значительными.
Если в примере с telnet и ftp мы рассматривали, только «прямые» запросы к серверу доменных имен, то в примере с traceroute мы впервые упомянули «обратные» запросы. В «прямом» запросе прикладная программа запрашивает у сервера доменных имен IP-адрес, сообщая ему доменное имя. При «обратном» запросе прикладная программа запрашивает доменное имя, сообщая серверу доменных имен IP-адрес.
Следует заметить, что скорость разрешения «прямых» и «обратных» запросов в общем случае разная. Все зависит от того как описаны «прямые» и обратные «зоны» в базах данных серверов доменных имен, обслуживающих домен. Часто прямая зона бывает одна, а вот обратных зон может быть несколько, в силу того, что домен расположен на физически разных сетях или подсетях. В этом случае время разрешения «обратных» запросов будет больше времени разрешения «прямых» запросов. Более подробно этого вопроса мы коснемся при обсуждении файлов конфигурации программы named.
Процедура разрешения «обратных» запросов точно такая же, как и процедура разрешения «прямых» запросов, описанная выше.
|
|
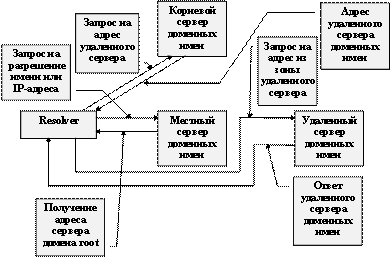
Рис. 3.6. Нерекурсивный запрос resolver
Собственно нерекурсивным, рассмотренный выше запрос является только с точки зрения сервера, т.е. программы named. С точки зрения resolver процедура разрешения запроса является рекурсивной, так как resolver перепоручил named заниматься поиском нужного сервера доменных имен. Согласно RFC-1035, resolver и сам может опрашивать удаленные серверы доменных имен и получать от них ответы на свои запросы. Во многих Unix-системах именно так оно и сделано. В этом случае resolver обращается к локальному серверу доменных имен, получает от него адрес одного из серверов домена root, опрашивает сервер домена root, получает от него адрес удаленного сервера нужной зоны, опрашивает этот удаленный сервер и получает IP-адрес если он посылал, так называемый “прямой” запрос.
Как видно из этой схемы resolver сам нашел нужный IP-адрес. Однако чаще всего resolver не порождает нерекурсивных запросов, а переадресовывает их локальному серверу доменных имен. Кроме этого и локальный сервер и resolver не все запросы выполняют по указанной процедуре. Дело в том, что существует кэш, который используется для хранения в нем полученной от удаленного сервера информации (рисунок 3.7).
|
|

Рис. 3.7. Схема разрешения запросов с кэшированием ответов
Если пользователь обращается втечение короткого времени к одному и том же ресурсу сети, то запрос на удаленный сервер не отправляется, а информация ищется в кэше. Вообще говоря, прядок обработки запросов можно описать следующим образом:
· поиск ответа в локальном кэше;
· поиск ответа на локальном сервере;
· поиск информации в сети.
При чем кэш может быть как у resolver’а, так и у сервера, но чаще всего эти временные хранилища информации о системе DNS объединяют.
Рассмотрим теперь нерекурсивный запрос прикладной программы к серверу доменных имен на получение IP-адреса по доменному имени из домена, который находится в ведении удаленного сервера доменных имен, т.е. сервера отличного от того, домену которого принадлежит компьютер, осуществляющий запрос. При рассмотрении этого запроса также будем опираться на схему с рисунка 3.5.
В общем виде такая схема будет выглядеть следующим образом:
1. Прикладная программа обращается к местному серверу доменных имен за IP-адресом, сообщая ему доменное имя.
2. Сервер определяет, что адрес не входит в данный домен и обращается за адресом сервера запрашиваемого домена к корневому серверу доменных имен.
3. Корневой сервер доменных имен сообщает местному серверу доменных имен адрес сервера доменных имен требуемого домена.
4. Местный сервер доменных имен запрашивает удаленный сервер на предмет разрешения запроса своего клиента (прикладной программы)
5. Удаленный сервер сообщает IP-адрес местному серверу.
6. Местный сервер сообщает IP-адрес прикладной программе.
Среди указанных выше примеров, пример обращения к финскому ftp-архиву как раз и является иллюстрацией такой много ступенчатой схемы разрешения «прямого» запроса.
Однако, не всегда при разрешении запросов местный сервер обращается к корневому серверу. Дело в том, что, как указывает Крэг Ричмонд, существует разница между доменом и зоной. Домен - это все множество машин, которые относятся к одному и тому же доменному имени. Например, все машины, которые в своем имени имеют постфикс kiae.su относятся к домену kiae.su. Однако, сам домен разбивается на поддомены или, как их еще называют, зоны. У каждой зоны может быть свой собственный сервер доменных имен. Разбиение домена на зоны и организация сервера для каждой из зон называется делегирование прав управления зоной соответствующему серверу доменных имен, или просто делегированием зоны.
При настройке сервера, в его файлах конфигурации можно непосредственно прописать адреса серверов зон. В этом случае, обращения к корневому серверу не производятся, т.к. местный сервер сам знает адреса удаленных серверов зон. Естественно, что все это относится к серверу, который делегирует права.
Существует еще и другой вариант работы сервера, когда он не запрашивает корневой сервер на предмет адреса удаленного сервера доменных имен. Это происходит тогда, когда незадолго до этого сервер уже разрешал задачу получения IP-адреса по данному доменному имени. Если требуется получить IP-адрес, то он будет просто извлечен из буфера сервера, т.к. втечение определенного времени, заданного в конфигурации сервера, этот адрес будет храниться в cache-сервере. Если нужен адрес из того же домена, который был указан в одном из имен, которые разрешались до этого, то сервер не будет обращаться к корневому серверу, т.к. адрес удаленного сервера для этого домена также хранится в кэше местного сервера.
Вообще говоря, понятия «зона» и «домен» носят локальный характер и отражают только тот факт, что при настройках и взаимодействии между собой серверы доменных имен исходят из двухуровневой иерархии. Это значит, что если в зоне необходимо создать разделение на группы, то зону можно назвать доменом, и в нем организовать новые зоны. Например, у компании Sun Microsystems есть зона russia в домене sun.com (russia.sun.com). Так вот, эту зону тоже можно разбить на зоны, например, info.russia.sun.com и market.russia.sun.com.[2]
Кроме нерекурсивной процедуры разрешения имен возможна еще и рекурсивная процедура разрешения имен. Ее отличие от описанной выше нерекурсивной процедуры состоит в том, что удаленный сервер сам опрашивает свои серверы зон, а не сообщает их адреса местному серверу доменных имен. Рассмотрим эти два случая более подробно.
На рисунке 3.8 продемонстрирована нерекурсивная процедура разрешения IP-адреса по доменному имени. Основная нагрузка в этом случае ложится на местный сервер доменных имен, который осуществляет опрос всех остальных серверов. Для того, чтобы сократить число таких обменов, если позволяет объем оперативной памяти, можно разрешить буферизацию (кэширование) адресов. В этом случае число обменов с удаленными серверами сократится.
На рисунке 3.9 удаленный сервер домена сам разрешает запрос на получение IP-адреса хоста своего домена, используя при этом нерекурсивный опрос своих серверов поддоменов.
|
|
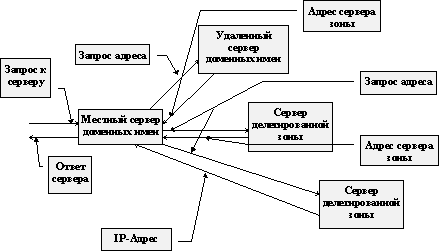
Рис. 3.8. Нерекурсивная обработка запроса на получение IP-адреса
|
|
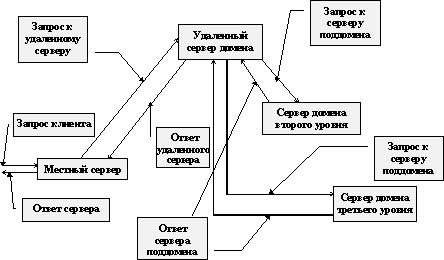
Рис. 3.9. Рекурсивная и нерекурсивная процедуры разрешения адреса по IP-имени
При этом локальный сервер сразу получает от удаленного сервера адрес хоста, а не адреса серверов поддоменов. Последний способ получения адреса называют рекурсивным, т.е. локальный и удаленный серверы взаимодействуют по рекурсивной схеме, а удаленный и серверы поддоменов по нерекурсивной.
Теперь от общих рассуждений перейдем к описанию настроек системы разрешения доменных имен в BIND.
3.1.5. Настройка resolver
Как уже говорилось выше, система разрешения доменных имен IP-адресами и обратная процедура построены по схеме «клиент-сервер». Функции из библиотеки libc.a выступают в качестве клиентов, и вся их совокупность носит название resolver. Для того, чтобы клиент мог обратиться к серверу, он должен знать следующее:
· Установлен ли вообще сервер доменных имен;
· Если сервер установлен, то где (IP-адрес);
· Если сервер установлен, то к какому домену относится машина.
Вся совокупность этих параметров задается в файле resolv.conf. Приведем пример этого файла и разберем назначение каждой из команд, которая может быть использована в файле настройки resolver.
Пример 2. Содержание файла resolv.conf.
# Resolver config for paul.
#
#nonameserver
domain polyn.kiae.su
nameserver 144.206.130.137
nameserver 144.206.136.1
Строки, начинающиеся с символа «#» - это комментарии. Среди них следует выделить строку «nonameserver». В нашем примере она не влияет на работу системы разрешения доменных имен, но если в сети нет сервера доменных имен, то следует с этой строки снять символ комментария, а прочие команды напротив превратить в комментарии. При отсутствии сервера доменных имен система будет использовать файл hosts.
По команде domain система определяет к какому домену она относится. Обычно, именем, которое указано после команды расширяются неполные имена хостов. Например, если обратиться к какой-либо машине только по ее имени:
/usr/paul> telnet radleg
то система расширит имя radleg именем домена и будет искать машину с именем radleg.polyn.kiae.su.
Указанный выше пример - это только частный случай процедуры расширения неполного имени, которая используется функциями resolver. В общем виде она выглядит следующим образом:
1. Если в прикладной программе указано имя хоста с точкой на конце, то расширение имени не производится:
/usr/paul>ping polyn.
В данном случае имя «polyn.» завершено точкой.
2. Если имя указано без точки, расширение производится по следующим правилам: либо происходит добавление имени домена, либо происходит обращение к файлу синонимов. Вообще говоря, в различных системах это расширение может быть организовано различными способами. Например, HP-UX имя фала синонимов указывается в переменной окружения HOSTALIASES. Пример расширения доменным именем был приведен выше.
3. Если в качестве имени указывается составное имя, то производится серия подстановок, при помощи которых пытаются получить IP-адрес хоста:
/usr/paul> ping paul.polyn.kiae
Если в качестве домена в resolv.conf указан домен polyn.kiae.su, то будет проверена следующая последовательность имен: paul.polyn.kiae.polyn.kiae.su; paul.polyn.polyn.kiae.su; paul.polyn.kiae.su. Последнее имя будет разрешено сервером доменных имен.
При указании имени домена следует также учитывать и то, как будет в этом случае работать вес комплекс программного обеспечения, установленный на данном компьютере. Дело в том, что некоторые программы, sendmail, например, способны сами решат проблему определения IP-адресов по именам. В ряде случаев это может привести к противоречиям и ошибкам при функционировании такого сорта программ (о настройках sendmail см. раздел «Электронная почта»).
Команда nameserver определяет адрес сервера доменных имен для домена, в котором данная машина состоит. Возможно указание нескольких серверов. Обычно - это не более трех серверов доменных имен. В таких системах как Windows NT, например, администратор просто не в состоянии указать более трех адресов серверов доменных имен.
Порядок в указании серверов в файле resolv.conf определяет порядок опроса серверов. Таким образом, первым в нашем случае будет опрашиваться сервер с адресом 144.206.130.137, а затем сервер с адресом 144.206.136.1. Наиболее целесообразно первым указывать основной сервер доменных имен данного домена, а вторым дублирующий сервер доменных имен данного домена[3].
В качестве сервера доменных имен можно также указать и сервер вышестоящего домена, что позволит подстраховаться на случай отказа основного и вспомогательного серверов. При этом не будут решены проблемы адресации машин данного домена, но зато не пропадет возможность обращаться по имени к машинам, расположенным за пределами домена.
В настройках resolver надо также учитывать возможность запуска программы named, которая будет работать как кэш-сервер, что на машинах с «интеллектуальным» resolver’ом, что позволяет обеспечить более эффективную процедуру разрешения запросов к системе DNS.
3.1.6. Программа named
К сожалению достаточно подробной единой документации по named, в которой было бы приведено достаточно большое множество примеров описания файлов настроек named для различных конфигураций доменов, в природе (в архивах сети Internet, да и в книгах, посвященных проблеме администрирования сетей TCP/IP) не существует. Данное описание также не претендует на полный обзор возможностей named, но позволяет некоторым образом упорядочить представление об этих возможностях. Кроме того, в данном разделе приводятся примеры из практики настройки этого сервера доменных имен, которые могут быть полезны в практической работе и отражают наиболее типичные случаи организации доменов.
Программа named является одним из наиболее популярных серверов доменных имен из тех, что используются в Internet. Для своей работы она использует 53 порты TCP и UDP.
При разработке named была реализована концепция функционирования трех типов серверов доменных имен: primary, secondary, cache. Если быть более точным, то named может одновременно выполнять функции всех трех типов серверов.
Primary server - это основной сервер зоны[4]. В его базе данных описывается соответствие доменных имен и IP-адресов для машин, принадлежащих данной зоне. База данных сервера хранится на том же компьютере, где и функционирует сервер доменных имен. При запуске сервера последний обращается к файлам своей базы данных, после чего он становится способным отвечать на запросы разрешения доменных имен IP-адресами и обратно.
Secondary server - это дублирующий сервер зоны. Он также способен отвечать на запросы прикладных программ и других серверов, требующих разрешения доменных имен IP-адресами и/или наоборот, как и primary server. Главное отличие от primary server заключается в том, что secondary server не имеет своей базы данных зоны, а копирует ее с primary server в момент своего запуска и затем заботится о поддержке соответствия между скопированной базой данных и базой данных primary server в соответствии с настройками последнего.
Caсhe server - это сервер, который запоминает в своем буфере (caсhe) соответствия между именами и IP-адресами и хранит их некоторое время. Если пользователь достаточно часто обращается к каким-либо ресурсам сети, то в случае использования caсhe-сервера он всегда будет быстро получать IP-адрес или доменное имя, т.к. его прикладное программное обеспечение будет пользоваться услугами caсhe-сервера. При этом обращение к местному серверу зоны, корневому серверу и удаленным серверам зон будут осуществляться только один раз - в момент первого обращения к ресурсу.
Для организации зоны (домена) необходимо иметь primary server[5] и, как минимум один secondary server. Если с primary server все более или менее понятно - он создается на компьютере, который входит в описываемый домен и управляется администратором домена, то размещение secondary server всегда вызывает определенные трудности. Как уже говорилось выше, его можно создать на другом компьютере домена и тем самым формально выполнить условия по организации двух серверов доменных имен для одной зоны[6]. Но в этом решении есть два нюанса. Во-первых, организация второго сервера доменных имен заставляет устанавливать либо еще одну Unix-машину, либо Windows NT, в которых есть поддержка BIND. Во-вторых, с точки зрения надежности secondary server лучше всего размещать у провайдера, т.к. обычно именно он делегирует зону из своего домена, и через его сервер доменных имен по рекурсивной или нерекурсивной процедуре разрешения имени весь остальной мир получает доступ к машинам вашего домена.
Если же домен распределен по нескольким сетям или подсетям, которые к тому же и территориально расположены в разных зданиях или различных частях города, или даже в разных городах, то тогда для каждой из этих частей домена следует организовать secondary server, что не отменяет размещения secondary server у провайдеров, поддерживающих такую распределенную систему.
В любом случае secondary server всегда не один, но каждый администратор должен сам решать, сколько их надо заводить. Кроме этого если сервер заводится у коммерческого провайдера, то за него придется платить.
О второй Unix-машине или Windows NT было упомянуто из тех соображений, что многие маленькие локальные сети строятся по схеме, в которой многозадачная и многопользовательская операционная система ставится только на машине-шлюзе, через которую локальная сеть подключается к сети провайдера. На всех остальных машинах устанавливается либо Windows 95, либо MS-DOS, одним словом персональная операционная система.
Совершенно очевидно, что выделять еще одну машину для общественных нужд не очень хочется, а свою собственную зону иметь желательно. Поэтому, либо обращаются к провайдеру с запросом на размещение secondary server, либо договариваются с кем-то еще.
Любой сервер является кэширующим сервером. И primary, и secondary серверы запоминают на некоторое время, в своем буфере (cache) соответствие между именами и IP-адресами любой зоны, если к ней хоть раз обращались, и была выполнена процедура разрешения адреса. Это позволяет сократить обмен запросами между серверами и обеспечить более быстрое разрешение адреса для часто используемых ресурсов.
Организация на базе named только кэширующего сервера основано на том предположении, что primary и secondary серверы зоны могут быть перегружены запросами (типичный случай для большой организации). В этих условиях время на разрешение имени может быть довольно значительным. Кэширующий сервер на вашей вычислительной установке позволит несколько сократить это время, если вы постоянно обращаетесь к одним и тем же хостам. Ждать придется только при первом обращении, когда будет выполняться стандартная процедура разрешения адреса, все последующие обращения будут удовлетворяться вашим кэширующим сервером.
Если число зон, к которым вы обращаетесь не очень велико, то для них на вашей вычислительной установке имеет смысл сделать secondary server для этих зон (если конечно позволяют ресурсы вашего компьютера). При этом ни у кого регистрировать ваш secondary server не надо. В этом случае для указанных зон вы просто создаете долговременный кэш, который обслуживает только вашу зону.
От общего описания типов серверов, которые можно организовать при помощи программы named прейдем к файлам ее настройки.
3.1.6.1. Файлы настройки named
Всего существует три типа файлов настройки программы named, или, как их еще называют, базы данных домена. К ним относятся:
· файл начальной загрузки буфера (cache);
· описания базы данных, он называется named.boot;
· файлы описания «прямой» и «обратной» зон.
В литературе по named принято начинать с файла описания базы данных named - named.boot
Этот файл named использует для своей настройки и первичной загрузки базы данных домена. Это первое, что ищет named при своем запуске. Если внимательно изучить скрипты начальной загрузки любого Unix, то при запуске сетевых серверов в части, отвечающей за запуск сервера доменных имен, можно увидеть, что в случае отсутствия файла named.boot программа named не будет запущена.
В файле named.boot для описания настроек named используются следующие команды:
· directory - адрес директории в файловой системе компьютера, на котором запускается named.
· primary - определяет зону, для которой данный сервер является primary server, и имя файла базы данных этой зоны. Файл размещается в директории, которая указана в команде directory.
· secondary - определяет зону, для которой данный сервер является secondary server, а также определяет адреса других серверов для этой зоны, обычно primary server, и имя файла где будет вестись копия базы данных этой зоны. Файл размещается в директории, указанной в команде directory.
· cache - определяет имя кэш-файла. Обычно в кэш-файле описаны адреса и имена корневых серверов, которые данный сервер будет использовать для получения адресов удаленных серверов доменных имен.
· forwarders - данная команда определяет адреса серверов доменных имен куда следует отправлять не разрешенные запросы.
· slave - заставляет сервер отправлять все запросы на серверы, которые определены командой forwarders.
Прежде, чем рассматривать примеры файлов named.boot для различных типов серверов, хотелось бы обратить внимание читателя на две последние команды.
Фактически, именно они и определяют какая из процедур разрешения запроса (рекурсивная или нерекурсивная) будут применяться на вашем сервере. Если в файле named.boot есть команда slave, то определена рекурсивная процедура разрешения запроса, т.к. в этом случае named будет отсылать все запросы на серверы указанные в команде forwarders и от них получать адреса или имена удаленных хостов. В этом случае серверы из forwarders будут опрашивать корневые и удаленные серверы доменов. Если эти серверы также содержат команду slave, то поиск адреса или имени будут осуществлять серверы, которые определены в их файлах named.boot как forwarders.
Когда такая конфигурация сервера полезна? На сколько мне известно, обычно так настраивают серверы поддоменов внутри одной организации. В качестве сервера, на который осуществляется пересылка всех запросов, используется сервер всего домена. При этом с корневыми серверами общается только этот сервер, серверы зон самостоятельно на корневые серверы запросов не отправляют. Если число машин за пределами данного домена, с которыми общаются пользователи данного домена, не очень велико, и все они компактно расположены в других доменах, то центральный сервер домена быстро заполнит свой кэш необходимой для разрешения запросов информацией. При этом такой кэш будет только один, а работать он будет с той же скоростью, как если бы каждый из серверов зон создавал его у себя.
С точки зрения самого домена в любом случае сервер зоны обращается к серверу домена за адресами из другой зоны, если только сервер другой зоны не указан в файлах базы данных named.
Приведем теперь пример файла named.boot, в котором проиллюстрируем использование указанных выше команд.
Пример 3. Содержание файла named.boot
;An Example of the named.boot [7]
;
directory namedb
primary 0.0.127.in-addr.arpa localhost
primary vega.ru vega
primary 43.226.194.in-addr.arpa vega.rev
secondary polyn.kiae.su 144.206.130.137 144.206.192.34 polyn
secondary 160.206.144.in-addr.arpa 144.206.130.137 144.206.192.34 polyn.rev
cache . named.root
Обычно, файл named.boot размещается в директории /etc. От этой директории затем идет отсчет места компонентов базы данных named. В нашем случае эту базу данных можно представить в виде графа (рисунок 3.10), у которого в качестве корня выступает директория /etc. В /etc существует поддиректория namedb, в которой располагаются все остальные файлы.
|
|
Рис.3.10. Структура
размещения файлов базы данных named из
примера 3
Сопоставив рисунок 3.10 и описание из примера 3, легко догадаться, что последняя колонка в каждой из команд описания настроек named заканчивается именем соответствующего файла или директории. Рассмотрим формат каждой команды более подробно.
Команда directory определяет директорию namedb как директорию размещения файлов базы данных named. Вообще говоря, вовсе не так уж обязательно размещать все файлы в одной директории. Можно создать несколько директорий, например, по количеству зон. Christophe Wolfhugel, например, для каждой зоны использует отдельную поддиректорию в корневой директории named. Если придерживаться этой логики размещения файлов, то получим следующее.
Пример 4. Содержание файла named.boot при размещении файлов описания зон для primary и secondary серверов по разным директориям
;An Example of the named.boot
;
directory namedb
primary 0.0.127.in-addr.arpa localhost
primary vega.ru v/vega
primary 43.226.194.in-addr.arpa v/vega.rev
secondary polyn.kiae.su 144.206.130.137 144.206.192.34 p/polyn
secondary 160.206.144.in-addr.arpa 144.206.130.137 144.206.192.34 p/polyn.rev
cache . named.root
В примере 4 в директории namedb определены две поддиректории v и p. В директории v размещаются файлы зон vega.ru и 43.226.194.in-addr.arpa, для которых данный сервер является primary. В свою очередь в директории p размещаются файлы описания зон polyn.kiae.su и 160.206.144.in-addr.arpa, для которых данный сервер является secondary сервером. Если представить структуру файлов в виде графа, то получится граф типа графа на рисунке 3.11.
|
|
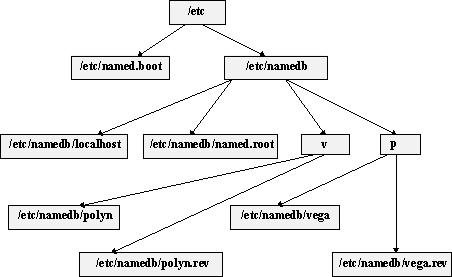
Рис. 3.11. Дерево файлов описания базы данных named из примера 4
Вообще говоря, корнем описания файлов базы данных named может быть директория отлична от /etc. Если программу named запустить с флагом «-f», то в качестве параметра можно указать полный путь к файлу named.boot или к другому файлу, который используется вместо named.boot:
/usr/paul>named -f /usr/paul/named.par
В этом случае в качестве корневой директории для файлов описания базы данных named будет использоваться директория /usr/paul, а в качестве файла named.boot файл named.par из этой директории.
Кроме того, в команде directory, как это определено в наших примерах, используется, так называемый, неполный путь к директории, где расположены файлы базы данных named. Однако, можно указывать и полный путь, что дает возможность расположить эти файлы где угодно в файловой системе сервера. Например, если файлы расположены в директории /usr/local/etc/namedb, то в файле named.boot следует указать следующую команду directory:
directory /usr/local/etc/namedb
Команда primary используется для указания зоны, для которой данный сервер выступает как primary сервер, и указания имени файла, который эту зону описывает. Формат команды primary можно описать следующим образом:
primary <имя зоны> <имя файла описания зоны>
В примерах 3 и 4 используется три команды primary. Первая описывает «обратную» зону 0.0.127.in-addr.arpa, вторая команда описывает «прямую» зону vega.ru и третья команда описывает «обратную» зону 43.226.194.in-addr.arpa. Наличие двух «обратных» зон вызвано тем, что прямая зона определена на двух сетях - 194.226.43.0 и 127.0.0.0.
Сеть 127.0.0.0 - это особая сеть, поэтому первая команда должна быть на любом сервере доменных имен, т.к. она служит для определения обратной зоны 0.0.127.in-addr.arpa, которая закреплена за любой машиной, на которой установлен стек протоколов TCP/IP. Особое назначение этого домена следует из особого значение IP-адресов, которые закреплены за ним. Они обозначают «петлю», т.е. при отправке пакетов по адресу, например, 127.0.0.1 пакеты не выходят за пределы одного компьютера, т.е. они не попадают в реальную сеть. В некоторых реализациях стека определенное значение имеют и другие адреса сети 127, например, 127.0.0.2 и 127.0.0.3 в HP-UX.
Очень часто в примерах описания файла named.boot можно встретить строчку:
primary 0.0.127.in-addr.arpa 0.0.127.in-addr.arpa
Повторение имени домена в качестве второго аргумента означает только то, что в директории файлов описания базы данных named должен быть файл с таким именем. Для тех, кто привык к тому, что в файловой системе MS-DOS разрешены только трехбуквенные расширения имени файла, подобное имя выглядит довольно странно, но у энтузиастов Unix это не должно вызывать затруднений. Использование имен зон в качестве имен файлов - это общепринятая практика. Так гораздо проще ориентироваться среди файлов описания базы данных named.
Часто вместо 0.0.127.in-addr.arpa указывают 127.in-addr.arpa. Сеть 127 - это сеть класса А. Для этой сети что 127, что 127.0, что 127.0.0 - суть одно и тоже. Так как при указании обратной зоны числа в IP-адресах указываются в обратной последовательности, то 0.0.127.in-addr.arpa и 127.in-addr.arpa также означают одно и тоже. Вообще говоря, обработка этой обратной зоны согласно RFC-1035 производится особым способом.
Среди специалистов по named нет единства мнений о стиле определения прямых и обратных зон, в том числе, и о зоне 0.0.127.in-addr.arpa. Некоторые предлагают ввести «прямую» зону, которая бы соответствовала «обратной» зоне 0.0.127.in-addr.arpa. Связано это с доменным именем, которое ставится в соответствие с адресом 127.0.0.1. Но к этому вопросу вернемся при обсуждении содержания самих файлов описания зон.
Команда secondary используется для описания зон, для которых данный сервер является secondary сервером, и имеет следующий формат:
secondary <имя зоны> <список IP-адресов серверов зоны> <имя файла описания зоны>
В наших примерах описано две зоны, для которых данный сервер является secondary сервером - polyn.kiae.su и 160.206.144.in-addr.arpa. В примерах для каждой из этих зон указано по два IP-адреса серверов, которые описывают зону. Вообще говоря, достаточно указывать адрес только primary сервера для зоны. С точки зрения актуальности состояния базы данных зоны, для которой создается secondary сервер, указание одного только primary наиболее правильное решение, т.к. только primary сервер содержит наиболее актуальную базу данных зоны. Однако, в ряде случаев, имеет смысл указать несколько серверов, primary и secondary, например, в случае указания нескольких серверов, база копируется с того, который указан первым, если он доступен. Если сервер не доступен, то опрашивается следующий в списке, до первого доступного сервера.
Файл, который указан последним аргументом в команде secondary, создается named при запуске и постоянно обновляется в соответствии с описанием взаимодействия primary и secondary серверов. Редактировать вручную этот файл не имеет смысла, т.к. это калька с primary сервера, и через постоянные промежутки времени этот файл обновляется программой named. Таким образом, если кто-либо и внесет в него изменения, то named, создавая новую копию базы данных зоны, затрет эти изменения.
В отличии от primary, secondary сервер не способен поддерживать разрешение запросов сколь угодно долго. Как только истечет время актуальности данных в его базе данных, он пытается создать новую копию базы с базы данных primary сервера. Если это не удается, то сервер перестает обслуживать зону.
Главное назначение secondary сервера - это повышение надежности службы доменных имен. Описание зоны named копирует с серверов, указанных в качестве аргумента команды secondary. Там указаны не только primary сервер, но и другие secondary серверы. Зона копируется с того сервера, который доступен. Это значит, что на данном сервере может оказаться копия с другого secondary сервера, что, вообще говоря, не очень хорошо, если речь идет о сервере, который действительно предназначается для дублирования зоны.
В самом начале описания BIND было сказано, что сервис работает по 53 портам UDP и TCP. Для чего для одного и того же сервиса было организовывать информационные магистрали с использованием различных типов транспорта? Дело в том, что обычные запросы на разрешение имен IP-адресами или IP-адресов именами отправляются по транспорту UDP. Это делается из-за того, что объем передаваемой информации небольшой. Но при организации secondary сервера ситуация меняется. Этот сервер запрашивает другой сервер, прописанный в команде secondary, целиком все описание зоны, а это может быть довольно большой объем информации. Вот в этом случае и используется сервис TCP. Из-за такой архитектуры проистекают многие проблемы связанные как со скоростью обслуживания запросов к системе доменных имен, так и с безопасностью сети вообще.
Скорость DNS – «это притча во языцах». При установке больших временных интервалов ожидания ответов отказ на обслуживание приходит только после истечения времени ожидания для данного сервиса UDP. Это если сервис неактивен. Если сервис активен, то нельзя точно установить работает он или нет, т.к. сервис UDP - это сервис без установки соединения. Но если говорить о копировании зон, то можно столкнуться со следующей ситуацией: запросы разрешаются, а зоны не копируются. В этом случае кроме администратора данного сервера никто ничего сказать не может. Администратор может намеренно запретить копирование зоны, а может быть за отведенный интервал времени не удается передать зону, или во время передачи разрывается TCP сессия. Для российской части Internet такое случается довольно часто. Если вдруг пользователям кажется, что система начинает медленно «умирать», то это может происходить из-за того, что secondary сервера не могут обновить описания зон, а так как копии могут быть получены в разное время, то сервера «мрут» в разное время.
Команда cache служит для определения файла с начальными данными для запуска named. Для того, чтобы начать отвечать на запросы named должна знать адреса других серверов доменных имен, к которым можно было бы обратиться с запросами на разрешение IP-адреса по имени или имени по IP-адресу.
Формат команды выглядит следующим образом:
cache <имя зоны> <имя файла cache>
Обычно обсуждение cache сводится к обсуждению того, какие корневые серверы должны быть указаны в файле cache, и как поддерживать актуальность этого файла. Прежде, чем обратиться к формату команды, замечу, что не только корневые серверы могут указываться в файле cache, но также и другие серверы, которые часто используются для разрешения запросов в вашем домене.
Согласно материалу Крега Ричмонда (Craig Richmond) различные версии named по разному используют файл, указанный в команде named. Одни программы, загрузив данные из этого файла, больше его не используют, другие наоборот, постоянно вносят в него изменения.
В случае стабильного файла администратор системы должен сам заботиться о его актуальности. Для этого он должен регулярно проверять соответствие между его файлом и файлом, который поддерживается в ns.internic.net. Получить копию файла можно либо, с ftp-сервера ftp.rs.internic.net, либо по команде:
/usr/paul>dig @ns.internic.net.ns > root.cache
Том Ягер (Tom Yager) рекомендует другой источник получения cache - ftp://nic.ddn.mil/netinfo/root-servers.txt.
Пример 5. Файл cache (Февраль 1996 года)
; Servers from the root domain
; ftp://nic.ddn.mil/netinfo/root-servers.txt
. 99999999 IN NS A.ROOT-SERVERS.NET
. 99999999 IN NS B.ROOT-SERVERS.NET
. 99999999 IN NS C.ROOT-SERVERS.NET
. 99999999 IN NS D.ROOT-SERVERS.NET
. 99999999 IN NS E.ROOT-SERVERS.NET
. 99999999 IN NS F.ROOT-SERVERS.NET
. 99999999 IN NS G.ROOT-SERVERS.NET
. 99999999 IN NS H.ROOT-SERVERS.NET
. 99999999 IN NS I.ROOT-SERVERS.NET
; Root servers by address
A.ROOT-SERVERS.NET 99999999 IN A 198.41.0.4
B.ROOT-SERVERS.NET 99999999 IN A 128.9.0.107
C.ROOT-SERVERS.NET 99999999 IN A 192.33.4.12
D.ROOT-SERVERS.NET 99999999 IN A 128.8.10.90
E.ROOT-SERVERS.NET 99999999 IN A 192.203.230.10
F.ROOT-SERVERS.NET 99999999 IN A 192.5.5.241
G.ROOT-SERVERS.NET 99999999 IN A 192.112.36.4
H.ROOT-SERVERS.NET 99999999 IN A 128.63.2.53
I.ROOT-SERVERS.NET 99999999 IN A 192.36.148.17
Формат записей этого файла мы обсудим позже при рассмотрении форматов записей файлов базы данных описания зоны.
Все, что было сказано о содержании файла из команды cache относится к случаю, когда в качестве имени зоны указана «.». Это означает, что описывается корневая зона, что в свою очередь означает описание корневых серверов доменных имен, к которым named обращается при работе в режиме нерекурсивной процедуры разрешения запросов на IP-адрес по имени или запросов на имя по IP-адресу.
Если в файл chache необходимо внести другую информацию, то это делается аналогично описанию корневых серверов. Реализация файла cache, отличного от указанного в примере 5 будет рассмотрена для случая делегирования зоны в домене.
Команда forwarders определяет IP-адреса серверов, на которые следует отправлять неразрешенные данным сервером запросы. Команда имеет следующий вид:
forwarders <список IP-адресов серверов>
Случай организации рекурсивной процедуры разрешения имени с использованием этой команды был рассмотрен ранее. Однако этим случаем не ограничивается круг использования команды forwarders. При регистрации домена некоторое время внешний (относительно этого домена) мир не подозревает о существовании домена. Должно пройти некоторое время, прежде чем будет закончена процедура регистрации домена и обновления баз данных вышестоящего в иерархии DNS домена на всех серверах как primary, так и secondary. Однако внутри домена все работает нормально, т.к. сервер запускается до официальной регистрации и способен обслуживать машины домена. Однако, он может и не знать информации о всех доменах Internet. По этой причине всегда полезно указать команду forwarders на сервер домена вышестоящего относительно данного домена. Так, например, для зоны polyn.kiae.su сервером домена kiae.su, в который входит данная зона, является сервер с IP-адресом 144.206.136.1. Для того, чтобы пересылать на него запросы на разрешение имен IP-адресами в named.boot следует включить команду:
forwarders 144.206.136.1
Обычно указывают не один, а несколько IP-адресов серверов, которые в состоянии ответить на запросы клиентов, на которые данный сервер ответить не может. Например, для сервера зоны vega.ru, который запущен, но еще не зарегистрирован, можно указать два сервера:
forwarders 144.206.136.1 144.206.130.137
Команда slave указывается тогда, когда сервер общается с внешним миром через серверы-посредники, указанные в команде forwarders. Параметров у данной команды нет. Файл named.boot для того сервера, если он еще и primary сервер для зон vega.ru и 43.226.194.in-addr.arpa будет выглядеть так, как показано в примере 6.
Пример 6. Подчиненный сервер, работающий по рекурсивной процедуре разрешения запросов от resolver
; An Example of the named.boot[8]
;
directory namedb
primary 0.0.127.in-addr.arpa localhost
primary vega.ru vega
primary 43.226.194.in-addr.arpa vega.rev
cache . named.root
forwarders 144.206.130.137 144.206.136.1 slave
Фактически, команда slave позволяет организовать, в некотором смысле, «интеллектуальный» resolver.
Перейдем теперь к описанию содержания файлов базы данных named. Все эти файлы состоят из записей, которые имеют одинаковый формат и называются записями описания ресурсов.
Формат записи определяется документом RFC-1033, и имеет следующий вид:
<name> <ttl> <class> <type> <data>
Все поля отделяются друг от друга пробелом или табуляцией. Каждое из них имеет следующее значение:
Поле name - это имя объекта. Объектом может быть хост, домен и поддомен. Существуют специальные правила именования объектов, которые базируются на понятии текущего имени домена. Программа named анализирует файл базы данных, начиная с первой записи последовательно до последней записи файла. Первоначально текущим именем домена является имя, указанное в командах primary, secondary или cache файла named.boot, в зависимости от того о каком файле базы данных named идет речь, если первая запись этого файла содержит имя @. В противном случае для определения текущего имени должна быть указана команда $ORIGIN. Если имя в записи описания ресурса опущено, то ресурс относится к текущему имени домена. Если имя указано без точки на конце, то оно расширяется текущим именем домена. Для изменения текущего имени домена следует ввести либо команду $ORIGIN, либо указать имя записи ресурса с точкой на конце. Если в качестве имени указана одна точка («.») или две точки («..») то такая запись описывает домен root, т.е. корневой домен. Если в имени записи встречается символ «*», то это он означает что вместо него можно подразумевать любую разрешенную последовательность символов. В англоязычных источниках это называют «wildcard character». Для пользователей любой операционной системы употребление этого символа хорошо знакомо по командам dir (MS-DOS) или ls (Unix). Например, при необходимости получить список файлов, оканчивающихся расширением «bak», выдается команда:
/usr/paul>ls *.bak
Точно также используется этот символ и в имени записи базы данных описания домена. Если в поле имени указан только символ «*», то это предполагает «*.<имя текущего домена>». Если за «*» следует имя, то оно ограничивает расширение имен «*». Например, «*.polyn.kiae.su.» определяет все имена из домена polyn.kiae.su, в том числе и имена машин в поддоменах, а не только имена машин в домене и имена самих поддоменов. Наиболее часто «*» используется в записях MX, которые регулируют обмен электронной почтой.
Поле ttl - это поле определяет время (в секундах), втечение которого данная запись сохраняется в кэше. Значение поля задается в виде восьми десятичных цифр, таким образом, максимальное значение ttl - 99999999. Именно это значение и задается для корневых серверов доменных имен в примере 5. Если это поле оставлено пустым, то по умолчанию принимается значение, указанное в параметре minimum поля данных (data) записи SOA для данной зоны.
Поле class определяет класс записи описания ресурса. В Internet используется только один класс записей - класс IN. В принципе существуют еще классы HS (Hessiod) и CH (Chaos), но в рамках нашего предмета - системы доменных имен Internet, они не рассматриваются. Некоторые авторы, например, Ronny H.Kavli, который написал комментарии к FAQ Kaig Richmond, считает, что наличие этого поля только «замутняют чистый лик» базы данных описания ресурсов DNS. В любом случае все записи из базы данных named имеют вид:
<name> <ttl> IN <type> <data>
Поле type определяет тип записи описания ресурсов. К таким типам относятся: SOA (Start Of Authority), NS (Name Server), A (Address), MX (Mail eXchanger) CNAME (Canonical NAME), WKS (Well Known Services), PTR (PoinTeR), HINFO (Host INFOrmation). Перечисленные выше типы записей составляют набор стандартных записей, которые могут встретиться в базе данных описания домена. Кроме этих типов существуют еще и экспериментальные типы. Все они касаются, главным образом, возможностей управления почтой. Следует заметить, что не все стандартные записи используются в базах данных описания доменов. Так российские администраторы редко пользуются записями типа HINFO и WKS. Некоторые администраторы считают, что вместо CNAME лучше назначить еще один адрес через запись типа A, существуют и другие предпочтения.
В поле data указываются данные для каждой записи описания ресурсов. Для различных типов записей формат данных также различный и соответствует назначению записи описания ресурсов.
Кроме записей описания ресурсов в файлах описания базы данных домена могут встречаться и другие записи. Самые распространенные из них - это записи комментариев. Запись комментария начинается с символа «;» в первой позиции строки. Все, что следует до конца строки, рассматривается в этом случае как комментарий. Если этот символ встретится в середине строки, то программа предполагает, что все, что следует далее до конца строки - это комментарий. При разборе записей описания ресурсов я постараюсь обратить внимание на использование комментариев.
Если данные не помещаются в пределы экрана, то можно использовать продолжение описания записи на другую строку. Я не пишу здесь «если данные не помещаются на одной строке», т.к. это будет не верно с точки зрения представления файла базы данных в файловой системе. В принципе длина строки может иметь достаточно большую длину, достаточную для того, чтобы вместить описание записи ресурсов, но это неудобно для редактирования файла базы данных, т.к. длина отображаемой строки на экране большинства алфавитно-цифровых дисплеев ограничена 80-ю символами. В описании файла базы данных домена не предусмотрен символ продолжения записи типа «\» в csh Unix. В качестве механизма продолжения записей используется пара скобок «(“, “)». Если в некоторой строке встретилась открывающая скобка «(«, то все данные до закрывающей скобки будут приписаны к этой строке.
Другим механизмом, который используется при описании элементов записи описания ресурса, является маскирование символов. Маскирование символов применяется в том, случае, если необходимо использовать символ, который имеет особое значение для записей описания ресурсов. Например, символ «@». Для этого используется символ обратного слэша «\». Аналогично языку программирования С символ можно указывать и цифрами. Только в этом случае используется десятичное число, которое соответствует коду ASCII, например, «\040» также обозначает символ «@».
3.1.6.2. Запись «Start Of Authority»
Перейдем теперь к описанию форматов записей описания ресурсов. Такое описание по традиции начинают с записи SOA (Start Of Authority). Запись SOA отмечает начало описания зоны. Обычно, это первая запись описания зоны. Некоторые авторы, в частности, упоминавшийся ранее Kavli, рекомендуют наличие одной и только одной записи типа SOA в каждом файле, который указан в записи primary файла named.boot.
Формат записи SOA можно представить как:
[zone] [ttl] IN SOA origin contact (serial refresh retry expire minimum )
В этой записи каждое из полей обозначает следующее:
Поле zone - имя зоны. Если речь идет о зоне, описанной в записи primary файла named.boot, то в качестве имени употребляется символ коммерческого эй – «@». В этом случае в качестве имени текущей зоны берется имя, указанное в качестве первого аргумента команды primary из файла named.boot. Поле зоны обязательно должно быть указано. Иначе named не сможет привязать следующие за данной записью описания к имени зоны. Пустое имя зоны не является допустимым.
Поле ttl в записи SOA всегда пустое. Дело в том, что время кэширования для записей описания зоны задается последним аргументом данных записи SOA.
Поле origin - это доменное имя primary сервера зоны. В случае описания зоны vega.ru в качестве сервера используется машина vega-gw.vega.ru. Данное доменное имя и должно быть указано в поле origin. Очень часто в этом поле можно встретить имена, которые начинаются с «ns», например, ns.kiae.su или ns.relarn.ru. В данном случае это означает только то, в данных зонах существуют машины с именем «ns», и на них размещены primary серверы этих зон. Никакого специального зарезервированного имени для указания в поле origin нет. Использование, указанных выше имен обосновано тем, что их просто легче запомнить, т.к. «ns» означает «name server».
Поле contact определяет почтовый адрес лица, осуществляющего администрирование зоны. Данный адрес должен совпадать со значением адреса указанным в заявке на домен в поле «zone-c:». Есть, однако, одна особенность при указании этого адреса. Так как символ «@» имеет особый смысл при описании зоны, то вместо этого символа в почтовом адресе используется символ «.». Например, если ваш покорный слуга выступает администратором домена, то в поле contact следует писать не paul@kiae.su, а paul.kiae.su. Если в имени пользователя есть какие-либо особые символы, имеющие специальные значения при описании зоны, то они должны маскироваться символом обратного слэша – «\». Типичный пример - почтовый адрес типа user.name@kuku.ru. В этом случае точку следует замаскировать и написать в поле contact: user\.name.kuku.ru. Поступая, таким образом, мы исключили особое значение точки как разделителя поддоменов и обеспечили интерпретацию имени как единой символьной строки.
Поле данных в записи SOA разбито на аргументы, которые определяют порядок работы сервера с записями описания зоны. Как правило, все аргументы располагают на другой строке или, для лучшего отображения каждый на своей строке, что заставляет записывать их внутри скобок.
Атрибут serial - определяет серийный номер файла зоны. Если говорить проще, то в этом поле ведется учет изменений файла описания зоны. Поле может состоять из восьми десятичных цифр. В принципе это могут быть любые числа, но чаще всего администраторы используют в качестве серийного номера год, месяц и день внесения изменений в файл описания зоны. Честно говоря, я предпочитаю просто порядковые имена. Во-первых, не будет проблемы 2000 года, о которой так много сейчас говорят, а во-вторых, в данный момент наша сеть довольно интенсивно растет, что заставляет делать изменения по нескольку раз на дню. Простое увеличение номера решает все эти проблемы. Важность серийного номера определяется тем, что когда вторичный (secondary) сервер обращается к первичному (primary) серверу для обновления информации о зоне, то он сравнивает серийный номер из своего кэша с серийным номером из базы данных первичного сервера. Если серийный номер из primary сервер больше, то secondary сервер обращается к primary и копирует описание всей зоны целиком, если нет, то он не вносит изменений в свою базу данных. Таким образом, когда производятся изменения в базе данных primary сервера, то значение атрибута serial в поле данных записи SOA для зоны, описание которой было изменено, должно быть увеличено. Неизменение номера - это типичная ошибка, на которой автор не раз себя ловил.
Атрибут refresh определяет интервал времени, после которого secondary сервер обязан обратиться к primary серверу с запросом на верификацию своего описания зоны. Как уже ранее было сказано, при этом проверяется серийный номер описания зоны. Описание зоны загружается secondary сервером каждый раз, когда он стартует или перегружается. Однако, при стабильной работе может пройти достаточно большой интервал времени, пока эти события не произойдут в действительности. Кроме того, большинство систем, которые поддерживают сервис доменных имен, работают круглосуточно. Следовательно, необходим механизм синхронизации баз данных primary и secondary серверов. Поле refresh задает интервал, после которого эта синхронизация автоматически выполняется. Длительность интервала указывается в секундах. В поле refresh можно указать до восьми цифр. Указание маленькой цифры приведет к неоправданной загрузке сети, ведь в большинстве случае описание зон довольно стабильно, но в ряде случаев, когда зона только организуется, можно указать и небольшой интервал. Наиболее типичным является синхронизация состояния описания зон один (86400) - два (43200) раза в сутки.
Атрибут retry начинает играть роль тогда, когда primary сервер по какой-либо причине не способен удовлетворить запрос secondary сервера за время определенное атрибутом refresh. А точнее, в момент наступления времени синхронизации описания зоны, primary сервер не отвечает на запросы secondary сервера. Атрибут retry определяет интервал времени после которого secondary сервер должен повторить попытку синхронизовать описание зоны с primary сервером. Значение этого атрибута также может состоять максимум из восьми цифр. При установке этого значения во внимание следует принимать несколько факторов. Во-первых, если primary сервер не отвечает, то, скорее всего произошло что-то серьезное (отделочники вырезали часть сети, т.к. мешала красить стены, экскаватор перекопал магистраль или отключили питание в сети). Такая причина не может быть быстро устранена, поэтому установка слишком малого времени опроса просто зря нагружает сеть. Во-вторых, если на primary сервер прописано много зон, и он обслуживает большое количество запросов, то он может просто не успеть ответить на запрос, а очень частые запросы от secondary сервера просто «подливают масло в огонь», ухудшая и так медленную работу сервера. Обычно значение этого атрибута устанавливают равным одному часу (3600).
Атрибут expire определяет интервал времени, после которого secondary должен прекратить обслуживание запросов к зоне, если он не смог втечение этого времени верифицировать описание зоны, используя информацию с primary сервера. Обычно это интервал делают достаточно большим, скажем полтора месяца (3888000). Если сделать маленький интервал, то какой смысл в secondary сервере, если он скоропостижно скончается после отключения primary сервера. Втечение всего этого времени secondary сервер будет пытаться установить контакт c primary сервером и обслуживать запросы к зоне. Правда все эти соображения хороши для случая, когда просто отключится или ломается машина, на которой стоит primary сервер. Если же отключится вся сеть, которая описана в зоне, а для большинства организаций так оно и есть, то secondary сервер становится подобным космическому аппарату «Пионер», который путешествует во Вселенной, давно потеряв всякую связь с Землей.
Последний атрибут из поля данных записи SOA - minimum. Он определяет время хранения записи описания ресурса в кэше удаленной машины, т.е. значение поля ttl по умолчанию для всех записей описания зоны. Именно по этой причине поле ttl в записи SOA остается пустым. Данное поле влияет на то, как часто удаленные серверы будут обращаться к серверу описания зоны за информацией. Хорошим тоном считается установка значения в этом поле не меньше, чем значения в поле expire. Иногда указывают вообще максимально возможное значение - 99999999. Маленькое значение будет приводить к непроизводительной загрузке сети - ведь соответствия межу IP-адресами меняются очень редко.
Обратите внимание на то, что все атрибуты записи SOA определяют порядок взаимодействия primary сервера и secondary серверов. Исключение составляет только атрибут minimum. В данном случае речь идет о кэшировании адресов не сервером, а системой resolver. Однако, в большинстве случаев эта разница не проявляется. Дело в том, что в качестве resolver на локальной вычислительной установке выступают функции из стандартной библиотеки, которые направляют запросы к локальному серверу доменных имен и сами не осуществляют кэширования соответствий между именами и IP-адресами. В этом случае кэширование осуществляется локальным сервером доменных имен. В том случае, когда на машине запускается свой кэширующий сервер, который не описывает никакой зоны, а используется только для обслуживания запросов к сервису доменных имен, именно он и является той частью resolver, которая кэширует соответствия.
Таким образом, когда речь идет об атрибуте minimum, то чаще всего его описывают в контексте программы named, которая может использоваться не только как primary или secondary сервер, но и как кэширующий сервер. В этом случае поле ttl записи описания ресурса и атрибут minimum задают время хранения записи описания ресурса в кэше.
Приведем пример записи типа SOA:
@ IN SOA vega-gw.vega.ru paul.kiae.su (
101 ; serial number
86400 ; refresh within a day
3600 ; retry every hour
3888000 ; expire after 45 days
99999999 ) ; default ttl is set to maximum value
В данном примере имя зоны берется из записи primary файла named.boot, поэтому в поле имени зоны указан символ «@». В качестве сервера для зоны используется машина с именем vega-gw.vega.ru. Почтовый адрес ответственного за зону - paul@kiae.su. Открывающаяся скобка говорит о том, что описание записи SOA будет продолжено на следующих строках. Каждая из последующих строк описывает один атрибут из поля данных записи SOA. При этом обратите внимание на то, что символ «;» маскирует весь остаток строки для интерпретации программой named, т.е. комментарий начинается с символа «;» и заканчивается символом перехода на новую строку. Атрибут serial определяет данную 101-ю версию описания зоны, атрибут refresh устанавливает периодичность опроса primary сервера secondary сервером как один раз в сутки, в случае неудачи secondary сервер начинает опрашивать primary сервер каждый час и, если восстановить взаимодействие не удается, то через 45 дней secondary сервер перестает обслуживать запросы к данной зоне. Информация о соответствии доменных имен IP-адресам должна храниться в кэше resolver или удаленного сервера максимально возможное время.
3.1.6.3. Запись «Name Server»
Запись NS используется для обозначения сервера, который поддерживает описание зоны. Эта запись позволяет делегировать поддомены, поддерживая тем самым иерархию доменов системы доменных имен Internet. Для того, чтобы домен был виден в сети в зоне описания домена старшего уровня должна быть указана запись типа NS для этого поддомена. Формат записи NS можно записать в виде:
[domain][ttl] IN NS [server]
В поле domain указывается имя домена, для которого сервер, указанный последним аргументом записи NS поддерживает описание зоны. Значение поля ttl обычно оставляют пустым, тем самым, заставляя named устанавливать значение по умолчанию (поле minimum из записи SOA для данной зоны). При указании имени сервера следует иметь в виду следующие обстоятельства: если в качестве сервера указывается сервер из текущей зоны, то можно обойтись только именем машины, не указывая полное доменное имя этого компьютера, т.к. имя может быть расширено именем домена, но это скорее исключение, чем правило. В записях NS указываются как primary, так и secondary серверы. Последние же, скорее всего, принадлежат другим зонам, и для них следует указывать полное доменное имя сервера с указанием имени машины и имени зоны. Например, для сервера из домена polyn.kiae.su c именем ns следует писать полностью ns.polyn.kiae.su. Для того, чтобы придерживаться какого-то единого стиля и во избежание ошибок рекомендуется писать всегда полное имя сервера.
Приведем пример записи описывающей делегирование поддомена:
$ORIGIN vega.ru.
zone1 IN NS ns.zone1.vega.ru.
В данном примере в качестве первой строки используется команда $ORIGIN, которая определяет имя текущей зоны. Об этой команде поговорим несколько позже. Здесь она введена только для того, чтобы определить текущую зону. В поле имени зоны указано имя zone1 без точки на конце. В данном контексте это означает делегирование зоны в домене vega.ru, полное имя которой будет zone1.vega.ru. В качестве имени сервера, который управляет делегированной зоной, указано имя ns.zone.vega.ru, т.е. полное имя машины в делегированном домене. В принципе, в данном случае можно было бы написать и по-другому:
$ORIGIN vega.ru.
zone1 IN NS ns.zone1
т.к. имя принадлежит текущему домену и может быть расширено его именем.
3.1.6.4. Адресная запись «Address»
Основное назначение адресной записи - установить соответствие между доменным именем машины и IP-адресом. В принципе для разных имен можно установить один и тот же адрес. Адресная запись - это основа файла описания «прямой» зоны. Запись имеет следующий формат:
[host][ttl] IN A [address]
Поле host определяет доменное имя машины. Чаще всего это имя указывается относительно имени текущей зоны, поэтому на конце имени не проставляется символ «.». Если же надо описать машину из другой зоны, то следует указать ее полное доменное имя и не забыть в конце этого имени символ «.». Например, «quest.polyn.kiae.su.», указанное в поле host ссылается на машину с именем quest.polyn.kiae.su. Поле ttl обычно оставляют пустым, а в поле address указывают IP-адрес машины. В этом адресе точку на конце ставить не надо. При делегировании доменов и в самом начале описания зоны возникает проблема описания серверов, поддерживающих базы данных описания зоны и поддоменов. Ведь реально при маршрутизации пакетов по сети нужно знать только IP-адреса, а их-то как раз и не хватает для обращения к серверам поддоменов и к серверу зоны, если он расположен в той же зоне. Для решения этой проблемы используются «приклеенные» (буквально «glue») записи типа «А». При этом вообще-то нет разницы, что будет указано раньше использование доменного имени или определение соответствия этого имени IP-адресу.
Приведем пример записи типа A и использование «приклеенных» адресных записей. Во-первых, рассмотрим простую запись типа A:
$ORIGIN vega.ru.
vega-gw IN A 194.226.43.1
В данном случае в зоне vega.ru определяется доменное имя для машины с IP-адресом 194.226.43.1. Для каждой машины зоны будет указана такая же запись.
Теперь рассмотрим возможность назначения «приклеенной» записи для сервера зоны для обращений по имени зоны, а не конкретной машины, что бывает полезно при настройке электронной почты.
$ORIGIN vega.ru.
@ IN SOA vega-gw.vega.ru paul.kiae.su (
101 ; serial number
86400 ; refresh within a day
3600 ; retry every hour
3888000 ; expire after 45 days
99999999 ) ; default ttl is set to maximum value
IN NS vega-gw.vega.ru.
IN A 194.226.43.1
;
vega-gw IN A 194.226.43.1
В данном примере при назначении сервера зоны в записи NS IP-адрес этого сервера еще не определен, но это и не суть важно, главное, чтобы он был определен далее в одной из адресных записей определения. Кроме этого, для обслуживания типа:
/usr/paul>mail paul@vega.ru
«приклеена» еще одна адресная запись, которая назначает текущему домену IP-адрес 194.226.43.1. Формально эта запись определяет адрес для, так называемых, запросов по неполному имени. В данном случае для всех запросов, которые используют имя зоны, определен адрес шлюза, на котором установлено обслуживание всех сервисов, например, http://vega.ru/ или gopher://vega.ru/. Обычно такой подход используют в маленьких сетях для упрощения работы с сервисами этих сетей [Tom Yager].
Другим примером «приклеенной» записи может служить делегирование зон внутри домена. Пусть мы создаем два поддомена zone1 и zone2, серверы которых также расположены в этих же поддоменах:
$ORIGIN vega.ru.
@ IN SOA vega-gw.vega.ru paul.kiae.su (
101 ; serial number
86400 ; refresh within a day
3600 ; retry every hour
3888000 ; expire after 45 days
99999999 ) ; default ttl is set to maximum value
IN NS vega-gw.vega.ru.
IN A 194.226.43.1
;
vega-gw IN A 194.226.43.1
.........
; Glue address records.
zone1-gw.zone1 IN A 194.226.43.2
zone2-gw.zone2 IN A 194.226.43.3
; Subdomain delegation.
zone1 IN NS zone1-gw.zone1.vega.ru.
zone2 IN NS zone2-gw.zone2.vega.ru.
Данный пример - это расширение предыдущего примера. Сначала мы определили IP-адреса серверов поддоменов в рамках текущего домена, а потом определили их в качестве серверов соответствующих зон нашего домена. При разбиении домена на зоны не следует увлекаться. Запоминать и набивать длинные имена также трудно, как и числа IP-адреса.
3.1.6.5. Запись Mail eXchanger
Данная запись служит для определения адреса почтового сервера. Запись MX может быть определена как для всей зоны, так и для отдельно взятой машины. Запись MX имеет следующий формат:
[name] [ttl] IN MX [prference] [host]
Поле name определяет имя машины или домена, на который может отправляться почта. Это может быть как полностью определенное имя, так и частичное имя машины. Поле ttl обычно оставляют пустым. В поле preference указывается приоритет почтового сервера, указанного последним аргументом в поле данных MX-записи. Запись MX используется следующим образом:
· почтовый агент, например, программа sendmail, который умеет работать со службой доменных имен, получает от сервера доменных имен в ответ на свой запрос список MX-записей данного домена;
· в нем он ищет записи, которые позволяют переслать почту на машину, которая содержит почтовый ящик адресата, или на машину, которая знает, как переслать почту по данному почтовому адресу;
· используя эту информацию, sendmail пересылает почту на найденную машину. При передаче, в данном случае, обычно используется протокол SMTP (Simple Mail Transfer Protocol).
Типичными примерами пересылки почты является работа с почтой UUCP и BITNET. Пересылка касается, как правило, уходящей из домена почты, которая не является проблемой данного домена. В файле настройки sendmail прописывается имя соответствующего шлюза и на этом все заканчивается. Но для российских сетей здесь возможны свои проблемы, которые связаны с переходом от старой почты UUCP, которая активно внедрялась сетью Relcom к системе работы по тому же протоколу, но уже через свой собственный домен. Однако более подробно на этой проблеме мы остановимся в разделе описания настроек программы sendmail.
Приведем пример использования записей MX:
$ORIGIN vega.ru.
@ IN SOA vega-gw.vega.ru paul.kiae.su (
101 ; serial number
86400 ; refresh within a day
3600 ; retry every hour
3888000 ; expire after 45 days
99999999 ) ; default ttl is set to maximum value
IN NS vega-gw.vega.ru.
IN NS ns.relarn.ru.
IN NS polyn.net.kiae.su.
IN A 194.226.43.1
IN MX 10 vega-gw.vega.ru.
IN MX 20 ns.relarn.ru.
IN MX 30 relay.relarn.ru.
*.vega.ru. IN MX 0 vega-gw.vega.ru.
;
vega-gw IN A 194.226.43.1
IN MX 0 vega-gw
IN MX 10 ns.relarn.ru.
IN MX 20 relay.relarn.ru.
В данном примере мы определили несколько записей типа MX для типов почтовой рассылки.
Записи в описании зоны, сразу после A-записи, следующей за записью SOA, определяют пути поступления почты в данный домен. Самый высокий приоритет здесь имеет прямая отправка почты на шлюз vega-gw.vega.ru. Если отправить почту на эту машину не удастся, то почтовый агент должен попробовать путь через почтовый сервер ns.relarn.ru[9]. Если и этот путь окажется невозможным, то почту можно попытаться отправить на пересыльный пункт relay.relarn.ru[10]. Такой порядок опроса почтовых серверов определяется полем preference - чем меньше значение поля, тем выше приоритет сервера в записи MX.
В нашем домене, который мы используем в качестве примера, большинство почтовых ящиков пользователей расположено на машине vega-gw.vega.ru. Для этой машины также указаны несколько записей MX. Наибольший приоритет среди них имеет запись с именем почтового сервера vega-gw. Обратите внимание на то, что данное имя не оканчивается точкой. Это значит, что оно расширяется именем текущей зоны. Все же другие имена серверов - это полностью определенные доменные имена (fully-qualified).
Кроме описанных MX-записей в нашем примере есть еще одна, которая определяет почтовый шлюз для нашего домена - запись с именем «*.vega.ru.». Данная запись введена для того, чтобы определить шлюз по умолчанию для любой машины из нашего домена, если для нее не определен шлюз в ее собственных MX-записях. Главным в этой записи является использование символа «*», который обозначает все возможные имена машин и поддоменов данного домена.
3.1.6.6. Запись назначения синонима каноническому имени «Canonical Name»
Запись CNAME определяет синонимы для реального доменного имени машины, которое определено в записи типа A. Имя в записи типа A называют каноническим именем машины. Формат записи CNAME можно определить следующим образом:
[nickname] [ttl] IN CNAME [host]
Поле nickname определяет синоним для канонического имени, которое задается в поле host.
Запись CNAME чаще всего используется для определения информационных сервисов Internet, которые установлены на машине. Следующий пример определяет синонимы, для компьютера, на котором установлены серверы протоколов http и gopher:
$ORIGIN polyn.net.kiae.su.
olga IN A 144.206.192.2
www IN CNAME olga.polyn.kiae.su.
gopher IN CNAME olga.polyn.kiae.su.
Как и в предыдущих примерах команда $ORIGIN введена только для определения текущей зоны. Две записи типа CNAME позволяют организовать доступ к серверам, используя имена распределенных информационных систем Internet, в рамках технологий которых работают данные серверы. Именно такие синонимы и используются при обращении к таким системам, как Yahoo (www.yahoo.com) или Altavista (www.altavista.digital.com). Правда при обращении к серверу протокола http, который является базовым для системы World Wide Web, изменение имени машины, с которой осуществляют обслуживание, может быть вызвано многими причинами: перенаправлением запроса на другой сервер, использование виртуального сервера и т.п. (см. раздел «Администрирование баз данных World Wide Web»).
При использовании записей типа CNAME следует учитывать, что запись этого типа следует использовать очень аккуратно. Некоторые администраторы рекомендуют вообще от нее отказаться и если нужно еще одно имя, то лучше вообще указать еще одну A-запись для того же самого IP-адреса. В частности запись типа MX может присоединяться только к адресной записи. Если быть более точным, то просто не все почтовые агенты способны обрабатывать записи типа CNAME, т.к. это требует дополнительного обращения к серверу доменных имен. Приведем пример правильного и неправильного использования записи CNAME:
$ORIGIN polyn.net.kiae.su.
olga IN A 144.206.192.2
IN MX 0 olga
IN MX 10 ns.polyn.kiae.su.
www IN CNAME olga.polyn.kiae.su.
gopher IN CNAME olga.polyn.kiae.su.
В данном случае записи типа CNAME указаны правильно, т.к. не мешают переадресации почты на машину olga.polyn.kiae.su. Но если их поменять местами с записями типа MX, то, скорее всего почта работать не будет:
$ORIGIN polyn.net.kiae.su.
olga IN A 144.206.192.2
www IN CNAME olga.polyn.kiae.su.
gopher IN CNAME olga.polyn.kiae.su.
IN MX 0 olga
IN MX 10 ns.polyn.kiae.su.
Это будет происходить по следующей причине. Почтовый агент для получения адреса машины абонента почтового сервера в ответ на свой запрос получит запись из базы данных сервера с именем этой машины. Если бы это была запись типа A, то по ней почтовый агент определяет IP-адрес машины-получателя или машины шлюза. Получив этот адрес агент организует взаимодействие по протоколу SMTP и отправляет почтовое сообщение получателю или в очередь почтового агента шлюза. Если же он получил в результате обращения к серверу доменных имен запись типа CNAME, то никакого IP-адреса в ней нет, а, следовательно, и организовать SMTP-соединение нельзя.
Сами серверы доменных имен для определения IP-адреса используют несколько обращений. Когда получен ответ на запрос, сервер анализирует тип полученной записи, если это запись типа A, то IP-адрес передается системе resolver, если же это запись типа CNAME, то сервер снова запрашивает удаленный сервер на предмет получения новой записи, но уже по новому имени, которое он берет из поля host записи типа CNAME. Если в качестве resolver используется программа named, которая работает как resolver (команда slave в файле named.boot), то в этом случае resolver умеет обрабатывать записи типа CNAME, но в большинстве случаев, как в уже рассмотренном нами случае с электронной почтой, многие системы, которые работают в качестве «мудрых» resolver’ов не умеют анализировать записи типа CNAME, что и заставляет использовать вместо них записи типа A. Кроме того, последние имеют еще и то преимущество, что сокращается число запросов к серверу доменных имен, т.к. IP-адрес запрашивающая сторона получает с первой попытки.
В качестве еще одного примера использования записей типа CNAME приведем трассу получения IP-адреса для доменного имени ftp.netscape.com:
ftp.netscape.com. IN CNAME anonftp6.netscape.com.
anonftp6.netscape.com. IN CNAME ftp22.netscape.com.
ftp22.netscape.com. IN A 204.152.166.45
Как видно из примера при поиске IP-адреса для ftp.netscape.com локальный сервер доменных имен дважды получает в ответ на свой запрос запись типа CNAME.
3.1.6.7. Записи типа «Pointer»
До сих пор мы описывали записи, которые используются главным образом в файле обслуживающем «прямую» зону, т.е. запросы на получение IP-адреса по доменному имени. Но существует, как мы выяснили ранее, и запросы другого типа, когда необходимо по IP-адресу получить доменное имя. Для реализации ответов на эти запросы сервер ведет описание «обратной» зоны, база данных которой состоит, главным образом, из записей типа «Pointer» или P-записей. Формат записи имеет следующий вид:
[name][ttl] IN PTR [host]
Поле name задает номер. Это не реальный IP-адрес машины, а имя в специальном домене in-addr.arpa или в одной из его зон. Существует специальный формат записи имен этого домена. Так, например, машина vega.-gw.vega.ru, которая имеет адрес 194.226.43.1, должна быть описана в домене in-addr.arpa как 1.43.226.194.in-addr.arpa, т.е. адрес записывается в обратном порядке. Так как речь идет о доменной адресации, то разбиение на сети (подсети в данном случае) значения не имеет. Имена обрабатываются точно также, как и обычные доменные имена. Это значит, что систему доменных имен машин этого домена можно представить в виде:
|
|
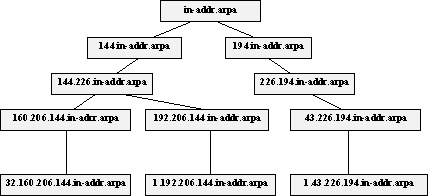
Рис. 3.12. Пример структуры части домена in-addr.arpa
Как видно из рисунка, в данном случае не играет ни какой роли тип сети или разбиение на подсети. Согласно правилам описания доменов и зон в этих доменах, разделителем в имени, которое определяет подчиненное значение зоны в домене, является только символ «.». Согласно этому правилу подсети сети класса B (144.206.0.0) и сеть класса С (194.226.43.0) находятся на одном уровне иерархии в системе домена in-addr.arpa. Поэтому не надо комплексовать перед записями типа:
$ORIGIN 194.in-addr.arpa.
1.43.226 IN PTR vega-gw.vega.ru.
Однако следует признать, что соответствие «обратных» зон сетям - это общая практика описания «обратных» зон. Ведь здесь точно также надо делегировать зоны из «обратного» домена. А делается это, как правило, на основе разбиения сети на подсети или сети.
В качестве примера для нашей учебной зоны в файле named.boot определена «обратная» зона 43.226.194.in-addr.arpa:
@ IN SOA vega-gw.vega.ru paul.kiae.su (
101 ; serial number
86400 ; refresh within a day
3600 ; retry every hour
3888000 ; expire after 45 days
99999999 ) ; default ttl is set to maximum value
IN NS vega-gw.vega.ru.
IN NS ns.relarn.ru.
;
1 IN PTR vega-gw.vega.ru.
4 IN PTR dos1.vega.ru.
5 IN PTR dos2.vega.ru
2 IN PTR zone1-gw.zone1.vega.ru.
3 IN PTR zone2-gw.zone2.vega.ru.
Из этого примера видно, что для «обратной» зоны указаны те же записи описания зоны, что и для «прямой». Кроме того, «обратную» зону вовсе не обязательно разбивать в соответствии с разделением «прямой» зоны. С точки зрения домена in-addr.apra все машины принадлежат одной зоне - 43.226.194.in-addr.arpa.
Другое дело машина с IP-адресом 127.0.0.1. С точки зрения домена in-addr.arpa, она принадлежит другой ветке иерархии, отличной от той, которой принадлежат все остальные машины. Поэтому для домена 127.in-addr.arpa на любой машине есть отдельный файл «обратной» зоны, хотя машина localhost, которой соответствует этот IP-адрес, обычно описывается в «прямой» зоне домена вместе с другими машинами.
3.1.6.8. Запись типа HINFO
Описание записи этого типа приводится здесь из соображений полноты представления стандартных записей описания зоны. В записи типа HINFO указывается тип компьютера (hardware) и тип операционной системы, установленной на этом компьютере. Запись имеет следующий формат:
[host][ttl] IN HINFO [hardware] [software]
Поле host определяет имя машины. Поле ttl обычно оставляют пустым. Поле hardware определяет тип аппаратуры, например, SUN-3/60 или IBM-PC/AT. Значение поля определяется согласно RFC «Assigned Numbers». Однако, т.к. развитие средств вычислительной техники и программного обеспечения идет очень быстро, то многие администраторы пишут произвольные названия как hard- так и software. Если в названии встречается пробел, то название должно записываться в кавычках. Отказ от использования этого типа записей вызван также и соображениями безопасности.
3.1.6.9. Запись определения информационных сервисов «Well Known Services»
Данная запись определяет наличие на машине так называемых «Well Known Servisces» (буквально – «хорошо известный сервис»). В данном случае речь идет о прикладных программах, которые обслуживают запросы по портам TCP и UDP до 1024 порта. Наиболее простой способ выяснить, какие сервисы реально работают на машине с операционной системой UNIX - это обратиться к файлу /etc/services. Для каждой машины можно указать только две записи типа WKS: одну для TCP и одну для UDP. Формат записи выглядит следующим образом:
[host][ttl] IN WKS [address] [protocol] [services]
Поле host определяет имя машины. Поле address - IP-адрес машины. В поле protocol указывается протокол - TCP или UDP. В поле services перечисляются информационные сервисы, которые установлены на данной машине. Так как сервисов может быть много и потребуется продолжение записи на следующих строках, список сервисов можно записать в круглых скобках. При указании сервисов можно ссылаться только на те, которые описаны в файле /etc/services.
Запись типа WKS используется редко. Во-первых, все сервисы управляются не сервером доменных имен, а поэтому лишний раз их указывать в описании зоны равносильно фразе «масло масленое», во-вторых, мало какие программы умеют работать с этим типом записей и, в-третьих, это дополнительная информация для возможных “взломщиков”, т.к. именно сервисы являются инструментом несанкционированного доступа.
3.1.6.10. Команды описания зоны
Кроме записей описания ресурсов, в файлах описания зоны используют еще две команды $INCLUDE и $ORIGIN. Первая команда используется для того, чтобы в файл описания зоны можно было включить содержание другого файла. Так рекомендуется поступать при описании больших зон, разбивая их на небольшие фрагменты. При этом имя включаемого файла должно быть описано либо полностью от корня файловой системы, либо оно будет привязано к директории, указанной в файле named.boot.
$INCLUDE my_zone.dsc
В этом случае используется файл /etc/namedb/my_zone.dsc, т.к. обычно команда directory определяет именно эту директорию для хранения файлов базы данных named.
$INCLUDE /etc/my_zone
В данном случае указан полный путь, и именно он будет использоваться при доступе к файлу.
Команда $ORIGIN служит для определения имени текущего домена. В отличие от предыдущей команды, которая практически не используется, по крайней мере, российскими провайдерами, $ORIGIN используется и весьма интенсивно. Типичным примером использования $ORIGIN является объявление зоны для «приклеенной» записи типа A:
@ IN SOA ns.vega.ru. ......
IN NS ns.vega.ru.
IN NS ns.relarn.ru.
$ORIGIN relarn.ru.
ns IN A 194.226.130.1
$ORIGIN vega.ru.
ns IN A 194.226.43.1
; The rest of zone description.
.......
В этом примере мы вынуждены были применить команду $ORIGIN дважды. Первый раз при определении «приклеенной» записи для ns.relarn.ru, а второй раз для того, чтобы вернуться к описанию домена vega.ru. Как будет показано в примерах описания файлов, такая практика - обычное дело при использовании named.
3.1.6.11. Файлы описания зоны
Собственно записи описания ресурсов не существуют сами по себе, они составляют файлы описания зоны. Эти файлы размещаются в директории, указанной в команде directory файла настройки программы named - named.boot.
Все эти файлы можно разделить на три категории: файлы описания «прямой» зоны, файлы описания «обратной» зоны и файл описания начальной загрузки базы данных для named.
Обычно, в описании зоны имеется один файл описания «прямой» зоны и не менее двух файлов описания «обратных» зон. Наличие не менее двух файлов объясняется тем, что существует «обратная» зона для адреса 127.0.0.1 и «обратная» зона для каждой из сетей или подсетей выделенных для данного домена.
Файл начальной загрузки - cache-файл служит для того, чтобы программа named смогла начать общаться с другими серверами сервиса доменных имен, установленными в сети. В этом файле обычно указывают адреса root-серверов.
Для знакомства с содержанием этих файлов проще всего обратиться к примерам организации сервиса доменных имен для различного сорта локальных сетей, подключенных к Internet.
3.1.7. Примеры настроек программы named и описания зон
В данном разделе мы рассмотрим наиболее типичные, на мой взгляд, примеры построения сервиса доменных имен:
· описание простой «прямой» и «обратной» зон в домене ru;
· описание «прямой» и «обратной» зон для поддомена, определенного на двух подсетях;
· делегирование поддоменов внутри домена.
Этот перечень можно было бы, и расширить, но такое расширение будет просто комбинацией приведенных выше случаев. Более сложные случаи встречаются в практике администраторов больших сетей, и для них можно только порекомендовать обращаться за помощью к другим администраторам или разработчикам программ-серверов.
С первой ситуацией сталкивается любая организация, которая намеривается получить свой собственный домен в домене ru. О том, как его получить рассказывалось в разделе 3.1.3. В настоящее время практически нет сетей класса B, поэтому организации получают сети класса C на 254 машины и на основе этих сетей организовывают свой домен. В самом начале такой домен, как правило, состоит из одной единственной зоны. В качестве главной машины в этом домене выступает один единственный компьютер с операционной системой Unix или Windows NT. Все остальные варианты рассматривать не будем в силу их неготовности для полноценной работы с сервисом доменных имен Internet. Этот компьютер одновременно является и шлюзом между локальной сетью и сетью Internet-провайдера.
Второй случай касается ситуации, когда сеть учреждения приходится разбивать на подсети. При этом на нескольких подсетях может быть определена одна и та же зона общего домена организации. Такая ситуация часто возникает при постоянных перемещениях подразделений из одного помещения в другое или даже из одного здания в другое. При этом часто подразделения либо съезжаются, либо разъезжаются. Случай типичный для растущей или стареющей организации.
Третий случай обусловлен развитием и усложнением сети или структуры организации, которую данная сеть обслуживает. Когда становится трудно управлять из одного места всеми машинами в домене, права управления частями домена делегируют туда, где изменения наиболее часты. В этом случае администратор домена снимает с себя часть обязательств по управлению доменом и передает их администраторам поддоменов. Для больших организаций - это типичный способ обеспечения сервиса доменных имен. Можно, конечно, спорить о достоинствах или недостатках такого делегирования прав, но в современных условиях это единственная возможность управлять большими разнородными сетями.
3.1.7.1. Небольшой поддомен в домене ru
В данном случае организация получила домен в домене ru и зарегистрировала его в РосНИИРОС. Primary сервер доменных имен установлен на шлюзе 194.226.43.1. Это единственная машина в сети, которая работает под управлением Unix. Все остальные машины - это персональные компьютеры сотрудников. В общем виде схему такого домена можно представить в виде рисунка 3.13:
|
|
Рис. 3.13. Структура простой локальной сети
Домен, который зарегистрировала данная организация, пусть будет называться vega.ru. Так как это домен второго уровня, то он должен иметь как минимум два сервера доменных имен: primary и secondary. Основной сервер, primary, установлен на машине-шлюзе, на размещение вторичного получено разрешение от администратора сервера ns.rekarn.ru, который расположен в другой сети, имеющей свой собственный выход в Internet.
Программа named, установленная на машине шлюзе будет иметь следующую конфигурацию, которая задается файлом named.boot:
;
; Zone vega.ru data base files.
;
directory /etc/namedb
primary vega.ru vega.ru
primary 127.in-addr.arpa localhost
primary 43.226.194.in-addr.arpa vega.rev
forwarders 144.206.136.1 144.206.130.137
cаche . named.root
В этом файле определено, что директория расположения описания файлов зоны vega.ru - /etc/namedb. Это стандартная директория для операционной системы FreeBSD. Файла описания «прямой» зоны домена vega.ru - файл vega.ru будет размещен в этой директории (/etc/namedb/vega.ru). Кроме «прямой» зоны описаны еще две «обратных» зоны 127.in-adrr.arpa и 43.226.194.in-addr.arpa. Первая определяет обратное соответствие между адресом 127.0.0.1 и именем localhost, а вторая множество обратных соответствий для сети 194.226.43.0. Последним указан файл начальной загрузки cache. Символ «.» в качестве первого аргумента указывает на описание домена root.
Кроме этого команда forwarders указывает IP-адреса серверов доменных имен, к которым следует обращаться в случае невозможности самостоятельно получить адрес. Это сделано для того, чтобы в начальный период функционирования сервера он мог отвечать на запросы клиентов из данной зоны, хотя сам он еще, и не зарегистрирован в корневом сервере домена ru.
В принципе, можно было бы просто указать данные сервера в настройках resolver для машин данного домена, но зато потом везде нужно было бы их снова менять. Использование forwarders позволяет после регистрации домена и размещения серверов не перестраивать настройки всех компьютеров в домене. Кроме того, named сразу начинает работать как интеллектуальный кэширующий сервер, что при частом обращении к одним и тем же именам позволяет быстро получать IP-адреса или имена машин.
Файл описания «прямой» зоны для домена vega.ru будет выглядеть следующим образом (/etc/namedb/vega.ru):
@ IN SOA vega-gw.vega.ru paul.vega.ru (
101 ;serial number
86400 ;refresh
3600 ;retry
3888000 ;expire
99999999 ;minimum
)
; Name server
IN NS vega-gw.vega.ru.
IN NS ns.relarn.ru.
IN NS polyn.net.kiae.su.
IN A 194.226.43.1
IN MX 0 vega-gw.vega.ru.
IN MX 10 ns.relarn.ru.
;
localhost IN A 127.0.0.1
;
vega-gw IN A 194.226.43.1
IN MX 0 vega-gw
IN MX 10 ns.relarn.ru.
www IN CNAME vega-gw
ftp IN CNAME vega-gw
gopher IN CNAME vega-gw
;
dos1 IN A 194.226.43.2
dos2 IN A 194.226.43.3
; The rest of net should be presented below.
Запись SOA берет имя зоны из записи primary файла named.boot (символ «@»). В качестве машины, на которой установлен сервер, указана машина vega-gw.vega.ru, а в качестве администратора - paul@kiae.su. Остальные поля установлены в соответствии с описанием записи SOA.
Обратите внимание на следующее обстоятельство: имя текущей зоны будет взято из команды primary файла named.boot и использоваться для описания зоны, только в том случае если в записи SOA будет указан символ коммерческого «@». Например, в следующем примере могут возникнуть проблемы с описанием зоны:
IN SOA vega-gw.vega.ru paul.vega.ru (
101 ;serial number
86400 ;refresh
3600 ;retry
3888000 ;expire
99999999 ;minimum
)
; Name server
IN NS vega-gw.vega.ru.
IN NS ns.relarn.ru.
IN NS polyn.net.kiae.su.
IN A 194.226.43.1
IN MX 0 vega-gw.vega.ru.
IN MX 10 ns.relarn.ru.
Ни NS-записи, ни A-запись, ни MX-записи не привязаны к конкретному домену, и следовательно не используются named.
Две NS-записи определяют три машины в качестве сервера доменных имен для данной зоны: vega-gw.vega.ru, ns.relarn.ru и polyn.net.kiae.su. Первая запись типа A определяет адрес всего домена для обслуживания неполных запросов. Следующие две записи MX определяют правила пересылки почты на домен по адресам типа user@vega.ru.
За описанием зоны в нашем файле следует описание «петли», т.е. имени для адреса 127.0.0.1. В FAQ по сервису доменных имен можно найти и другие решения, но в большинстве случаев, обычно, рекомендуется определять имя localhost как localhost.domain.name, или в нашем случае - localhost.vega.ru.
Первой в домене описана машина-шлюз. На ней установлены сервисы World Wide Web, FTP и Gopher. Для каждого из них определены имена, которые должны облегчить запоминание доменного имени сервера. После записей CNAME идут записи описания других машин зоны. Так как это обычные рабочие места под управлением MS-DOS и Widows, то никаких дополнительных записей для их описания не требуется.
Как утверждается во всех руководствах по DNS, описание обратных зон для домена не является обязательным, но крайне желательно. Для нашего простого домена в файле named.boot описаны две обратные зоны: 127.in-addr.arpa и 43.226.194.in-addr.arpa.
Зона 127.in-addr.arpa описывает обратное соответствие межу адресом 127.0.0.1 и именем localhost.vega.ru. Описание зоны будет располагаться в файле /etc/namedb/localhost:
@ IN SOA vega-gw.vega.ru paul.vega.ru (
101 ;serial number
86400 ;refresh
3600 ;retry
3888000 ;expire
99999999 ;minimum
)
; Localhost declaration
1 IN PTR localhost.vega.ru.
В данном случае имя зоны также, как и в предыдущем случае берется из команды primary файла named.boot:
primary 127.in-addr.arpa localhost
Согласно этому описанию символ «@» заменяется на имя 127.in-addr.arpa, которое и добавляется к цифре 1, образуя имя 1.127.in-addr.arpa. Так как сеть 127.0.0.0 - это сеть класса А, то адрес 127.1 эквивалентен адресу 127.0.0.1.
Вторая «обратная» зона описывает все остальные IP-адреса и размещается в файле /etc/namedb/vega.rev:
@ IN SOA vega-gw.vega.ru paul.vega.ru (
101 ;serial number
86400 ;refresh
3600 ;retry
3888000 ;expire
99999999 ;minimum
)
IN NS vega-gw.vega.ru.
IN NS ns.relarn.ru.
IN NS polyn.net.kiae.su.
; Reverse zone description.
1 IN PTR vega-gw.vega.ru.
2 IN PTR dos1.vega.ru.
3 IN PTR dos2.vega.ru.
; description of the other hosts should be placed below.
;
Первые две NS-записи в этом примере определяют сервера доменных имен для этой зоны. Так как «прямая» зона это зона второго уровня в домене ru, то будет логичным и для «обратной» зоны разместить дублирующий сервер в том же месте, что и дублирующий сервер для «прямой» зоны. Имя зоны берется из команды primary файла named.boot:
primary 43.226.194.in-addr.arpa vega.rev
Таким образом, к единичке, указанной в записи PTR для машины vega-gw.vega.ru будет получено «обратное» имя 1.43.226.194.in-addr.arpa.
Все имена машин в поле данных записей типа PTR должны обязательно заканчиваться точкой, иначе они будут расширены именем зоны.
И последний файл, который необходим для запуска сервера доменных имен, - это файл начальной загрузки named, определенный в команде cache файла named.boot. В нашем случае этот файл имеет полное имя - /etc/namedb/named.root. Содержание этого файла приведено в примере 5. Файл просто копируется с сервера ftp.internic.net. В ряде случаев провайдеры рекомендуют пользоваться их файлом начальной загрузки, а не стандартным.
3.1.7.2. Описание «прямой» и «обратной» зон для поддомена определенного на двух подсетях
В данном примере мы рассмотрим описание домена третьего уровня polyn.kiae.su, который определен на двух подсетях сети 144.206.0.0: 144.206.160.0 и 144.206.192.0. Если в предыдущем случае мы выделяли две «обратные» зоны из-за особой роли адреса 127.0.0.1, то в данном случае нам придется выделить «обратные» зоны на каждую из подсетей. Кроме того, этот сервер мы также будем использовать в качестве дублирующего для домена vega.ru. Файл named.boot в этом случае будет иметь вид:
;
; Zone polyn.kiae.su - data base files.
;
directory /etc/namedb
primary polyn.kiae.su polyn.kiae.su
primary 127.in-addr.arpa localhost
primary 160.206.144.in-add.arpa polyn
primary 192.206.144.in-addr.arpa quest
secondary vega.ru 194.226.43.1 vega.ru
secondary 43.226.194.in-addr.arpa 194.226.43.1 vega.rev
forwarders 144.206.136.1 144.206.130.3
cаche . named.root
Как видно из содержания этого файла все файлы описания зоны расположены в директории /etc/namedb (команда directory), описание зоны polyn.kiae.su находится в файле /etc/namedb/polyn.kiae.su, описание зоны 127.in-addr.arpa - в файле /etc/namedb/localhost, описание зоны 160.206.144.in-addr.arpa - в файле /etc/namedb/polyn, описание зоны 192.206.144.in-addr.arpa - в файле /etc/namedb/quest. Кроме этого, после запуска, данный сервер опрашивает primary сервер зоны vega.ru и копирует с него зоны vega.ru и 43.226.194.in-addr.arpa. Первую в файл /etc/namedb/vega.ru, а вторую в файл /etc/namedb/vega.rev. Перейдем теперь к описанию файлов зоны polyn.kiae.su.
;
; Zone -- polyn.kiae.su
$ORIGIN kiae.su.
polyn IN SOA polyn.net.kiae.su. paul.kiae.su. (
36 3600 300 9999999 3600 )
;
IN NS polyn.net.kiae.su.
IN NS ns.kiae.su.
IN A 144.206.160.32
IN MX 0 ns.polyn.kiae.su.
IN MX 10 relay.net.kiae.su.
$ORIGIN net.kiae.su.
polyn IN A 144.206.130.137
$ORIGIN kiae.su.
ns IN A 144.206.130.3
$ORIGIN polyn.kiae.su.
* IN MX 2 ns.polyn.kiae.su.
IN MX 10 relay.net.kiae.su.
;
ns IN A 144.206.160.32
www IN CNAME ns.polyn.kiae.su.
ftp IN CNAME ns.polyn.kiae.su.
;
kurm IN A 144.206.160.50
IN MX 0 kurm.polyn.kiae.su.
IN MX 10 polyn.net.kiae.su.
IN MX 20 relay.net.kiae.su.
driver IN A 144.206.160.51
lebedev IN A 144.206.160.41
;
georg IN A 144.206.192.5
olga IN A 144.206.192.2
IN MX 0 olga.polyn.kiae.su.
IN MX 10 polyn.net.kiae.su.
IN MX 20 relay.net.kiae.su.
nata IN A 144.206.192.3
kaverin IN A 144.206.192.6
temp IN A 144.206.192.254
; The rest of zone is placed below
........
Данный пример интересен тем, что в нем наглядно продемонстрировано использование «приклеенных» A-записей.
Начинается домен также, как и в предыдущем примере - с записи SOA. В данном случае зона описывается непосредственно командой $ORIGIN. В записи SOA указано имя домена без точки на конце, что означает, что оно будет расширено именем kiae.su. Следующие две записи определяют серверы доменных имен для данного домена. Но эти серверы расположены в другой зоне. В принципе named способен найти их IP-адреса, но из соображений большей надежности эти две записи сопровождаются «приклеенными» записями. При чем для каждого из серверов определяется домен (команда $ORIGIN) и за тем имя и IP-адрес по записи A. Наличие данных блоков записей заставляет администратора снова определить в качестве текущего домена домен polyn.kiae.su. После этого следует блок записей, для которых указан в качестве имени символ «*». Дело в том, что в данной подсети существует несколько машин, которые поддерживают почтовые ящики пользователей, поэтому записи MX при этом символе определяют порядок прохождения почтовых сообщений внутрь домена.
Первая машина домена - ns.polyn.kiae.su. Фактически, это тоже «приклеенная» запись, т.к. это имя уже встречалось раньше. Вслед за ним определено несколько записей CNAME. Исторически сложилось так, что во многих страницах World Wide Web ссылки стоят на polyn.net.kiae.su, поэтому это имя также должно быть сохранено, но в новых редакциях используется синоним www.polyn.kiae.su.
Далее в домене есть две машины, которые являются почтовыми серверами для пользователей этого домена: kurm и olga.
Файлов «обратных» зон в данном случае определено два: 160.206.144.in-addr.arpa и 192.206.144.in-addr.arpa. Сделано это из-за того, что в данном случае домен определен на двух различных подсетях сети класса B. В принципе, если бы в данный домен были выделены машины не всей подсети, а только ее частей, то для адресов 144.206.160.0, 144.206.161.0, 144.206.162.0 и т.д. до 144.206.192.0 следует описывать «обратные» зоны. При этом каждую из них надо прописывать и в домене старшего уровня, которым в данном случае является 206.144.in-addr.arpa. Рассмотрим примеры описания этих доменов:
$ORIGIN 206.144.in-addr.arpa.
160 IN SOA kiae-gw.kiae.su. root.kiae-gw.kiae.su. (
22 3600 300 9999999 3600 )
IN NS polyn.net.kiae.su.
$ORIGIN net.kiae.su.
polyn IN A 144.206.160.32
IN A 144.206.130.137
$ORIGIN 206.144.in-addr.arpa.
160 IN NS ns.kiae.su.
$ORIGIN kiae.su.
ns IN A 144.206.130.3
$ORIGIN 160.206.144.in-addr.arpa.
53 IN PTR lenya.polyn.kiae.su.
40 IN PTR apollo.polyn.kiae.su.
54 IN PTR kagan.polyn.kiae.su.
; The rest of the domain should be placed below
Данный файл начинается также, как и описание «прямой» зоны, в нем присутствуют те же «приклеенные» записи для описания серверов доменных имен. Это обстоятельство заставляет снова вводить команды $ORIGIN. Весь остаток файла состоит только из записей типа PTR.
Аналогично выглядит и файл 192.206.144.in-addr.arpa:
$ORIGIN 206.144.in-addr.arpa.
192 IN SOA kiae-gw.kiae.su. root.kiae-gw.kiae.su. (
23 3600 300 9999999 3600 )
IN NS polyn.net.kiae.su.
$ORIGIN net.kiae.su.
polyn IN A 144.206.160.32
IN A 144.206.130.137
$ORIGIN 206.144.in-addr.arpa.
192 IN NS ns.kiae.su.
$ORIGIN kiae.su.
ns IN A 144.206.130.3
$ORIGIN 192.206.144.in-addr.arpa.
6 IN PTR kaverin.polyn.kiae.su.
7 IN PTR kost.polyn.kiae.su.
1 IN PTR quest.polyn.kiae.su.
33 IN PTR vovka.polyn.kiae.su.
2 IN PTR olga.polyn.kiae.su.
34 IN PTR paul.polyn.kiae.su.
3 IN PTR nata.polyn.kiae.su.
254 IN PTR temp.polyn.kiae.su.
4 IN PTR demin.polyn.kiae.su.
5 IN PTR georg.polyn.kiae.su.
Как видно из этого примера, записи вовсе не обязательно располагать в порядке нумерации, хотя это и более удобно. Более того, в файле «прямой» зоны также не надо соблюдать порядок или группировать записи по подсетям. Однако, такое группирование облегчает администратору чтение своего файла описания зоны. Важно еще посоветовать, чаще использовать комментарии. Особенно если сеть распределена по различным зданиям, и администратору необходимо связываться с ответственными за сеть в каждом из этих зданий. Включение телефонов, имен, отчеств и фамилий этих людей в комментарии поможет легко их найти.
3.1.7.3. Делегирование поддомена внутри домена
Рассмотрим последний пример - делегирование поддомена внутри домена. Данная ситуация возникает в том случае, когда организация растет и обслуживание всего домена становится довольно трудоемкой задачей. Собственно, проблема возникает как с администрированием - слишком много машин и пользователей, так и со скоростью ответа на запросы - слишком много запросов к одному серверу, что плохо сказывается на его реактивности.
При делегировании домена определяется машина, на которой будет установлен primary сервер для нового поддомена, определяется место размещения secondary сервера и делаются соответствующие изменения в файле настроек primary сервера вышестоящего домена.
Рассмотрим такое делегирование на следующем примере: в домене kiae.su делегируется зона kiae.su. Пример описания этой зоны мы рассматривали в предыдущем примере. Поэтому в данном примере мы рассмотрим только описание зоны kiae.su и только записи, касающиеся поддомена polyn.kiae.su, т.к. полное описание домена будет занимать 23 страницы.
Пример делегирования зоны:
$ORIGIN su.
kiae IN SOA ns.kiae.su. noc.relcom.eu.net. (
3000302 28800 3600 3600000 86400 )
IN NS ns.kiae.su.
; List of NS records and MX records for domen kiae.su.
......
$ORIGIN kiae.su.
hytelnet IN A 193.125.152.10
gopher IN A 193.125.152.10
archie IN A 193.125.152.10
$ORIGIN net.kiae.su.
polyn IN A 144.206.130.137
IN A 144.206.160.32
; Other records
...
polyn IN NS polyn.net.kiae.su.
; The rest of the description of the descriptionkiae.su zone.
.....
В данном примере следует обратить внимание на следующие особенности описания. Во-первых, при описании сервисов hytelnet, goher и archie не используется записи типа CNAME. Для всех этих доменных имен указан один и тот же IP-адрес. Во-второых, при описании делегированной зоны сначала указана запись типа A для машины polyn.net.kiae.su. Это primary сервер зоны polyn.kiae.su. Для этой же зоны могут быть также указаны и secondary серверы данной зоны. Как видно из описания машины polyn.net.kiae.su, ей соответствует два IP-адреса. В данном случае это не адреса синонимы на одном и том же порте, а адреса разных интерфейсов данной машины, т.к. она является шлюзом локальной подсети.
Приведенного выше описания достаточно для того, чтобы при помощи нерекурсивных опросов серверов, resolver или сервер нашли нужный IP-адрес.
«Обратная» зона прописывается точно также. Это значит, что зона 160.206.144.in-addr.arpa должна быть прописана в зоне 206.144.in-addr.arpa. Термин «прописать» означает выполнение следующих операций: в зоне должна быть определена подзона и машина-сервер этой подзоны, т.е. указана «приклеенная» запись для этой машины, в зоне должна быть указана запись типа NS для выделяемой подзоны.
В домене vega.ru сервер зоны определялся в самой зоне vega.ru, в случае с зоной polyn.kiae.su, сервер расположен в другом домене - net.kiae.su. Однако это не мешает управлять зоной. В принципе, используя команды $ORIGIN можно опредлить зоны внутри домена и в том же файле, что и описание самого домена. Собственно в нашем примере так оно и сделано: домен net.kiae.su определен в файле описания домена kiae.su.
Теперь от примеров описания зон перейдем к средствам контроля за размещенными зонами.
3.1.8. Программа nslookup
Описать зону - это только полдела. После установки следует убедиться, что все работает нормально. Другой случай, когда необходим контроль за работой сервера DNS - жалобы пользователей. При этом смотреть свои собственные файлы дело бесполезное, т.к. в них скорее всего ошибок нет, т.к. сервер эксплуатируется уже некоторое время. Едиственный способ убедиться в том, что все работает так, как надо - проиметировать работу системы, взаимодействующей с сервером. Именно эту задачу и решает программа nslookup.
Программа может использоваться в интерактивном режиме и в режиме генерации отчета о разовом запросе. Наиболее часто используют интерактивный способ тестирования. Для интерактивного тестирования достаточно просто вызвать программу по имени при этом в качестве сервера будет взят сервер, указанный в файле конфигурации resolver:
/usr/paul>nslookup
> 144.206.192.1
Server: arch.kiae.su
Address: 144.206.136.10
Name: quest.polyn.kiae.su
Address: 144.206.192.1
>exit
В данном конкретном примере цель запроса состояла в получении имени машины по ее IP-адресу. Возможна и обратная операция, т.е. получение IP-адреса по имени:
/usr/paul>nslookup
> polyn.net.kiae.su
Server: arch.kiae.su
Address: 144.206.136.10
....
Address: 144.206.192.1
>exit
Однако, тестирование имен с локального сервера только проверяет как resolver работает с этим локальным сервером. Для того, чтобы проверить, как имена вашего домена разрешаются с другого сервера доменных имен, следует изменить текущий сервер доменных имен, используемый nslookup в качестве первого при разрешении доменного имени:
> server vega.ru
Default Server: vega.ru
Address: 194.226.43.1
>
В данном случае в качестве текущего сервера выбран сервер vega.ru. После изменения адреса текущего сервера можно снова проверить адреса имен вашего домена на доступность для сервиса доменных имен.
При помощи nslookup можно посмотреть содержание записей базы данных описания зоны. Делается это несколькими способами. Первый из них - это установка типа записей:
> set querytypa=SOA
> polyn.kiae.su
Server: vega.ru
Address: 194.226.43.1
polyn.kiae.su
origin = polyn.net.kiae.su
mail addr = paul.kiae.su
serial = 36
refresh = 3600 (1 hour)
retry = 300 (5 mins)
expire = 9999999 (115 days 17 hours 46 mins 39 secs)
minimum ttl = 3600 (1 hour)
polyn.kiae.su nameserver = polyn.net.kiae.su
polyn.kiae.su nameserver = ns.kiae.su
>
В данном случае установлен тип записи для просмотра - SOA, после этого задано имя polyn.kiae.su. В этовет на этот запрос сервер нашел другой сервер, в зону ответственности которого входит данное имя, и распечатал запись SOA для этой зоны. При этом все поля распечатываются в понятном для чтения виде.
Другой способ заключается в том, чтобы исполбзовать команду ls:
>ls -t soa polyn.kiae.su
.... список записей зоны .....
>
Если необходимо проконтролировать работу сервера и resolver, то в этом случае имеет смысл включить режим отладки - debug:
> set debug
> 1.192.206.144.in-addr.arpa.
Server: ns.kiae.su
Address: 144.206.130.3
------------
Got answer:
HEADER:
opcode = QUERY, id = 20, rcode = NOERROR
header flags: response, auth. answer, want recursion, recursion avail.
questions = 1, answers = 1, authority records = 0, additional = 0
QUESTIONS:
1.192.206.144.in-addr.arpa, type = ANY, class = IN
ANSWERS:
-> 1.192.206.144.in-addr.arpa
name = quest.polyn.kiae.su
ttl = 3600 (1 hour)
------------
1.192.206.144.in-addr.arpa
name = quest.polyn.kiae.su
ttl = 3600 (1 hour)
>
В данном случае запрашивается имя по «обратному» запросу. Программа транслирует сам запрос и способ его исполнения. Для более сложных запросов трасса может составлять несколько экранов.
3.1.9. DNS и безопасность
В сентябре 1996 года многие компьютерные издания Москвы опубликовали материал, в котором рассматривался случай подмены доменных адресов World Wide Web сервера агенства InfoART, что привело к тому, что подписчики этого сервиса втечение некоторого времени вместо страниц этого агенста просматривали картинки «для взрослых».
Администрирование DNS осуществляла компания Demos, поэтому пресс-конферению по поводу этого случая Demos и InfoArt проводили совместно. Разъяснения провайдера главным образом свелись к тому, что в базе данных DNS самого Demos никаких изменений не проводилось, а за состояние баз данных secondary серверов Demos ответственности не несет. Почему такое заявление вполне оправдывает провайдера?
Как было указано раньше, обслуживание запросов на получение IP-адресов по доменным именам, а именно об этом идет речь в случае InfoArt, осуществляется не одним сервером доменных имен, а множеством серверов. Все secondary серверы копируют базу данных с primary сервера, но делают они это с достаточно большими интервалами, иногда не чаще одного раза в двое суток. Запрос разрешает тот сервер, который быстрее откликается на запрос клиента. Таким образом, если подправить информацию на secondary сервере о базе данных primary сервера, то можно действительно на время между копированиями описания зоны заставить пользователей смотреть совсем не то, что нужно. Таким образом, практически все провайдеры попадают в категорию неблагонадежных. Но провайдеры также могут оказаться не при чем. В принципе, любой администратор может запустить у себя на машине named и скопировать зону с primary сервера, не регистрируя ее в центре управления сетью. Это обычная практика, т.к. разрешение имен - главный тормоз при доступе к удаленной машине, и часто по timeout прерывается работа с ресурсом из-за невозможности быстрого разрешения имени. Таким образом, все администраторы сети попадают в потенциальных злоумышленников. Но на самом деле существуют еще и другие способы. Например, кэш resolver или сервера имен. Если время хранения записи в кэше большое, то сервер или resolver не будут обращаться к удаленному серверу вообще, а будут брать записи из кэша. Вмешаться в структуру данных кэша также возможно, а это значит, что можно и увеличить время хранения записи. Если организация- подписчик пользуется для доступа в сеть proxy-сервером, а это также обычная практика, то достаточно поправить кэш этого proxy и все пользователи этой организации будут ходить туда, куда их направит поправленная запись.
Существует несколько способов ограничения этого произвола. Первый из них - это точное знание IP-адресов ресурсов. В этом случае можно проверить состояние ресурса и выявить причину ошибки. Второй сопособ, запретить копировать описание зоны кому не поподя. Современные программы named позволяют описывать IP-адреса сетей, из которых можно копировать зоны. Правда, такая политика должна быть согласована с другими владельцами зоны, в противном случае зону скопируют с secondary сервера. И наиболее мягкое средство - уменьшение времени хранения записей в кэше.
Для защиты можно использовать и фильтрацию пакетов. Зоны раздаются только по 53 порту TCP, в отличие от простых запросов. Если определить правила работы по этому порту, используя межсетевой фильтр, то можно и ограничить произвол при копировании информации с сервера доменных имен. Вообще, не стоит относиться к сервиру доменных имен легкомысленно. Следует учитывать тот факт, что, используя этот сервис, можно выявить структуру вашей локальной сети.
3.2. Электронная почта в Internet
Электронная почта - один из важнейших информационных ресурсов Internet. Она является самым массовым средством электронных коммуникаций. Любой из пользователей Internet имеет свой почтовый ящик в сети. Если учесть, что через Internet можно принять или послать сообщения еще в два десятка международных компьютерных сетей, некоторые из которых не имеют on-line сервиса вовсе, то становится понятным, что почта предоставляет возможности, в некотором смысле даже более широкие, чем просто информационный сервис Internet. Через почту можно получить доступ к информационным ресурсам других сетей. Хорошим примером может служить доступ к архивам сети BITNET - документам и телеконференциям, которые ведутся на серверах списков (LISTSERVER) BITNET.
3.2.1. Принципы организации
Электронная почта во многом похожа на обычную почтовую службу. Корреспонденция, подготавливается пользователем на своем рабочем месте либо программой подготовки почты, либо просто обычным текстовым редактором. Обычно, программа подготовки почты вызывает текстовый редактор, который пользователь предпочитает всем остальным программам этого типа. Затем пользователь должен вызвать программу отправки почты (программа подготовки почты вызывает программу отправки автоматически). Стандартной программой отправки является программа sendmail. Sendmail работает как почтовый курьер, который доставляет обычную почту в отделение связи для дальнейшей рассылки. В Unix-системах sendmail сама является отделением связи. Она сортирует почту и рассылает ее адресатам. Для пользователей персональных компьютеров, имеющих почтовые ящики на своих машинах и работающих с почтовыми серверами через коммутируемые телефонные линии, могут потребоваться дополнительные действия. Так, например, пользователи почтовой службы Relcom должны запускать программу UUPC, которая осуществляет доставку почты на почтовый сервер.
Для работы электронной почты в Internet разработан специальный протокол Simple Mail Transfer Protocol (SMTP), который является протоколом прикладного уровня и использует транспортный протокол TCP. Однако, совместно с этим протоколом используется и Unix-Unix-CoPy (UUCP) протокол. UUCP хорошо подходит для использования телефонных линий связи. Большинство пользователей электронной почты Relcom реально пользуются для доставки почты на узел именно этим протоколом. Разница между SMTP и UUCP заключается в том, что при использовании первого протокола sendmail пытается найти машину-получателя почты и установить с ней взаимодействие в режиме on-line для того, чтобы передать почту в ее почтовый ящик. В случае использования SMTP почта достигает почтового ящика получателя за считанные минуты и время получения сообщения зависит только от того, как часто получатель просматривает свой почтовый ящик. При использовании UUCP почта передается по принципу «stop-go», т.е. почтовое сообщение передается по цепочке почтовых серверов от одной машины к другой, пока не достигнет машины-получателя или не будет отвергнуто по причине отсутствия абонента-получателя. С одной стороны, UUCP позволяет доставлять почту по плохим телефонным каналам, т.к. не требуется поддерживать линию втечение времени доставки от отправителя к получателю, а с другой стороны бывает обидно получить возврат сообщения через сутки после его отправки из-за того, что допущена ошибка в имени пользователя. В целом же общие рекомендации таковы: если имеется возможность надежно работать в режиме on-line и это является нормой, то следует настраивать почту для работы по протоколу SMTP, если линии связи плохие или on-line используется чрезвычайно редко, то лучше использовать UUCP.
|
|

Рис. 3.14. Структура взаимодействия участников почтового обмена
Основой любой почтовой службы является система адресов. Без точного адреса невозможно доставить почту адресату. В Internet принята система адресов, которая базируется на доменном адресе машины, подключенной к сети. Например, для пользователя paul машины с адресом polyn.net.kiae.su почтовый адрес будет выглядеть как:
paul@polyn.net.kiae.su.
Таким образом, адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком «коммерческого @», и доменного адреса машины, который записывается после знака «@». Адрес UUCP был бы записан как строка вида:
net.kiae.su!polyn!paul
Программа рассылки почты Sendmail сама преобразует адреса формата Internet в адреса формата UUCP, если доставка сообщения осуществляется по этому протоколу.
3.2.2. Формат почтового сообщения (RFC-822)
При обсуждении примеров отправки и получения почтовых сообщений уже упоминался формат почтового сообщения. Разберем его подробнее. Формат почтового сообщения Internet определен в документе RFC-822 (Standard for ARPA Internet Text Message). Это довольно большой документ объемом в 47 страниц машинописного текста, поэтому рассмотрим формат сообщения на примерах. Почтовое сообщение состоит из трех частей: конверта, заголовка и тела сообщения. Пользователь видит только заголовок и тело сообщения. Конверт используется только программами доставки. Заголовок всегда находится перед телом сообщения и отделен от него пустой строкой. RFC-822 регламентирует содержание заголовка сообщения. Заголовок состоит из полей. Поля состоят из имени поля и содержания поля. Имя поля отделено от содержания символом «:». Минимально необходимыми являются поля Date, From, cc или To, например:
Date: 26 Aug 76 1429 EDT
From: Jones@Registry.org
cc:
или
Date: 26 Aug 76 1429 EDT
From: Jones@Registry.org
To: Smith@Registry.org
Поле Date определяет дату отправки сообщения, поле From - отправителя, а поля сс и To - получателя(ей). Чаще заголовок содержит дополнительные поля:
Date: 26 Aug 76 1429 EDT
From: George Jones<Jones@Registry.org>
Sender: Secy@SHOST
To: Smith@Registry.org
Message-ID: <4231.629.XYzi-What@Registry.org>
В данном случае поле Sender указывает, что George Jones не является автором сообщения. Он только переслал сообщение, которое получил из Secy@SHOST. Поле Message-ID содержит уникальный идентификатор сообщения и используется программами доставки почты. Следующее сообщение демонстрирует все возможные поля заголовка:
Date: 27 Aug 76 0932
From: Ken Davis <Kdavis@This-Host.This.net>
Subject: Re: The Syntax in the RFC
Sender: KSecy@Other-host
Reply-To: Sam.Irving@Reg.Organization
To: George Jones <Jones@Registry.org>
cc: Important folks:
Tom Softwood <Balsa@Tree.Root>,
"Sam Irving"@Other-Host;,
Standard Distribution:
/main/davis/people/standard@Other-Host
Comment: Sam is away on bisiness.
In-Reply-To: <some.string@DBM.Group>, George`s message
X-Special-action: This is a sample of user-defined field-
names.
Message-ID: <4331.629.XYzi-What@Other-Host
Поле Subject определяет тему сообщения, Reply-To - пользователя, которому отвечают, Comment - комментарий, In-Reply-To - показывает, что сообщение относится к типу «В ответ на Ваше сообщение, отвечающее на сообщение, отвечающее ...», X-Special-action - поле, определенное пользователем, которое не определено в стандарте.
Следует сказать, что формат сообщения постоянно дополняется и совершенствуется. Так в RFC-1327 введены дополнительные поля для совместимости с почтой X.400. Кроме этого, следует обратить внимание на поля некоторых довольно часто встречающихся заголовков, которые не регламентированы в RFC-822. Так первое предложение заголовка, которое начинается со слова From, содержит UUCP-путь сообщения, по которому можно определить, через какие машины сообщение «пробиралось». Поле Received: содержит транзитные адреса почтовых серверов с датой и временем прохождения сообщения. Вся эта информация полезна при разборе трудностей с доставкой почты.
В заключение хотелось бы отметить, что возможности почты не ограничиваются только пересылкой корреспонденции. По почте можно получить доступ ко многим ресурсам Internet, которые имеют почтовых роботов, отвечающих на запросы страждущих. Поэтому имеет смысл более детально изучить программное обеспечение, поддерживающее e-mail. Время, затраченное на чтение документации и опыты, окупятся возможностью получения информации из информационных архивов сети.
3.2.3. Формат представления почтовых сообщений MIME и его влияние на информационные технологии Internet
Стандарт MIME (или в нотации Internet, RFC-1341) предназначен для описания тела почтового сообщения Internet. Предшественником MIME является Стандарт почтового сообщения ARPA (RFC-822). Стандарт RFC-822 был разработан для обмена текстовыми сообщениями. С момента опубликования стандарта возможности аппаратных средств и телекоммуникаций ушли далеко вперед и стало ясно, что многие типы информации, которые широко используются в сети, невозможно передать по почте без специальных преобразований. Так в тело сообщения нельзя включить графику, аудио, видео и другие типы информации. RFC-822 не дает возможностей для передачи даже текстовой информации, которую нельзя реализовать 7-битовой кодировкой ASCII. Естественно, что при использовании RFC-822 не может быть и речи о передаче размеченного текста для отображения его различными стилями. Ограничения RFC-822 становятся еще более очевидными, когда речь заходит об обмене сообщениями в разных почтовых системах. Например, для приема/передачи сообщений из/в X.400 (новый стандарт ISO), который позволяет иметь двоичные данные в теле сообщения, ограничения старого стандарта могут стать фатальными, так как не спасает старый испытанный способ кодировки информации процедурой uuencode, так как эти данные могут быть по различному проинтерпретированы в X.400 и в программе рассылки почты в Internet (mail-agent).
В некотором смысле стандарт MIME ортогонален стандарту RFC-822. Если последний подробно описывает в заголовке почтового сообщения текстовое тело письма и механизм его рассылки, то MIME, главным образом, ориентирован на описание в заголовке письма структуры тела почтового сообщения и возможности составления письма из информационных единиц различных типов.
В стандарте зарезервировано несколько способов представления разнородной информации. Для этого используются специальные поля заголовка почтового сообщения:
· поле версии MIME, которое используется для идентификации сообщения, подготовленного в новом стандарте;
· поле описания типа информации в теле сообщения, которое позволяет обеспечить правильную интерпретацию данных;
· поле типа кодировки информации в теле сообщения, указывающее на тип процедуры декодирования;
· два дополнительных поля, зарезервированных для более детального описания тела сообщения.
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. При этом следует учитывать, что анархия типов (безграничное их увеличение) тоже не допустима. Каждый новый тип в обязательном порядке должен быть зарегистрирован в IANA (Internet Assigned Numbers Authority). Остановимся подробнее на форме и назначении полей, определяемых стандартом.
3.2.3.1. Поле версии MIME (MIME-Version)
Поле версии указывается в заголовке почтового сообщения и позволяет программе рассылки почты определить, что сообщение подготовлено в стандарте MIME. Формат поля выглядит как:
MIME-Version: 1.0
Поле версии указывается в общем заголовке почтового сообщения и относится ко всему сообщению целиком. Здесь уместно отметить, что в отличие от стандарта RFC-822 стандарт MIME позволяет перемешивать поля заголовка сообщения с телом сообщения. Поэтому все поля делятся на два класса: общие поля заголовка, которые записываются в начале почтового сообщения и частные поля заголовка, которые относятся только к отдельным частям составного сообщения и записываются перед ними.
3.2.3.2.
Поле типа содержания тела почтового сообщения
(Content-Type)
Поле типа используется для описания типа данных, которые содержатся в теле почтового сообщения. Это поле сообщает программе чтения почты, какого сорта преобразования необходимы для того, чтобы сообщение правильно проинтерпретировать. Эта же информация используется и программой рассылки при кодировании/декодировании почты. Стандарт MIME определяет семь типов данных, которые можно передавать в теле письма:
· текст (text);
· смешанный тип (multipart);
· почтовое сообщение (message);
· графический образ (image);
· аудио-информация (audio);
· фильм или видео (video);
· приложение (application).
Общая форма записи поля выглядит в записи Бекуса-Наура следующим образом:
Content-Type := type «/» subtype *[«;» parameter]
type := «application» / «audio»
/ «image» / «message»
/ «multipart» / «text»
/ «video» / x-token
x-token := <Два символа «X-», за которыми без пробела
следует последовательность любых символов>
subtype := token
parameter := attribute "=" value
attribute := token
value := token / quoted-string
token := 1*<любой символ кроме пробела и управляющего символа,
или tspecials>
tspecials := «(" / ")» / «<» / «>» / «@» ; Обязательно
/ «,» / «;» / «:» / «\» / <"> ; должны быть,
/ «/» / «[» / «]» / «?» / «.» ; заключены в
/ «=» ; кавычки.
Остановимся подробнее на каждом из типов, разрешенных стандартом MIME.
Text. Этот тип указывает на то, что в теле сообщения содержится текст. Основным подтипом типа «text» является «plain», что обозначает так называемый планарный текст. Понятие планарного текста появилось в связи с тем, что существует еще размеченный текст, т.е. текст со встроенными в него символами управления отображением, и гипертекст, т.е. текст, который можно просматривать не последовательно, а произвольно, следуя гипертекстовым ссылкам. Для обозначения размеченного текста используют подтип «richtext», а для обозначения гипертекста - подтип «html». Вообще говоря, «html» - это специальный вид размеченного текста, который используется для представления гипертекстовой информации в системе World Wide Web, которая получила в последнее время широкое распространение в Internet. Понятие размеченного текста требует более подробного обсуждения, так как его передача и интерпретация являются одной из причин появления стандарта MIME.
«Richtext» определяет текст со встроенными в него специальными управляющими последовательностями, которые в соответствии со стандартом языка разметки документов SGML (Standard Generalized Markup Language) называются тагами. Таги представляют из себя последовательность символов типа «<строка-символов>». «Строка-символов» определяет управляющее действие. Таги делятся на таги начала элемента текста («<......>») и таги конца элемента текста («</......>»). В качестве примера такой разметки можно привести следующий фрагмент текста:
<bold>Now</bold> is the time for
<italic>all</italic> good men
<smaller>(and <lt>women>)</smaller> to
<ignoreme></ignoreme> come
to the aid of their
<nl>
В этом фрагменте <bold> означает выделение «жирным» шрифтом, <italic> - курсив, <smaller> - мелкий шрифт, <lt> - знак «<», игнорирование обозначено как <ignoreme>, новая строка как <nl>. Далее приведен полный перечень управляющих последовательностей:
|
Bold |
«жирный» шрифт |
|
Italic |
Курсив |
|
Fixed |
causes the subsequent text to be in a fixed width font |
|
Smaller |
уменьшенный шрифт |
|
Bigger |
увеличенный шрифт |
|
Underline |
подчеркнутый текст |
|
Center |
отцентрированный текст |
|
FlushLeft |
выровненный по левому краю |
|
FlushRight |
выровненный по правому краю |
|
Indent |
отступ от левого края |
|
IndentRight |
отступ от правого края |
|
Outdent |
отмена левого отступа |
|
OutdentRight |
отмена правого отступа |
|
SamePage |
размещение текста на одной странице |
|
Subscript |
подстрочный текст |
|
Superscript |
надстрочный текст |
|
Heading |
заголовок |
|
Footing |
текст ссылки |
|
ISO-8859-X |
текст в кодировке ISO-8859-X |
|
US-ASCII |
текст в кодировке US-ASCII |
|
Excerpt |
цитата |
|
Paragraph |
параграф |
|
Signature |
автограф (подпись) |
|
Comment |
комментарий (не отображается) |
|
No-op |
нет операции |
|
lt |
знак «меньше»(«<») |
|
nl |
новая строка |
|
np |
новая страница |
Специальный тип разметки задается подтипом «html». Это так называемый гипертекст. Разметка гипертекста строится по тому же принципу, как и в тексте типа «richtext». Однако применяются таги, позволяющие описать гипертекстовые ссылки. К таким тагам относятся «<A HREF= «......»>.....</A>», <IMG ....>, <A NAME= «....»></A>. Таг «<A HREF= «......»> .......</A>» определяет следующий фрагмент текста, который будет просматриваться. При этом текст между тагом начала и тагом конца выделяется в программе просмотра цветом или другим способом и используется как контекстная гипертекстовая ссылка. Таг <IMG .....> задет встроенный в текст документа графический образ. В некотором смысле этот таг аналогичен «multipart», который разрешает комбинировать сообщение из нескольких фрагментов разного типа. Таг <A NAME...> определяет "якорь", т.е. место внутри документа, на которое можно сослаться как на метку. В качестве примера такой разметки текста можно привести следующий фрагмент:
Это пример разметки документа в формате HTML.
<H1> Это заголовок документа</H1>
<P> - Это параграф.
<A HREF= «test.html#mark1»> Это пример гипертекстовой ссылки.</A>
<IMG SRC= «test.gif» ALIGN=Bottom> Это встроенный image.
<A NAME= «mark1»></A> Это «якорь» внутри текста документа.
Multipart. Этот тип содержания тела почтового сообщения определяет смешанный документ. Смешанный документ может состоять из фрагментов данных разного типа. Данный тип имеет ряд подтипов.
Подтип «mixed» может создавать сообщения, состоящие из нескольких фрагментов, которые разделены между собой границей, задаваемой в качестве параметра подтипа. Приведем простой пример:
From: Nathaniel Borenstein <nsb@bellcore.com>
To: Ned Freed <ned@innosoft.com>
Subject: Sample message
MIME-Version: 1.0
Content-type: multipart/mixed; boundary= «simple boundary»
This is the preamble. It is to be ignored, though it is a handy place for mail composers to include an explanatory note to non-MIME compliant read ers.
--simple boundary
This is implicitly typed plain ASCII text.
It does NOT end with a linebreak.
--simple boundary
Content-type: text/plain; charset=us-ascii
This is explicitly typed plain ASCII text.
It DOES end with a linebreak.
--simple boundary--
This is the epilogue. It is also to be ignored.
В данном примере поле «Content-Type» определяет подтип «mixed» и границу между фрагментами, как строку «--simple boundary—». В начале каждого фрагмента может быть задана своя строка с полем «Content-Type». Как видно из примера, существует два фрагмента, которые не отображаются: преамбула и эпилог, в которые можно поместить комментарии.
Другим подтипом может быть подтип «alternative». Данный подтип позволяет организовать вариабельный просмотр почтового сообщения в зависимости от типа программы просмотра. Приведем пример:
From: Nathaniel Borenstein <nsb@bellcore.com>
To: Ned Freed <ned@innosoft.com>
Subject: Formatted text mail
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary=boundary42
--boundary42
Content-Type: text/plain; charset=us-ascii
...plain text version of message goes here....
--boundary42
Content-Type: text/richtext
.... richtext version of same message goes here ...
--boundary42
Content-Type: text/x-whatever
.... fanciest formatted version of same message goes here
...
--boundary42--
В этом примере для работы с планарным текстом при использовании алфавитно-цифровых программ просмотра предназначен первый фрагмент текста. Для просмотра размеченного текста используется второй фрагмент, для специальной программы просмотра может быть подготовлен специальный вариант (фрагмент 3).
Подтип «digest» предназначен для многоцелевого почтового сообщения, когда различным частям хотят приписать более детальную информацию, чем просто тип:
From: Moderator-Address
MIME-Version: 1.0
Subject: Internet Digest, volume 42
Content-Type: multipart/digest;
boundary= «---- next message ----»
------ next message ----
From: someone-else
Subject: my opinion
...body goes here ...
------ next message ----
From: someone-else-again
Subject: my different opinion
... another body goes here...
------ next message ------
Приведенный пример показывает, как можно воспользоваться подтипом «digest» для рассылки разным пользователям и по разному поводу почты, используя поля «From» и «Subject» в качестве частных заголовков.
Подтип «parallel» предназначен для составления такого почтового сообщения, части которого должны отображаться одновременно, что предполагает запуск сразу нескольких программ просмотра. Синтаксис такого сообщения аналогичен рассмотренным выше.
Тип «message» предназначен для работы с обычными почтовыми сообщениями, которые, однако, не могут быть переданы по почте по разного рода причинам. Эти причины объясняются подтипами данного типа.
Подтип «partial» предназначен для передачи одного большого сообщения по частям для последующей автоматической сборки у получателя. Приведем пример передачи аудио-сообщения разбитого на части:
X-Weird-Header-1: Foo
From: Bill@host.com
To: joe@otherhost.com
Subject: Audio mail
Message-ID: id1@host.com
MIME-Version: 1.0
Content-type: message/partial;
id= «ABC@host.com»;
number=1; total=2
X-Weird-Header-1: Bar
X-Weird-Header-2: Hello
Message-ID: anotherid@foo.com
Content-type: audio/basic
Content-transfer-encoding: base64
... first half of encoded audio data goes here...
and the second half might look something like this:
From: Bill@host.com
To: joe@otherhost.com
Subject: Audio mail
MIME-Version: 1.0
Message-ID: id2@host.com
Content-type: message/partial;
id= «ABC@host.com»; number=2; total=2
... second half of encoded audio data goes here...
Атрибуты подтипа определяют идентификатор сообщения (id), номер порции (number) и общее число порций (total). Следует обратить внимание на то, что каждая часть имеет свое поле «Content-Type». Это означает, что все сообщение может состоять из частей разных типов.
Другим подтипом является «External-Body», который позволяет ссылаться на внешние, относительно сообщения, информационные источники. Приведем конкретный пример:
From: Whomever
Subject: whatever
MIME-Version: 1.0
Message-ID: id1@host.com
Content-Type: multipart/alternative; boundary=42
--42
Content-Type: message/external-body;
name="BodyFormats.ps";
site="thumper.bellcore.com";
access-type=ANON-FTP;
directory="pub";
mode="image";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
--42
Content-Type: message/external-body;
name="/u/nsb/writing/rfcs/RFC-XXXX.ps";
site="thumper.bellcore.com";
access-type=AFS
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
--42
Content-Type: message/external-body;
access-type=mail-server
server="listserv@bogus.bitnet";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
get rfc-xxxx doc
--42--
В данном примере использованы «External-Body» и «multipart/alternative». Все сообщение разбито на несколько фрагментов. В каждом из фрагментов находится ссылка на внешний файл. Реально, тела почтового сообщения нет (границы программами просмотра не отображаются). Однако, если программа просмотра способна работать с внешними протоколами, то можно ссылки разрешить автоматически, запуская соответствующий сервис.
Стандартным подтипом типа «message» является «rfc822». Данный подтип определяет сообщения стандарта RFC-822.
Типы описания нетекстовой информации. Таких типов имеется четыре:
· «image» для описания графических образов. Наиболее часто используются файлы форматов GIF и JPEG.
· «audio» для описания аудио-информации. Для воспроизведения сообщения данного типа требуется специальное оборудование.
· «video» для передачи фильмов. Наиболее популярным является формат MPEG.
· «application» для передачи данных любого другого формата. Обычно используется для передачи двоичных данных с последующим промежуточным преобразованием. Так, если на машине стоит видео-карта с 512Kb памяти, а графика подготовлена в 256 цветах, то сначала ее следует преобразовать и здесь может помочь тип «application». Основной подтип данного типа – «octet-stream», но существуют «ODA» и «Postscript». Назначение данных подтипов ясно из названия - обозначение данных для последующей обработки как данных в форматах, определяемых подтипом.
3.2.3.3. Поле типа кодирования почтового сообщения (Content-Transfer-Encoding)
Многие данные передаются по почте в их исходном виде. Это могут быть 7bit символы, 8bit символы, 64base символы и т.п. Однако, при работе в разнородных почтовых средах необходимо определить механизм их представления в стандартном виде - US-ASCII. Для этого существуют процедуры кодирования такого сорта данных. Наиболее широко применяемая - uuencode. Для того, чтобы при получении данные были бы правильно распакованы, в стандарт введено поле «Сontent-Transfer-Encoding». Синтаксис этого поля следующий:
Content-Transfer-Encoding := «BASE64» / «QUOTED-PRINTABLE» /
«8BIT» / «7BIT» /
«BINARY» / x-token
Каждая из альтернатив применяется в своем подходящем случае. Альтернативы «8bit», «7bit», «BINARY» реально никакого преобразования не требуют, так как почта передается байтами и SMTP не делает различия между ними. Однако, они введены для строгости описания типов. «BASE64» обычно используется в связке с типом «text/ISO-8859-1». Элемент «x-token» позволяет пользователю описать свою процедуру преобразования.
3.2.3.4. Дополнительные необязательные поля
Как уже говорилось ранее, стандарт определяет еще два дополнительных поля: «Content-ID» и «Content-Description». Первое поле определяет уникальный идентификатор содержания, а второе служит для комментария содержания. Ни то, ни другое программами просмотра, обычно, не отображаются.
В заключение обсуждения стандарта MIME приведем комплексный пример без комментариев:
MIME-Version: 1.0
From: Nathaniel Borenstein <nsb@bellcore.com>
Subject: A multipart example
Content-Type: multipart/mixed;
boundary=unique-boundary-1
This is the preamble area of a multipart message.
Mail readers that understand multipart format should ignore this preamble.
If you are reading this text, you might want to consider changing to a
mail reader thatunderstands how to properly display multipart messages.
--unique-boundary-1
...Some text appears here...
[Note that the preceding blank line means no header fields were given and this is text,
with charset US ASCII. It could have been done with explicit typing as in the next part.]
--unique-boundary-1
Content-type: text/plain; charset=US-ASCII
This could have been part of the previous part, but illustrates explicit versus implicit
typing of body parts.
--unique-boundary-1
Content-Type: multipart/parallel;
boundary=unique-boundary-2
--unique-boundary-2
Content-Type: audio/basic
Content-Transfer-Encoding: base64
... base64-encoded 8000 Hz single-channel
u-law-format audio data goes here....
--unique-boundary-2
Content-Type: image/gif
Content-Transfer-Encoding: Base64
... base64-encoded image data goes here....
--unique-boundary-2--
--unique-boundary-1
Content-type: text/richtext
This is <bold><italic>richtext.</italic></bold>
<nl><nl>Isn't it
<bigger><bigger>cool?</bigger></bigger>
--unique-boundary-1
Content-Type: message/rfc822
From: (name in US-ASCII)
Subject: (subject in US-ASCII)
Content-Type: Text/plain; charset=ISO-8859-1
Content-Transfer-Encoding: Quoted-printable
... Additional text in ISO-8859-1 goes here ...
--unique-boundary-1--
Подводя итоги обсуждения, еще раз следует отметить, что стандарт MIME позволяет расширить область применения электронной почты, обеспечить доступ к другим информационным ресурсам сети в стандартных форматах.
3.2.4. Протокол обмена почтой SMTP (Simple Mail Transfer Protocol)
Протокол SMTP был разработан для обмена почтовыми сообщениями в сети Internet. SMTP не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами, отличными от TCP/IP и Х.25. Достигается это за счет концепции IPCE (InterProcess Communication Environment). IPCE позволяет взаимодействовать процессам, поддерживающим SMTP, в интерактивном режиме, а не в режиме “STOP-GO”.
Модель протокола. Взаимодействие в рамках SMTP строится по принципу двусторонней связи, которая устанавливается между отправителем и получателем почтового сообщения. При этом отправитель инициирует соединение и посылает запросы на обслуживание, а получатель - отвечает на эти запросы. Фактически, отправитель выступает в роли клиента, а получатель - сервера.
|
|
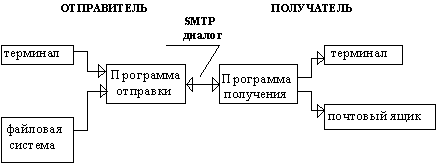
Рис. 3.15. Схема взаимодействия по протоколу SMTP
Канал связи устанавливается непосредственно между отправителем и получателем сообщения. При таком взаимодействии почта достигает абонента втечение нескольких секунд после отправки.
Дисциплины работы и команды протокола. Обмен сообщениями и инструкциями в SMTP ведется в ASCII-кодах. В протоколе определено несколько видов взаимодействия между отправителем почтового сообщения и его получателем, которые здесь называются дисциплинами.
Наиболее распространенной дисциплиной является отправление почтового сообщения, которое начинается по команде MAIL, идентифицирующей отправителя:
MAIL FROM: paul@quest.polyn.kiae.su
Следующей командой определяется адрес получателя:
RCPT TO: paul@apollo.polyn.kiae.su
После того, как определены отправитель и получатель, можно отправлять сообщение:
DATA
Команда DATA вводится без параметров и идентифицирует начало ввода почтового сообщения. Сообщение вводится до тех пор, пока не будет введена строка с точкой в первой позиции. Согласно стандарту почтового сообщения RFC-822 отправитель передает заголовок и тело сообщения, которые разделены пустой строкой. Сам протокол SMTP не накладывает каких-либо ограничений на информацию, которая заключена между командой DATA и «.» в первой позиции последней строки. Приведем пример обмена сообщениями при дисциплине отправки почты:
S: MAIL FROM: <paul@quest.polyn.kiae.su>
R: 250 Ok
S: RCPT TO: <dobr@kiae.su>
R: 250 Ok
S: DATA
R: 354 Start mail input; end with <CRLF>.<CRLF>
S: Это текст почтового сообщения
S: .
R: 250
Другой дисциплиной, определенной в протоколе SMTP, является перенаправление почтового сообщения (forwarding). Если получатель не найден и известно его местоположение, то сервер может выдать сообщение:
R: 251 User not local; will forward to <user@domain.domain>
Если сервер может сделать только предположение о дальнейшей рассылке, то ответ будет несколько иным:
R: 551 User not local; please try <user@host.domain>
Верификация и расширение адресов составляют дисциплину верификации. В ней используются команды VRFY и EXPN. По команде VRFY сервер подтверждает наличие или отсутствие указанного пользователя:
S: VRFY paul
R: 250-Paul Khramtsov<paul@quest.polyn.kiae.su>
Используя команду EXPN, можно получить список местных пользователей:
S: EXPN Example-People
R: 250-Paul Khramtsov<paul@quest.polyn.kiae.su>
R: 250-Vladimir Drach-Gorkunov<vovka@quest.polyn.kiae.su>
В список дисциплин, разрешенных протоколом SMTP, входит кроме отправки почты еще и прямая рассылка сообщений. В этом случае сообщение будет отправляться не в почтовый ящик, а непосредственно на терминал пользователя, если пользователь в данный момент находится за своим терминалом. Прямая рассылка осуществляется по команде SEND, которая имеет такой же синтаксис, как и команда MAIL. Кроме SEND прямую рассылку осуществляют SOML (Send or Mail) и SAML (Send and Mail).
Для инициализации канала обмена почтой и его закрытия используются команды HELO и QUIT соответственно. Первой командой сеанса должна быть команда HELO.
Протокол допускает рассылку почтовых сообщений в режиме оповещения. Для этого отправитель в адресе получателя может указать несколько пользователей или групповой адрес. Обычно, программное обеспечение SMTP выбирает эту информацию из заголовка почтового сообщения и на ее основе формирует параметры команд протокола.
Если сообщение по какой-либо причине не может быть разослано, то получатель формирует сообщение о неразосланном сообщении:
S: MAIL FROM:<>
R: 250 Ok
S: RCPT TO: <@host.domain:JOE@host.domain>
R: 250 Ok
S: DATA
R: 354 send the mail data, end with .
S: Date 23 Oct 95 11:23:30
S: From: SMTP@remote.domain
S: To: <JOE@host.domain>
S:
S: Undelivered message. Your message lost. 550 No such user.
S: .
При использовании доменных имен следует использовать канонические имена, т.к. некоторые системы не могут определить синоним по базе данных named.
Кроме вышеперечисленных дисциплин, протокол позволяет отправителю и получателю меняться ролями друг с другом. Происходит это по команде TURN.
Для отладки или проверки соединения по SMTP можно использовать telnet. Для этого вслед за адресом машины следует ввести номер порта:
/users/local>telnet apollo.polyn.kiae.su 25
25 порт используется в Internet для обмена сообщениями по протоколу SMTP. В интерактивном режиме пользователь сам изображает клиента SMTP и может посмотреть реакцию удаленной машины на его действия.
3.2.5. Интерфейс Eudora
Интерфейс Eudora является одним из множества почтовых интерфейсов, ориентированных на работу с почтой Internet из системы MS-Windows. На примере этого интерфейса мы рассмотрим типичные проблемы, которые возникают у пользователей персональных компьютеров при подключении к почтовому сервису Internet, и пути их решения.
Первой проблемой является тот факт, что компьютер выключается из сети на время отсутствия пользователя. Это значит, что в это время прием почтовых сообщений не производится. Следовательно, вся почта должна храниться на почтовом сервере и получаться пользователем по его запросу. При работе с Unix об этом заботится программа sendmail, в MS-Windows такой программы нет (точнее есть, но она не ориентирована на Internet). Поэтому обычно применяется следующая схема (рисунок 3.16):
|
|
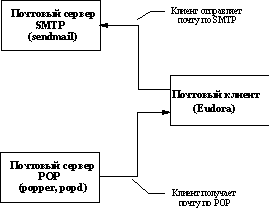
Рис. 3.16. Схема работы с почтовым сервером из-под MS-Windows и MS-DOS
Такая схема предполагает, что пользователь имеет почтовый ящик на машине-сервере, которая не выключается круглосуточно. Все почтовые сообщения складываются в этот почтовый ящик. По мере необходимости, пользователь из своего почтового клиента обращается к почтовому ящику и забирает из него пришедшую на его имя почту. При отправке программа-клиент обращается непосредственно к серверу рассылки почты и передает отправляемые сообщения на этот сервер для дальнейшей рассылки.
Подробно система рассылки сообщений будет описана ниже, но здесь эти сведения необходимы для описания некоторых особенностей интерфейса Eudora, и поэтому, несколько забегая вперед, имеет смысл с ними познакомиться.
На рисунке 3.17 приведен экран Eudora, на котором представлено меню настройки и два почтовых ящика: принятых писем и отправленных писем.
На этом рисунке в меню настроек хорошо виден POP Account - адрес пользователя на машине-сервере, SMTP-сервер и POP (Ph) сервер. Как видно из настроек, Eudora каждые 30 минут проверяет почтовый ящик пользователя и сообщает о получении новых писем. Кроме того, что Eudora позволяет читать просто письма в обычном почтовом формате Internet (RFC822), о котором пойдет речь в следующем параграфе, она распознает и новый формат, ориентированный на отображение мультимедийных почтовых сообщений MIME, который последнее время становится все более популярен в Internet.
|
|
Рис. 3.17. Интерфейс Eudora для MS-Windows
Для установки этого интерфейса требуются определенные знания и доступ к информации, которой располагает только системный администратор, поэтому предпочтительней обратиться именно к нему с просьбой об установке программы или за необходимой информацией (адреса машин серверов). Работа с Eudora чрезвычайно проста: надо выбирать при помощи мыши или клавиатуры интересующие Вас сообщения и отправлять в «корзину» то, что бесполезно.
И последнее замечание относительно работы из-под MS-Windows с почтой в Internet. Если пользователь пишет только по-английски, то у него нет проблем с кодировкой и набором текста, но если он пишет по-русски и получает такие же сообщения, то сразу же возникают проблемы. Дело в том, что большинство почтовых сетей для обмена данными между серверами используют кодировку KOI8. Эта кодировка отличается как от кодировки для MS-DOS, так и от кодировки MS-Windows. Поэтому, возвращаясь к иллюстрации с настройками интерфейса Eudora, хочется обратить внимание читателя на поля «Send Font» и «Printer Font». В этих полях указан шрифт «Arial-Relcom», который разложен по кодировке KOI8, и используется для отображения и печати почтовых сообщений. Для того, чтобы правильно набирать сообщения, следует к стандартным раскладкам клавиатуры в драйвере клавиатуры (cyrwin, например) добавить раскладку для KOI8.
При этом драйвер должен уметь менять раскладку по мере необходимости. В противном случае у пользователя будет возможность читать сообщения, но не набирать их.
На этом описание существующих почтовых клиентов можно закончить, так как в наличии имеется их великое множество и описать их все в рамках этого курса нет возможности.
3.2.6. Системы почтовой рассылки (программа sendmail)
Основным средством рассылки почты в Internet является программа sendmail. Она обеспечивает работу модульной системы рассылки, которая предназначена для получения и отправки корреспонденции, а также управления программами подготовки и просмотра почтовых сообщений. Sendmail позволяет организовать почтовую службу локальной сети и обмениваться почтой с другими серверами почтовых служб через специальные шлюзы. Sendmail может быть сконфигурирована для работы с различными почтовыми протоколами. Обычно это протоколы UUCP (Unix-Unix-CoPy) и SMTP (Simple Mail Transfer Protocol).
Sendmail работает в стиле «отделения связи» обычной почтовой службы, которое принимает и пересылает почтовые сообщения. Sendmail может интерпретировать два типа почтовых адресов:
· почтовые адреса SMTP;
· почтовые адреса UUCP.
Первые являются стандартными адресами Internet и фактически являются стандартом де-факто. Именно этот адрес обычно указан на визитных карточках.
Sendmail можно настроить для поддержки:
· списка адресов-синонимов;
· списка адресов рассылки пользователя;
· автоматической рассылки почты через шлюзы;
· поддержки очередей сообщений для повторной рассылки почты в случае отказов при рассылке;
· работы в качестве SMTP-сервера;
· доступа к адресам машин через сервер доменных имен BIND;
· для доступа к внешним серверам имен.
3.2.6.1. Принцип работы программы sendmail
Sendmail отправляет почту в два приема: сначала почтовые сообщения собираются в очереди, а затем отсылаются.
Каждое сообщение состоит из трех частей: конверта, заголовка и тела сообщения.
Конверт. Конверт состоит из адреса отправителя, адреса получателя и информации рассылки, которая используется программами подготовки, рассылки и получения почты. Конверт остается невидимым для отправителя и получателя почтового сообщения.
Заголовок. Заголовок состоит из стандартных текстовых строк, которые содержат адреса, информацию о рассылке и данные. Заголовок может быть частью подготовленного пользователем текстового файла, а может быть подготовлен и добавлен к телу сообщения программой подготовки почты. Данные из заголовка могут быть использованы для оформления конверта сообщения.
Тело сообщения. Первая пустая строка в файле почтового сообщения отделяет заголовок от тела сообщения. Все, что следует после этой строки, называется телом сообщения и передается по почте без изменений.
Sendmail может быть вызвана:
· программой подготовки сообщений для отправки уже подготовленных сообщений;
· программой получения почты для пересылки полученной из сети почты;
· непосредственно пользователем для отправки по почте файла или короткого сообщения;
· почтовым демоном, которым обычно является сама sendmail.
После того, как почта собрана, начинается ее рассылка. При этом выполняются следующие действия:
· адреса отправителя и получателя преобразуются в формат сети-получателя почты;
· если необходимо, то в заголовок сообщения добавляются строки, позволяющие получателю отвечать на принятое сообщение (например: FROM: <адрес>);
· почта передается одной из программ рассылки почты.
На рисунке 3.18 представлена схема функционирования почтового сервера на базе программы sendmail.
|
|
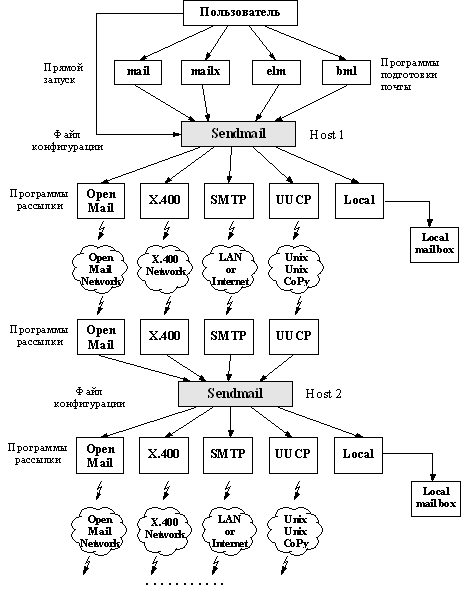
Рис. 3.18. Схема функционирования почтового сервера на базе программы Sendmail
Когда программа приема почты получает сообщение, то она передает его программе sendmail для последующей рассылки. Если сообщение достигло машины адресата, то оно отправляется программой местной рассылки в почтовый ящик пользователя.
Первый этап рассылки - сбор сообщений. Sendmail получает почтовые сообщения из трех источников:
· командной строки или стандартного ввода;
· через SMTP-протокол (из сети);
· из очереди сообщений.
При получении сообщений из командной строки или стандартного ввода, sendmail вызывается пользователем с указанием адреса доставки сообщения. При этом выполняются следующие действия: определяется адрес отправителя, выбирается из командной строки адрес получателя, и оба адреса преобразуются в соответствии с описанием файла конфигурации, определяется способ доставки сообщения, размещается заголовок в оперативной памяти для последующих преобразований, а тело сообщения размещается во временном файле для отправки без изменений.
При получении сообщений по протоколу SMTP, sendmail используется как программа клиента и сервера протокола. Протокол определен в RFC-821 и является основным для рассылки почты в Internet. В этом случае sendmail запускается как демон, который «слушает» порт TCP и в случае получения сообщения устанавливает соединение с удаленным клиентом SMTP. Как правило, таким клиентом является другая программа sendmail.
Программа подготовки почты на локальной машине также может использовать SMTP. Для этого sendmail открывает канал (pipe) межпроцессного обмена.
При получении сообщений из очереди используются временные файлы очередей. Эти очереди используются для хранения неразосланных сообщений. Сообщение хранится в двух файлах. В одном файле хранится тело сообщения, а в другом конверт и заголовок сообщения. Обычно sendmail опрашивает очереди через определенные администратором почтового сервера промежутки времени, на предмет наличия в них неразосланных сообщений.
Вторая стадия рассылки почты - рассылка сообщений.
Как только одним из описанных выше способов sendmail получила сообщение, делается попытка его отправить по адресу. Для этого sendmail определяет три параметра: программу рассылки, узел сети и получателя. Эта процедура производится по правилам, которые содержатся в файле конфигурации. Sendmail сохраняет одну копию тела сообщения во временном файле, а заголовок загружает в оперативную память. Для каждого сообщения программа доставки (рассылки) сообщений вызывается отдельно. Если сообщение должно быть доставлено на разные машины, то для каждой из машин также вызывается своя программа доставки. Некоторые программы могут обслуживать сразу несколько абонентов одной машины, если это невозможно, то для каждого абонента вызывается также своя программа доставки. Рассматривают два типа рассылки: на удаленную машину и местную рассылку.
Рассылка на удаленную машину. Для вызова программы рассылки sendmail открывает pipe и запускает программу рассылки, командная строка которой находится в файле конфигурации. Sendmail записывает заголовок и тело сообщения в pipe. Если программа рассылки не использует протокол SMTP, то адрес получателя передается через pipe. Если используется SMTP, то открывается двунаправленный канал для интерактивного взаимодействия с удаленным сервером SMTP. Если в качестве транспортного протокола используется TCP, то sendmail не запускает внешнюю программу рассылки, а сама инициирует TCP-соединение с удаленным сервером SMTP.
Доставка местной почты. Если sendmail определяет, что адреса доставки местные, то происходит обращение к файлу адресных синонимов и производится преобразование адресов (расширение). Файл адресных синонимов можно использовать для перенаправления почты в файлы или для обработки местными программами. Пользователь может иметь и свой собственный файл адресных синонимов для управления рассылкой персональной почты. После преобразования адресов почта отправляется программе местной рассылки (например, rmail).
Важным моментом при работе sendmail является алгоритм определения типа адресов. При использовании стандартного файла конфигурации применяются следующие правила: почта рассылается в соответствии с форматом адреса получателя, адреса при этом бывают местные, UUCP и SMTP.
Местные адреса имеют вид:
user
user@localhost
user@localhost.localdomain
user@alias
user@alias.localdomain
user@[local.host.internet.address]
localhost!user
localhost!localhost!user
user@localhost.uucp
Местный адрес - это адрес, который распознается как адрес на машине, с которой осуществляется отправка почты.
Адреса UUCP имеют вид:
host!user
host!host!user
user@host.uucp
Если машина, с которой отправляется почта, имеет прямую линию связи по протоколу UUCP со следующей машиной (в адресе), то почта передается на эту машину, если такого соединения нет, то почта не рассылается и выдается сообщение об ошибке. Файл конфигурации должен содержать детальное описание маршрутов для пересылки сообщений на машины по протоколу UUCP.
Адреса SMTP - это адреса, описанные в стандарте RFC-822 или стандартные адреса Internet. Эти адреса имеют вид:
usr@host
usr@host.domain
<@host1,@host2,@host3:user@host4>
user@[remote.host`s.internet.address]
Почта с адресами SMTP рассылается по протоколу SMTP.
Если в системе для адресации используется BIND-сервер, то sendmail может определять адреса получателей, используя сервис BIND. Если BIND не используется, то sendmail сама определяет адреса.
При рассылке почты можно использовать и смешанную адресацию:
user%hostA@hostB - почта отправляется с машины hostB на машину hostA
user!hostA@hostB - почта отправляется с машины hostB на машину hostA
hostA!user%hostB - почта отправляется с hostA на hostB
Подводя итог под обсуждением принципов работы sendmail следует специально подчеркнуть тот факт, что почта реально рассылается двумя принципиально разными способами. При использовании протокола UUCP почта рассылается по принципу «stop-go», т.е. сообщения передаются от машины к машине по указанному в адресе пути. Следует ясно представлять, если почта ушла с машины отправителя, то это не означает, что она поступит получателю. Промежуточная машина может вернуть почту назад, если не сможет разослать. Электронная почта действительно работает как система обычной почты, физически перемещая и храня сообщения на промежуточных почтовых станциях. При работе по протоколу SMTP почта реально отправляется только тогда, когда установлено интерактивное соединение с программой-сервером на машине-получателе почты. При этом происходит обмен командами между клиентом и сервером протокола SMTP в режиме on-line. При смешанной адресации доставка почты происходит по смешанному сценарию. Как шла доставка и как маршрутизировалось сообщение можно определить из заголовка сообщения, которое вы получили.
3.2.7. Настройка программы sendmail
Настройка программы sendmail происходит при помощи файла /etc/sendmail/conf. Этот файл можно разбить на несколько частей:
· Описание особенностей данной машины (local information) - в данной секции описываются такие параметры, как имя данной машины, имя UUCP и т.п.
· Описание макроопределений sendmail, отвечающих за работу в локальной сети, например имя домена и «официальное имя» машины.
· Описание классов, т.е. групп имен, которые используются программой для рассылки почты. Например, для рассылки в другие почтовые службы.
· Номер версии файла конфигурации. Данная переменная должна изменяться каждый раз, как только в файл конфигурации вносятся какие-либо изменения.
· Внутренние макроопределения sendmail. В данном разделе присваиваются значения переменным, которые sendmail использует при взаимодействии с другими транспортными агентами.
· Опции команды sendmail. Опции определяют режимы работы программы. Опции можно задавать в виде параметров командной строки, а можно в виде описаний в файле настройки.
· Определение порядка сообщений программы sendmail (Precedence). Обычно эта секция не модифицируется администратором.
· Доверенные пользователи. В данной секции описываются пользователи, которым разрешено переписывать адреса отправителей, т.е. выступать не под тем адресом, который за ними закреплен.
· Описание формата заголовка почтового сообщения. В данной секции определяются поля и их формат, которые отображаются в заголовке. Многие поля заголовка sendmail генерирует на основе информации из конверта почтового сообщения.
· Правила преобразования адресов. Это самая большая часть файла конфигурации программы sendmail. Преобразование адресов необходимо для принятия программой решений о пути рассылки почтовых сообщений, т.к. это решение принимается на основе полученного в результате преобразований почтового адреса.
· Описание программ рассылки. В данной секции описываются имена программ рассылки, пути и параметры командной строки этих программ. Обычно это программа местной рассылки, рассылка по UUCP, рассылка по SMTP, рассылка на выполнение.
· Общий набор правил преобразования адресов, который не меняется от машины к машине и от конфигурации к конфигурации (Rule Set 0).
· Машино-зависимая часть общего правила преобразования адресов. В данной секции содержание определяется способом рассылки почты. Например, данная секция при рассылке по SMTP будет отличаться от случая рассылки по UUCP.
В большинстве случаев все изменения, которые приходиться внести в файл конфигурации касаются только имени машины, домена и машин шлюзов в другие почтовые службы. Однако, если у организации имеется достаточно продолжительная и славная история использования электронной почты, то может оказаться, что для нормального функционирования придется произвести и ряд более существенных изменений.
В целом все описанные выше секции решают три основных задачи:
· определение окружения sendmail,
· анализ и преобразование адресов электронной почты,
· рассылка сообщений при помощи программ рассылки.
При редактировании файла следует учитывать некоторые правила, которые используются при написании файла конфигурации: вся информация локального характера сосредоточена в начале файла, команды одного типа собраны в компактные группы, большую часть файла составляют правила преобразования адресов, в конце файла описаны программы рассылки электронной почты.
Все команды, которые используются в файле настроек sendmail можно представить в виде следующей таблицы:
|
Команда |
Синтаксис |
Назначение |
|
Define Macro |
Dxvalue |
Установить значение x |
|
Define Class |
Ссword1 word2 ... |
Установить значение класса c |
|
Define Class |
Fcfile |
загрузить значение класса из файла |
|
Set Option |
Oovalue |
Установить значение опции o |
|
Trusted Users |
Tuser1 user2 ... |
Определить доверенных пользователей |
|
Set Precedence |
Pname=number |
Для номера ошибки number установить имя name |
|
Define Mailer |
Mname,[field=value] |
Определить программу рассылки почты. |
|
Define Header |
H[?mflag?]name:format |
Определить формат поля заголовка |
|
Set Rulset |
Sn |
Начать определение набора правил преобразования адресов |
|
Define Rule |
Rlhs rhs comment |
Определить правило преобразования адреса. |
Формат команды файла настроек sendmail не очень удобен для чтения. В целом его можно определить следующим образом:
|
|

Рис. 3.19. Структура команды файла настроек sendmail
Теперь разберем более подробно некоторые команды и секции файла настроек sendmail. Лучше всего это сделать на основе реального файла. Начнем с секции описания локальных параметров:
##################
# local info #
##################
Cwlocalhost
CP.
# UUCP relay host
DYucbvax.Berkeley.EDU
CPUUCP
# BITNET relay host
#DBmailhost.Berkeley.EDU
DBrelay.kiae.su
CPBITNET
# "Smart" relay host (may be null)
DSrelay.kiae.su
# who I send unqualified names to (null means deliver locally)
DR
# who gets all local email traffic ($R has precedence for unqualified names)
DH
# who I masquerade as (null for no masquerading)
DM
# class L: names that should be delivered locally, even if we have a relay
# class E: names that should be exposed as from this host, even if we masquerade
#CLroot
CEroot
# operators that cannot be in local usernames (i.e., network indicators)
CO @ % !
# a class with just dot (for identifying canonical names)
C..
# dequoting map
Kdequote dequote
Как видно из этого листинга, в данной секции описаны имя данной машины (Dwlocalhost), а также класс машин-шлюзов в другие почтовые системы. При этом наращивание класса происходит по мере описания шлюза для каждого из видов постовых служб. В конце секции описаны символы, которые не могут использоваться в именах пользователей или доменов.
Следующая секция - определение макросов sendmail:
######################
# Special macros #
######################
# SMTP initial login message
De$j Sendmail $v/$Z ready at $b
# UNIX initial From header format
DlFrom $g $d
# my name for error messages
DnMAILER-DAEMON
# delimiter (operator) characters
Do.:%@!^/[]
# format of a total name
Dq$?x$x <$g>$|$g$.
# Configuration version number
DZ8.6.6
В данной секции описаны сообщения, которые выдает sendmail при взаимодействии с другими транспортными агентами. Как видно из этого описания, определение макроса это не только присваивание значения, но и выполнение определенных действий. Наиболее интересное предложение из всех - предложение определяющее значение макроса q:
Dq$?x$x <$g>$|$g$.
Здесь описана условная подстановка значения. Все предложение можно описать следующей фразой:
«Если значение переменной x установлено, то: q = значение_x <значение_g>,
иначе: q=значение_g».
То же самое можно записать и по другому:
if(x!=NULL)
{
strcpy(q,x);
strcat(q, «<»);
strcat(q,g);
strcat(q, «>»);
{
else
{
strcpy(q,g);
}
В данном случае $? соответствует оператору if, $| - else, а $. - конец условного оператора.
Следующая секция - это определение опций:
###############
# Options #
###############
# strip message body to 7 bits on input?
#O7False
# Insist that the BIND name server be running to resolve names
OI
# deliver MIME-encapsulated error messages?
OjTrue
В данном случае приведен только фрагмент этой секции. Большинство параметров-общие для всех установок sendmail. Указанные же в листинге параметры являются принципиальными с точки зрения режимов работы sendmail. Первый параметр определяет тот факт, что по почте можно пересылать 7-битовую информацию. Согласно RFC-822 информация должна быть 7-битовая, но для передачи кириллицы это, значит, использовать кодирование, что абсолютно не приемлемо. Поэтому данный параметр должен быть закомментирован. В системах, где используется сервер доменных имен, опция I должна быть установлена, чтобы не было ошибок при идентификации доменов. Последний параметр не является принципиальным, но для более понятного представления его следует установить. Если почтовый клиент не поддерживает MIME, то данный параметр следует закомментировать.
Следующие две секции определяют уровень сообщений об ошибках и доверенных пользователей:
###########################
# Message precedences #
###########################
Pfirst-class=0
Pspecial-delivery=100
Plist=-30
Pbulk=-60
Pjunk=-100
#####################
# Trusted users #
#####################
Troot
Tdaemon
Tuucp
За этими двумя секциями следует секция описания полей заголовка почтового сообщения, который генерируется программой sendmail:
#########################
# Format of headers #
#########################
H?P?Return-Path: $g
HReceived: $?sfrom $s $.$?_($?s$|from $.$_) $.by $j ($v/$Z)$?r with $r$. id $i$?u for $u$.; $b
H?D?Resent-Date: $a
H?D?Date: $a
H?F?Resent-From: $q
H?F?From: $q
H?x?Full-Name: $x
HSubject:
# HPosted-Date: $a
# H?l?Received-Date: $b
H?M?Resent-Message-Id: <$t.$i@$j>
H?M?Message-Id: <$t.$i@$j>
Формат команд данной секции определяет, какие поля включаются в заголовок, а какие не включаются. Данная секция тесно связана с секцией определения программ рассылки почты. Если после «H» нет знака вопроса, то поле включается в заголовок сообщения для любой программы рассылки, если после «H» символ «?» присутствует, то в строке аргументов программы рассылки данный флаг должен быть определен для того, чтобы данное поле было включено в заголовок. Как следует из приведенного выше описания, всегда включаются только поля Recieved и Subject. Все перечисленные поля не являются обязательными полями заголовка.
Следующая секция - правила преобразования адресов. Но прежде чем обсуждать ее содержание, следует сказать, как и когда sendmail эти адреса преобразовывает.
|
|

Рис. 3.20. Порядок обработки адресов
Данная диаграмма представляет типовой набор блоков правил преобразования адресов. Как видно из рисунка, все адреса попадают на правила канонизации адресов (Rule Set 3). Если адреса достаточны для рассылки, то выполняется набор правил 0, в противном случае адреса анализируются на наличие в них доменной информации и, если данная информация отсутствует, то в блоке D она добавляется к адресу. Набор 1 применяется ко всем адресам отправителей, набор 2 применяется ко всем адресам получателей. Набор правил 4 - это выходной набор, который предназначен для преобразования адресов в формат программ рассылки. Ниже приведен фрагмент правил набора 3:
### Rulset 3 -- Name Canonicalization ###
S3
# handle null input (translate to <@> special case)
R$@ $@ <@>
# basic textual canonicalization -- note RFC733 heuristic here
R$*<$*>$*<$*>$* $2$3<$4>$5 strip multiple <> <>
R$*<$*<$+>$*>$* <$3>$5 2-level <> nesting
R$*<>$* $@ <@> MAIL FROM:<> case
R$*<$+>$* $2 basic RFC821/822 parsing
Не будем подробно разбирать все записи секции преобразования адресов, их очень много, поясним только сам механизм этого преобразования. Механизм основывается на применении так называемых token’ов и pattern’ов, образованных этими token’ами.
|
Pattern |
Значение |
|
$* |
пусто или любое количество token’ов |
|
$+ |
один или более token’ов |
|
$- |
точно один token |
|
$=x |
любое количество token’ов одного класса x |
|
$~x |
любое количество token’ов, не принадлежащих классу x |
|
$x |
все token’ы макро x |
Указанные паттерны используются в правой части правила. В левой части правила используются метасимволы, в которые эти паттерны отображаются.
|
Символ |
Значение |
|
$n |
Token номер n |
|
$[name$] |
Каноническое имя |
|
$>n |
Вызвать набор правил n |
|
$@ |
Завершить набор правил |
|
$: |
Завершить правило |
|
$#mailer$@host$:user |
образец вызова программы рассылки |
Приведем пример преобразования:
XPOL < @ xbm11 . BITNET >
$+ < @ $+ . BITNET >
$1 % $2 < @ $B >
XPOL % xbm11 < @ relay.kiae.su >
В этом примере правило преобразования выглядит следующим образом:
R$+<@$+.BITNET> $1%$2<@$B>
Речь идет о преобразовании адресов сообщений отправленных в BITNET.
Ниже приведен фрагмент правил набора 0, в котором определяется рассылка почты программами рассылки:
######################################
### Ruleset 0 -- Parse Address ###
######################################
S0
….
# handle local hacks
R$* $: $>98 $1
# short circuit local delivery so forwarded email works
R$+ < @ $=w . > $: $1 < @ $2 . @ $H > first try hub
R$+ < $+ @ $+ > $#local $: $1 yep ....
R$+ < $+ @ > $#local $: @ $1 nope, local address
# resolve remotely connected UUCP links (if any)
# resolve fake top level domains by forwarding to other hosts
R$*<@$+.BITNET.>$* $: $>95 < $B > $1 <@$2.BITNET.> $3 user@host.BITNET
# forward non-local UUCP traffic to our UUCP relay
R$*<@$*.UUCP.>$* $: $>95 < $Y > $1 <@$2.UUCP.> $3 uucp mail
# pass names that still have a host to a smarthost (if defined)
R$* < @ $* > $* $: $>95 < $S > $1 < @ $2 > $3 glue on smarthost name
# deal with other remote names
R$* < @$* > $* $#smtp $@ $2 $: $1 < @ $2 > $3 user@host.domain
…
За секцией преобразования адресов следует секция определения программ рассылки почты. В ней определяется локальная программа рассылки (mail), программа рассылки для выполнения (sh), и программа рассылки по SMTP.
##################################################
### Local and Program Mailer specification ###
##################################################
Mlocal, P=/usr/libexec/mail.local, F=lsDFMrmn, S=10, R=20/40,
A=mail -d $u
Mprog, P=/bin/sh, F=lsDFMeu, S=10, R=20/40, D=$z:/,
A=sh -c $u
S10
R<@> $n errors to mailer-daemon
R$+ $: $>40 $1
S20
R$+ < @ $* > $: $1 strip host part
S40
#####################################
### SMTP Mailer specification ###
#####################################
Msmtp, P=[IPC], F=mDFMuX, S=11/31, R=21, E=\r\n,
L=990, A=IPC $h
Mesmtp, P=[IPC], F=mDFMuXa, S=11/31, R=21, E=\r\n,
L=990, A=IPC $h
Mrelay, P= [IPC], F=mDFMuXa, S=11/31, R=61, E=\r\n,
L=2040, A=IPC $h
Затем идут правила определения локального преобразования адресов для конкретных программ рассылки, в частности набор правил S11.
# envelope sender and masquerading recipient rewriting
#
S11
R$+ $: $>51 $1 sender/recipient common
R$* :; <@> $@ $1 :; list:; special case
R$* $@ $>61 $1 qualify unqual'ed names
В секции программ рассылки мы в нашем примере не указали еще одну важную возможность - рассылку по протоколу UUCP:
Мuucp, P=/usr/bin/uux, F=DFMhuU, S=13, R=23, M=100000,
A=uux - -r -z -a$f -gC $h!rmail
Естественно, что правила преобразования адресов S13 и R23 должны быть описаны в файле настроек sendmail.
3.2.7.1. Тестирование Sendmail и способы запуска
При работе с программой Sendmail возникает ряд ситуаций, когда необходимо протестировать работу системы рассылки электронной почты. Чаще всего это связано с тем, что программа неаккуратно работает с сервисом доменных имен. Дело в том, что определение макросов w и j связано, скорее, с функционированием системы в среде NIS, а не BIND, что влечет за собой определенные проблемы при идентификации программы при работе по SMTP, например.
Собственно проблемы возникают между sendmail и resolver. Для их решения следует в файле конфигурации resolver не указывать имя домена, а в файле настроек sendmail сделать это явно.
Для проверки работы можно запустить sendmail с ключом -v:
quest:/usr/paul:\[1\]%sendmail -v paul@polyn.kiae.su
This is a test message.
.
paul@polyn.kiae.su... Connecting to cpuv1.net.kiae.su. (relay)...
220 cpuv1.net.kiae.su (RELCOM) ready ( Tue, 5 Nov 1996 11:46:12 +0300 )
>>> EHLO quest.net.kiae.su
500 Command unrecognized
>>> HELO quest.net.kiae.su
250 Hello quest.net.kiae.su, pleased to meet you
>>> MAIL From:<paul@quest.net.kiae.su>
250 <paul@quest.net.kiae.su>... Sender ok
>>> RCPT To:<paul@polyn.kiae.su>
250 <paul@polyn.kiae.su>... Recipient ok
>>> DATA
354 Enter mail, end with «.» on a line by itself
>>> .
250 Ok
paul@polyn.kiae.su... Sent (Ok)
Closing connection to cpuv1.net.kiae.su.
>>> QUIT
221 cpuv1.net.kiae.su closing connection
quest:/usr/paul:\[2\]%
Как видно из этого примера, система выдает полную трассу взаимодействия с удаленным хостом по протоколу SMTP.
Стандартный режим запуска sendmail - это запуск в виде процесса демона в момент начальной загрузки системы:
/usr/paul>sendmail -bd -q30m
Однако, надо всегда помнить, что перед запуском в режиме демона следует создать файл aliases:
/usr/paul>sendmail -bi
3.3.
Эмуляция удаленного терминала. Удаленный доступ к
ресурсам сети
Telnet - это одна из самых старых информационных технологий Internet. Она входит в число стандартов, которых насчитывается три десятка на полторы тысячи рекомендуемых официальных материалов сети, называемых RFC (Request For Comments).
Под telnet понимают триаду, состоящую из:
· telnet-интерфейса пользователя;
· telnetd-процесса;
· TELNET-протокола.
Эта триада обеспечивает описание и реализацию сетевого терминала для доступа к ресурсам удаленного компьютера.
В настоящее время существует достаточно большое количество программ - от Kermit до различного рода BBS (Belluten Board System), которые позволяют работать в режиме удаленного терминала, но ни одна из них не может сравниться с telnet по степени проработанности деталей и концепции реализации. Для того, чтобы оценить это, знакомство с telnet стоит начать с протокола.
3.3.1. Протокол Telnet
Telnet как протокол описан в RFC-854 (май, 1983 год). Его авторы J.Postel и J.Reynolds во введении к документу определили назначение telnet так:
«Назначение TELNET-протокола - дать общее описание, насколько это только возможно, двунаправленного, восьмибитового взаимодействия, главной целью которого является обеспечение стандартного метода взаимодействия терминального устройства и терминал-ориентированного процесса. При этом этот протокол может быть использован и для организации взаимодействий «терминал-терминал» (связь) и «процесс-процесс» (распределенные вычисления).»
Telnet строится как протокол приложения над транспортным протоколом TCP. В основу telnet положены три фундаментальные идеи:
· концепция сетевого виртуального терминала (Network Virtual Terminal) или NVT;
· принцип договорных опций (согласование параметров взаимодействия);
· симметрия связи «терминал-процесс».
При установке telnet-соединения программа, работающая с реальным терминальным устройством, и процесс обслуживания этой программы используют для обмена информацией спецификацию представления правил функционирования терминального устройства или Сетевой Виртуальный Терминал (Network Virtual Terminal). Для краткости будем обозначать эту спецификацию NVT. NVT - это стандартное описание наиболее широко используемых возможностей реальных физических терминальных устройств. NVT позволяет описать и преобразовать в стандартную форму способы отображения и ввода информации. Терминальная программа («user») и процесс («server»), работающий с ней, преобразовывают характеристики физических устройств в спецификацию NVT, что позволяет, с одной стороны, унифицировать характеристики физических устройств, а с другой обеспечить принцип совместимости устройств с разными возможностями. Характеристики диалога диктуются устройством с меньшими возможностями.
Если взаимодействие осуществляется по принципу «терминал-терминал» или «процесс-процесс», то «user» - это сторона, инициирующая соединение, а «server» - пассивная сторона.
Принцип договорных опций или команд позволяет согласовать возможности представления информации на терминальных устройствах. NVT - это минимально необходимый набор параметров, который позволяет работать по telnet даже самым допотопным устройствам, реальные современные устройства обладают гораздо большими возможностями представления информации. Принцип договорных команд позволяет использовать эти возможности. Например, NVT является терминалом, который не может использовать функции управления курсором, а реальный терминал, с которого осуществляется работа, умеет это делать. Используя команды договора, терминальная программа предлагает обслуживающему процессу использовать Esc-последовательности для управления выводом информации. Получив такую команду процесс начинает вставлять управляющие последовательности в данные, предназначенные для отображения.
Симметрия взаимодействия по протоколу telnet позволяет втечение одной сессии программе-«user» и программе-«server» меняться местами. Это принципиально отличает взаимодействие в рамках telnet от традиционной схемы «клиент-сервер». Симметрия взаимодействия тесно связана с процессом согласования формы обмена данными между участниками telnet-соединения. Когда речь идет о работе на удаленной машине в режиме терминала, то возможности ввода и отображения информации определяются только конкретным физическим терминалом и договорной процесс сводится к заказу терминальной программой характеристик этого терминала. Гораздо сложнее обстоит дело, когда речь идет об обмене информацией между двумя терминальными программами в режиме «терминал-терминал». В этом случае каждая из сторон может выступать инициатором изменения принципов представления информации и здесь проявляется еще одна особенность протокола telnet. Протокол не использует принцип «запрос-подтверждение», а применяет принцип «прямого действия». Это значит, что если терминальная программа хочет расширить возможности представления информации, то она делает это (например, вставляет в информационный поток Esc-последовательности), если в ответ она получает информацию в новом представлении, то это означает, что попытка удалась, в противном случае происходит возврат к стандарту NVT.
Обычно процесс согласования форм представления информации происходит в начальный момент организации telnet-соединения. Каждый из процессов старается установить максимально возможные параметры сеанса. Однако эти параметры могут быть изменены и позже, в процессе взаимодействия (например, после запуска прикладной программы).
В Unix-системах параметры терминалов обычно описаны в базе данных описания терминалов termcap. При инициировании telnet-соединения обычно именно эти параметры используются в процессе согласования формы представления данных. При этом из одной системы в другую обычно передается значение переменной окружения TERM. Если для этого значения переменной TERM имеются одинаковые описания в termcap, то проблем с представлением информации обычно не бывает; если терминал, заказанный в TERM, не определен, то берется стандартный терминал системы. При этом не все функции этого терминала будут задействованы. В процессе договора останутся только те, которые поддерживаются на обоих концах соединения. Часто можно столкнуться с ситуацией, когда значения переменных TERM на локальной и удаленной машинах совпадают, а информация на экране отображается не так, как этого бы хотелось. Скорее всего, это вызвано различиями в описании данного устройства в базе данных termcap.
Сетевой виртуальный терминал (NVT). Концепция сетевого виртуального терминала позволяет обеспечить доступ к ресурсам удаленной машины с любого терминального устройства. Под терминальным устройством понимают любую комбинацию физических устройств, позволяющих вводить и отображать информацию. Для тех, кто знаком с универсальными машинами серии EC, такое определение терминала не является новым: в момент загрузки системы можно было назначить составную консоль, в которую могли входить устройство ввода с перфокарт и алфавитно-цифровое печатающее устройство (АЦПУ). В более ранних вычислительных комплексах такими терминалами могли быть системная печать и устройство чтения перфоленты (как на МИНСК-22) или телетайп (как на М-6000). Понятно, что за таким понятием терминала стоит требование устойчивости системы, которое было основополагающим для проекта ARPA.
В протоколе TELNET NVT определен как «двунаправленное символьное устройство, состоящее из принтера и клавиатуры». Принтер предназначен для отображения приходящей по сети информации, а клавиатура - для ввода данных, передаваемых по сети и, если включен режим «echo», вывода их на принтер. По умолчанию предполагается, что для обмена информацией используется 7-битовый US ASCII, каждый символ которого закодирован в 8-битовое поле. Любое преобразование символов является расширением стандарта NVT.
NVT предполагается буферизованным устройством. Это означает, что данные, вводимые с клавиатуры, не посылаются сразу по сети, а собираются в пакеты, которые отправляются либо по мере заполнения буфера, либо по специальной команде. Такая организация NVT призвана с одной стороны минимизировать сетевой трафик, а с другой обеспечить совместимость с реальными буферизованными терминалами. Например, таковым и являются терминалы ЕС-7920, из-за которых можно было потерять целый экран информации в случае зависания машины.
В моменты окончания печати на принтере NVT или отсутствия символов в буфере клавиатуры по сети должна посылаться специальная команда GA (Go Ahead). Смысл этой команды заключается в следующем: в реальных компьютерах линия "терминал-процесс" находится под управлением либо терминальной программы (ввод данных), либо печатающей программы. После выполнения своей функции каждая из них возвращает управление и освобождает линию. Обычно это происходит при работе с полудуплексными устройствами, такими как IBM-2741. Для того, чтобы протокол позволял работать и с этими устройствами, введен сигнал GA.
Остановимся более подробно на понятиях принтера и клавиатуры в концепции NVT.
Принтер имеет неограниченные ширину и длину страницы и может отображать все символы US ASCII (коды с 32 - 127), расширенный набор символов (коды с 128 - 255), а также распознает управляющие коды (с 0 - 31 и 127). Некоторые из них имеют специальные значения (таблица 3.1).
Таблица 3.1.
Обязательные коды
|
Название кода |
Код |
Значение |
|
NULL |
0 |
Нет операции |
|
Перевод строки |
10 |
Переход на другую строку c сохранением текущей позиции в строке |
|
Возврат
каретки |
13 |
Устанавливает в
качестве текущей первую |
Рекомендованные коды
|
Название кода |
Код |
Значение |
|
Звонок (BEL) |
7 |
Звуковой сигнал |
|
Сдвиг на одну позицию назад(BACK SPACE) |
8 |
Перемещает
каретку на одну позицию назад в |
|
Горизонтальная
табуляция |
9 |
Перемещение к
следующей позиции |
|
Вертикальная табуляция
|
11 |
Перемещение
курсора к следующей позиции |
|
Прогон страницы |
12 |
Переход к новой странице |
Клавиатура имеет возможность ввода всех символов US ASCII. Кроме этого клавиатура может генерировать специальные стандартные функции управления терминалом. Стандарт telnet определяет пять стандартных функций управления терминалом. Вообще говоря, эти функции могут или присутствовать на реальном терминале, и тогда они должны представляться в стандартной форме команды, или отсутствовать, и тогда заменяться командой NO (No-Оperation).
Команда «Прервать процесс» (Interrupt Process - IP). Данная команда реализует стандартный для многих систем механизм прерывания процесса выполнения задачи пользователя (Cntrl+C в Unix-системах или Cntrl+Break в MS-DOS). Следует заметить, что команда IP может быть использована и другим протоколом прикладного уровня, который может использовать telnet.
Команда «Прервать процесс выдачи» (Abort Output - AO). Многие системы позволяют остановить процесс, выдающий информацию на экран. Здесь следует понять отличие данной команды от IP. При выполнении IP прерывается выполнение текущего процесса пользователя, но не происходит очистка буфера вывода, т.е. процесс может быть остановлен, а буфер вывода будет продолжать передаваться на экран. Обычно это происходит при взаимодействии по медленным линиям связи. Пользователи персональных компьютеров прекрасно знакомы с этой особенностью буферизованных устройств, когда возникают проблемы с остановкой печати: пользователь уже прервал печать и очистил по команде print /t буфер печати на компьютере, а лазерный принтер продолжает изводить бумагу лист за листом. Это типичный пример непродуманного подхода к процессу управления терминальным устройством, который характерен для разработчиков MS-DOS. Для того, чтобы избежать подобного казуса и существует команда AO. Реально проверить ее может любой пользователь медленного телефонного канала связи - для этого можно запустить команду more для просмотра большого файла, после этого по команде Cntrl+C прервать ее - выдача информации на экран будет продолжаться, и после этого выдать из командной строки telnet команду AO, что прервет выдачу.
Команда «Ты еще здесь?» (Are You There - AYT). Назначение этой команды - дать возможность пользователю убедиться, что в процессе работы по медленным линиям он не потерял связи с удаленной машиной. В силу буферизации ввода и вывода может оказаться, что пользователь может вводить данные, а связь с удаленной машиной уже потеряна. В стандартной ситуации этот факт будет обнаружен только после нажатия клавиши «Enter». Telnet дает возможность убедиться в наличии связи в любой момент времени.
Команда «Удалить символ» (Erase Character - EC). Многие системы обеспечивают возможность редактирования командной строки путем введения так называемых символов "забой" или удалением последнего напечатанного символа на устройстве отображения. В любом случае последний введенный в буфер символ удаляется. Команда EC призвана стандартизировать реализацию этого механизма.
Команда «Удалить строку» (Erase Line - EL). Данная команда аналогична EC, но удаляет целую строку ввода. Обычно выполнение этой команды приводит к очистке буфера ввода, т.к. при работе в режиме командной строки строка ввода только одна.
Синхронизация. В локальных системах синхронизация работы процессов обычно реализуются через механизм прерываний или, как в Unix, механизм сигналов. Это означает, что система имеет возможность вмешаться в процесс обработки данных практически в любой момент времени. В контексте взаимодействия программы обработки данных и терминальной программы это означает возможность прервать программу обработки или очистить один из буферов с/без отображением(я) информации из него. Именно к этому типу взаимодействия относятся команды IP и AO. Однако в сети сделать это не так просто, как в локальной вычислительной среде. Данные при передаче между машинами буферизуются, и обмен происходит пакетами. Если бы команда «Прервать процесс» просто вставлялась в последовательность символов в пакете, то это приводило бы к эффекту запаздывания, т.е. после ввода пользователем команды «прервать процесс», а процесс будет продолжать выполняться пока не доберется до идентификатора команды IP в полученном пакете. Результат - бесполезно потраченное время. Поэтому механизм синхронизации telnet состоит из использования специальной формы пакета TCP (TCP Urgent notification) и команды DATA MARK (DM). Специальная форма TCP пакета используется для изменения процедуры обработки пакетов. Обычно пакет обрабатывается, начиная с первого символа пакета последовательно. В случае специальной формы пакета сначала происходит поиск «интересных» сигналов, а уже потом производится обработка пакета по стандартному сценарию. Команда DM обычно замыкает пакет и обозначает конец специальной обработки. Если TCP-пакет содержит специальные символы до DM, то порядок специальной обработки отменяется, а DM воспринимается как команда No- Operation (NO). Если специальные символы не найдены, то порядок специальной обработки пакетов продолжается. В этом смысле интересными сигналами или символами являются стандартные команды telnet IP, AO, AYT или другие команды, требующие немедленного выполнения.
Команды telnet имеют свой формат. Команда - это 2-байтовая последовательность, состоящая из Esc-символа (255) IAC (Interpret as Command) и кода команды (240-255). Команды, связанные с процедурой согласования параметров сеанса, имеют 3-х байтовый формат: третий байт - ссылка на устанавливаемую опцию.
Стандартным портом TCP для telnet является порт 23.
3.3.2. Интерфейс пользователя (telnet) и демон (telnetd)
Для того, чтобы протокол стал реально шествующим стандартом, нужна программа, его реализующая, такими программами являются telnet и telnetd в Unix-системах.
3.3.2.1. Программа-сервер (telnetd)
Telnetd - это сервер, который обслуживает протокол TELNET. Обычно telnetd запускается через сервис Internet (inetd), в некоторых системах может быть запущен и вручную. Telnetd обслуживает TCP-порт 23, но может быть запущен и на другой порт.
Принцип работы сервера заключается в том, что он «слушает» порт TCP. В случае поступления запроса на обслуживание, telnetd назначает каждому удаленному клиенту псевдотерминал (pty) в качестве стандартного файла ввода (stdin), стандартного файла вывода (stdout) и стандартного файла ошибок (stderr).
При установке взаимодействия с удаленным клиентом telnetd обменивается командами настройки (эхо, обмен двоичной информацией, тип терминала, скорость обмена, переменные окружения).
Надо сказать, что telnetd реализует протокол TELNET частично. При работе по telnet никогда не используется сигнал Go Ahead (GA). Двоичный режим передачи данных можно реально использовать только для одинаковых операционных сред.
3.3.2.2. Программа-клиент (telnet)
Telnet - это интерфейс пользователя для работы по протоколу TELNET. Программа работает в двух режимах: в режиме командной строки (command mode) и в режиме удаленного терминала (input mode).
При работе в режиме удаленного терминала telnet позволяет работать с буферизацией (line-by-line) или без нее (character-at-a-time). При работе без буферизации каждый введенный символ немедленно отправляется на удаленную машину, откуда приходит «эхо». При буферизованном обмене введенные символы накапливаются в локальном буфере и отправляются на удаленную машину пакетом. «Эхо» в последнем случае также локальное.
Для переключения между режимом командной строки и режимом терминала используют последовательность Ctrl+], которая может быть изменена командами telnet (таблица 3.2).
Таблица 3.2.
Основные команды режима командной строки telnet
|
Команда |
Назначение |
|
open host [port] |
Начать telnet-сессию с машиной host по порту port. Адрес машины можно задавать как в форме IP-адреса, так и в форме доменного адреса |
|
close |
Завершить telnet-сессию и вернуться в командный режим. Однако в некоторых системах, если telnet был вызван с аргументом, close приведет к завершению работы telnet |
|
quit |
Завершить работу telnet |
|
z |
«Заморозить» telnet сессию и перейти в режим интерпретатора команд локальной системы. Из этого режима можно выйти по команде Exit |
|
mode type |
Если значение type line, то используется буферизованный обмен данными, если character - то обмен не буферизованный |
|
? [command]
|
Список команд или описание конкретной команды |
|
send argument |
Данная команда используется для ввода команд и сигналов протокола TELNET, которые указываются в качестве аргумента. Например: send ao - посылает команду прервать выдачу на принтер NVT |
Программу telnet можно использовать не только для работы по протоколу TELNET, но и для тестирования других протоколов, например SMTP:
telnet host.domain.org 25
После установки соединения можно обмениваться командами протокола SMTP c сервером этого протокола.
В настоящее время часто доступ к удаленной машине Internet осуществляется не прямо, а через промежуточный сервер. Например, пользователь использует программу дозвона (dial-in) на персональном компьютере для доступа к Unix-машине, а затем telnet для доступа к другому компьютеру, подключенному к Internet. В этом случае также возможны несоответствия. Например, программа term90 из набора Norton Commander имеет экран не 24´80, а только 23´80. При эмуляции терминала vt100 это следует учитывать, т.к. в базе данных termcap для этого терминала определены значения 24´80. Дело в том, что при доступе по telnet две Unix-машины согласовывают свои возможности, а DOS-компьютер из этого процесса исключен. Для обеспечения правильной работы в базе данных termcap следует прописать терминал для такого доступа.
3.3.3. Организация модемных пулов,
настройка оборудования.
Квоты пользователей
При обсуждении вопроса о доступе в режиме удаленного терминала нельзя обойти возможность доступа к системе по телефону, с использованием модема. Это совершенно другая, отличная от telnet технология. При обсуждении вопросов доступа к Internet в режиме Dial-IP уже обсуждались вопросы, связанные с тем, что базовым методом доступа для режима IP является режим удаленного терминала, когда пользователь получает удаленный терминал (физически удаленный, но работающий точно также, как и локальный). В этом случае пользователь получает доступ не на виртуальные терминалы типа /dev/ttypX, а к устройствам типа /dev/ttydX, которые обычно используются для подключения модемов.
При подключении модема к компьютеру следует настроить терминал для работы с модемом, т.е. создать устройство /dev/ttydX, установить скорость обмена между портом компьютера и модемом, «залочить» модем.
Для создания устройства можно использовать скрипт MAKEDEV или команду mknode. В разных системах это делается по-разному. Так в SCO или HP-UX устройство можно создать из интерфейса системного администратора.
Сцепление порта и устройства осуществляется через файл, выполняющийся в момент начальной загрузки в системе FreeBSD, например это делается через файл /etc/ttys:
# @(#)ttys 5.1 (Berkeley) 4/17/89
#
# name getty type status comments
#
# This entry needed for asking password when init goes to single-user mode
# If you want to be asked for password, change "secure" to "insecure" here
console none unknown off secure
#
ttyv0 "/usr/libexec/getty Pc" cons25 on secure
# Virtual terminals
ttyv1 "/usr/libexec/getty Pc" cons25 on secure
ttyv2 "/usr/libexec/getty Pc" cons25 on secure
ttyv3 "/usr/libexec/getty Pc" cons25 off secure
# Serial terminals
ttyd0 "/usr/libexec/getty std.38400" dialup on secure
ttyd1 "/usr/libexec/getty std.9600" unknown off secure
ttyd2 "/usr/libexec/getty std.9600" unknown off secure
ttyd3 "/usr/libexec/getty std.9600" unknown off secure
# Pseudo terminals
ttyp0 none network
ttyp1 none network
ttyp2 none network
ttyp3 none network
В данном случае строка соответствующая терминалу ttyd0, используется для подключения модема. При этом на порте установлена скорость 38400, что позволяет подключать высокоскоростные модемы. Сам тип терминала dial-in описан в фале termcap. Скорость на модеме устанавливается согласно описаниям из файла gettytypes. Однако все это справедливо для систем a la BSD системах System 5 файлы настроек будут другие.
«Залочить» модем это значит, что скорость передачи данных между модемом и портом постоянная и не зависит от скорости на линии. Обычно схему подключения модема к компьютеру представляют в следующем виде:

Рис. 3.21. Взаимодействие модема и последовательного порта
Скорость на линии, обычно, устанавливается согласно возможностям модема. Большинство модемов способно само договариваться о скорости передачи данных. При этом, обычно используются протоколы коррекции ошибок и сжатие данных. Таким образом, модем занимается преобразованием данных, что естественно требует определенного времени. Если применяется компрессия, то в порт будет передаваться байтов больше, чем их передается по линии, следовательно, скорость обмена данными между модемом и компьютером должна быть больше скорости обмена данными между модемами.
На схеме также изображено, так называемое «жесткое» управление соединением (Hardware Hadshaking), которое должно быть выбрано для управления модемом при его настройках. Принимающий вызовы модем должен быть сконфигурирован таким образом, чтобы он сам снимал трубку (ats0=5). Если кроме приема звонков от удаленных компьютеров телефон используется еще и как обычный телефон, то значение регистра s0 надо установить побольше.
Кроме того, при работе с Unix следует принять во внимание тот факт, что некоторые системы работают с 7-битовыми терминалами. В этом случае при настройке программ пользователей в поле «Data Langth» следует указывать значение 7, а в поле Parity указывают Even.
Допуск пользователей к ресурсам системы в режиме удаленного терминала заставляет задуматься о квотировании ресурсов для каждого пользователя. Квотированию подлежат:
· время использования процессора;
· размер используемого дискового пространства;
· время доступа к системе;
· каналы доступа к системе.
С точки зрения сетевого администрирования, все эти параметры подлежат если не ограничению, то строгому учету.
Время использования машины связано с тем, что при анализе активности пользователя может оказаться, что система используется третьим лицом, а не реальным пользователем для доступа к ресурсам сети. При этом программы подбора паролей «поедают» достаточно много времени процессора.
Размер используемого дискового пространства влияет на возможность пользователя получать и хранить информацию из сети, например по FTP, а также на размер принимаемых почтовых сообщений.
Время доступа к системе определяет возможность доступа пользователя по времени суток. Можно запретить работать с удаленных терминалов в рабочее время, когда телефон нужен для других целей.
Ограничение доступа к системе через виртуальные терминалы и удаленные терминалы должно служить повышению безопасности всей сети в целом.
3.4. Обмен файлами. Служба архивов FTP
FTP-архивы являются одним из основных информационных ресурсов Internet. Фактически, это распределенный депозитарий текстов, программ, фильмов, фотографий, аудио записей и прочей информации, хранящейся в виде файлов на различных компьютерах во всем мире.
3.4.1. Типы информационных ресурсов
Информация в FTP-архивах разделена на три категории:
· Защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем. К этому виду ресурсов относятся коммерческие архивы (например, коммерческие версии программ в архивах ftp.microsoft.com или ftp.bsdi.com), закрытые национальные и международные некоммерческие ресурсы (например, работы по международным проектам CES или IAEA), частная некоммерческая информация со специальными режимами доступа (частные благотворительные фонды, например).
· Информационные ресурсы ограниченного использования, к которым относятся, например, программы класса shareware (Trumpet Winsock, Atis Mail, Netscape, и т.п.). В данный класс могут входить ресурсы ограниченного времени использования (текущая версия Netscape перестанет работать в июне, если только кто-то не сломает защиту) или ограниченного времени действия, т.е. пользователь может использовать текущую версию на свой страх и риск, но никто не будет оказывать ему поддержку.
· Свободно распространяемые информационные ресурсы или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это может быть документация, программы или что-либо еще. Наиболее известными свободно распространяемыми программами являются программы проекта GNU Free Software Foundation. Следует отметить, что свободно распространяемое программное обеспечение не имеет сертификата качества, но, как правило, его разработчики открыты для обмена опытом.
Из выше перечисленных ресурсов наиболее интересными, по понятным причинам, являются две последних категории, которые, как правило, оформлены в виде FTP-архивов.
Технология FTP была разработана в рамках проекта ARPA и предназначена для обмена большими объемами информации между машинами с различной архитектурой. Главным в проекте было обеспечение надежной передачи и поэтому с современной точки зрения FTP кажется перегруженным излишними редко используемыми возможностями. Стержень технологии составляет FTP-протокол.
3.4.2. Протокол FTP
FTP (File Transfer Protocol или «Протокол Передачи Файлов») - один из старейших протоколов в Internet и входит в его стандарты. Обмен данными в FTP проходит по TCP-каналу. Построен обмен по технологии «клиент-сервер». На рисунке 3.22 изображена модель протокола.
В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора пользователя средствами.
|
|
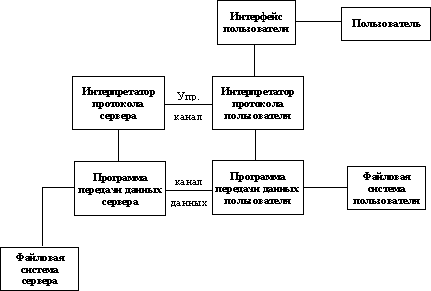
Рис. 3.22. Диаграмма протокола FTP
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с согласованными в сессии управления параметрами.
Канал данных устанавливается для того же host’а, что и канал управления, через который ведется настройка канала данных. Канал данных может быть использован как для приема, так и для передачи данных.
Возможна ситуация, когда данные могут передаваться на третью машину. В этом случае пользователь организует канал управления с двумя серверами и организует прямой канал данных между ними. Команды управления идут через пользователя, а данные напрямую между серверами (рисунок 3.23).
|
|
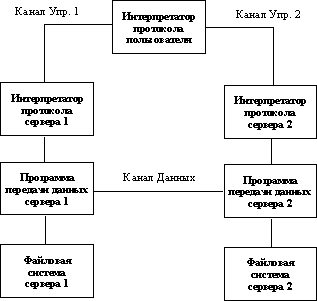
Рис. 3.23. Соединение с двумя разными серверами и передача данных между ними
Канал управления должен быть открыт при передаче данных между машинами. В случае его закрытия передача данных прекращается.
Режимы обмена данными
В протоколе большое внимание уделяется различным способам обмена данными между машинами различных архитектур. Действительно, чего только нет в Internet, от персоналок и Mac’ов до суперкомпьютеров. Все они имеют различную длину слова и многие различный порядок битов в слове. Кроме этого, различные файловые системы работают с разной организацией данных, которая выражается в понятии метода доступа.
В общем случае, с точки зрения FTP, обмен может быть поточный или блоковый, с кодировкой в промежуточные форматы или без нее, текстовый или двоичный. При текстовом обмене все данные преобразуются в ASCII и в этом виде передаются по сети. Исключение составляют только данные IBM mainframe, которые по умолчанию передаются в EBCDIC, если обе взаимодействующие машины IBM. Двоичные данные передаются последовательностью битов или подвергаются определенным в процессе сеанса управления преобразованиям. Обычно, при поточной передаче данных за одну сессию передается один файл данных, при блоковом способе за одну сессию можно передать несколько файлов.
Описав в общих чертах протокол обмена, можно перейти к описанию средств обмена по протоколу FTP. Практически для любой платформы и операционной cреды существуют как серверы, так и клиенты. Ниже описываются стандартные сервер и клиент Unix-подобных систем.
3.4.3. Сервер протокола - программа ftpd
Команда ftpd предназначена для обслуживания запросов на обмен информацией по протоколу FTP. Сервер обычно стартует в момент загрузки компьютера. Синтаксис запуска сервера следующий:
ftpd [-d] [-1] [-t timeout]
d - опция отладки;
1 - опция автоматической идентификации пользователя;
t - время пассивного ожидания команд пользователя.
Каждый сервер имеет свое описание команд, которое можно получить по команде help. Автоматическая идентификация пользователей осуществляется при помощи файла /etc/passwd. Пароль пользователя не должен быть пустым.
Существует специальный файл, в котором содержатся запрещенные пользователи, т.е. те, кому обслуживание по протоколу FTP запрещено. Возможен вход в архив по идентификатору пользователя anonymous или ftp. В этом случае сервер принимает меры по ограничению доступа к ресурсам компьютера для данного пользователя. Обычно для таких пользователей создается специальная директория ftp, в которой размещают каталоги bin, etc и pub. В каталоге bin размещаются команды, разрешенные для использования, а в каталоге pub собственно сами файлы. Каталог etc закрыт для просмотра пользователем и в нем размещены файлы идентификации пользователей.
В ряде случаев в директории pub создают каталог incoming. Этот каталог предназначен для того, чтобы пользователь мог записать в этот каталог свои программы или любые другие файлы. Однако, это довольно небезобидная, с точки зрения безопасности, операция.
В директорию bin обычно записывается только одна команда ls. Данная команда позволяет выполнять просмотр текущей директории. Согласно правилам, анонимный пользователь должен иметь возможность выполнять только те команды, которые размещены в этой директории. Однако, в большинстве систем анонимный пользователь выполняет гораздо больший набор команд, при этом эти команды берутся из стандартных директорий системы. Способность этого пользователя создавать директории, удалять файлы и т.п. будет зависеть от прав, которые установлены администратором для той ветви, файловой системы, в которой располагается файловый архив FTP. Так, например, в Windows NT можно так назначить права, что при входе пользователя с консоли он сможет получить доступ к системе, а при доступе к своему архиву FTP пользователь таких прав не получает, точнее пользователь нормально идентифицируется и проходит аутентификацию, но после этого получает сообщение, что не обладает нужными правами для доступа к своей домашней директории. При этом данная проблема в рамках программ настроек Internet Information Services не решается. Приходится использовать стандартные средства Windows, определяющие эти права.
Другую опасность для системы представляют ссылки. Многие администраторы полагают, что взлом системы - это ситуация, когда злоумышленник проник в систему, однако это не так. Например, в классификации CERT тяжелый взлом - это, в том числе и выявление структуры файловой системы. В этом случае, атакующий получает информацию о предмете атаки и может сосредоточить свои усилия на каком-то отдельном фрагменте системы.
Если в директорию etc не скопировать файл passwd, то никто не сможет получить доступ к данным FTP-архива. Однако, часто копируют настоящий файл паролей. Этого делать не следует. Во всяком случае, следует убедиться в том, что поле паролей в записях описания пользователей должно быть пустым. Клиент FTP только проверяет наличие пользователя и наличие у него пароля, а идентификация проводится стандартным для системы способом через программу login.
Ниже приведена структура корня FTP-архива (рисунок 3.24).
|
|

Рис. 3.24. Структура ftp-архива
3.5. Администрирование серверов World Wide Web
Распределенная информационная гипертекстовая система World Wide Web является одним из самых популярных, если не самым популярным, ресурсом Internet. Простота поддержки баз данных Web и проста использования программ доступа к ресурсам Web привели к тому, что скорость установки Web-серверов такова, что их количество удваивается каждые 62 дня. Интегрированные мультипротокольные интерфейсы World Wide Web объединяют в себе не только средство просмотра Web, но и доступ к FTP-архивам и средство работы с электронной почтой.
Практически, мультипротокольные программы типа Netscape Navigator, Internet Explorer, Arena и т.п. стали стандартным интерфейсом доступа в Сеть. Кроме этого, для разработки самих страниц Web не требуется какого-то изощренного программного обеспечения. Достаточно иметь обычный текстовый редактор и уже можно разрабатывать не только информационные страницы, но и стандартные формы ввода информации. Все это подвигло разработчиков программного обеспечения заговорить о технологии World Wide Web, как о технологии, способной удовлетворить множеству требований разнообразных задач, которые встречаются в организации информационной системы корпорации. После того, как Sun объявила о возможности использования в World Wide Web мобильных кодов Java, то последние сомнения о возможности организации корпоративного информационного сервиса на основе технологии World Wide Web отпали, и вся концепция получила название Intranet.
Разберем историю проекта, архитектуру программного обеспечения и протоколы World Wide Web более подробно.
3.5.1. История развития, отцы-основатели, современное состояние
Что же предлагал Тим Бернерс-Ли в 1989 году, и что из этого получилось? В «World Wide Web: Proposal for HyperText Project», направленных руководству CERN, он считал, что информационная система, построенная на принципах гипертекста, должна объединить все множество информационных ресурсов CERN, которое состояло из базы данных отчетов, компьютерной документации, списков почтовых адресов, информационной реферативной системы, наборов данных результатов экспериментов и т.п. Гипертекстовая технология должна была позволить легко «перепрыгивать» из одного документа в другой.
Проект делился на две фазы, или, как у нас принято говорить, очереди. Первая очередь (продолжительностью в три месяца) должна была показать жизнеспособность идеи проекта. Втечение этого этапа работ предполагалось разработать программы-интерфейсы для работы в алфавитно-цифровом режиме и программу-интерфейс для Macintosh и NeXT, работающую в графическом режиме, сервер для доступа к ресурсам Usenet, сервер для доступа к информационно-поисковой системе CERN, гипертекстовый сервер и программу-шлюз между Internet и DECnet.
В последующие три месяца (вторая очередь) предполагалось разработать средства подготовки гипертекстовых документов, полноэкранную программу просмотра для VM/XA, X-Window-интерфейс и систему автоматической нотификации просматриваемых материалов.
Кроме программного обеспечения предполагалось разработать общий протокол обмена информацией в сети, метод отображения текста на экране компьютера, создать набор базовых документов, иллюстрирующих работу системы, который мог бы пополняться за счет документов пользователей, обеспечить поиск по ключевым словам в этом наборе документов.
Любопытно, что из проекта в обязательном порядке исключались всякие исследования, связанные с конвертированием информации из форматов каких-либо редакторов в форматы данных системы, возможностью работы с видео- и аудио-информацией, все работы, связанные с защитой информации от несанкционированного доступа.
На всю эту полугодовую работу автор просил 4-х разработчиков (software designers) и одного программиста, и для каждого из них отдельное рабочее место (компьютер того типа, для которого разработчик будет писать программное обеспечение). Кроме этого требовалось приобрести коммерческое программное обеспечение, которое было бы полезно при разработке системы (Guide, KMS, FrameMaker).
Как видно, запросы были невелики, и в октябре 1990 года проект стартовал. Уже в ноябре был реализован прототип системы для NeXT, к рождеству «задышал» line mode browser, разработке которого придавалось особое значение, т.к. он открывал доступ к системе через telnet, а в марте его можно было уже демонстрировать. Через год в Internet был установлен анонимный telnet для доступа в систему. Первое сообщение об WWW было послано в телеконференции: alt.hypertext, com.sys.next, comp.text.sgml и comp.mail. multi-media, в августе 1991 года.
По современным меркам результаты, которых достигли разработчики к 1991 году, выглядят довольно скромно, если не вдаваться в суть работы и ограничиться только внешним ее проявлением. Сообщество Internet получило еще одну программу, работающую в режиме командной строки. Прошло еще целых полтора года до того момента, когда программа Mosaic, разработанная Марком Андресеном (Mark Andressen) из Национального Центра Суперкомпьютерных Приложений (NCSA), и построенная на принципах WWW, обеспечили бурный рост популярности «паутины» в Internet.
NCSA начала проект по разработке интерфейса в World Wide Web месяц спустя после объявления CERN. Одна из задач NCSA - это разработка доступных некоммерческих программ, с другой стороны NCSA изучает новые технологии на предмет их коммерческого применения в будущем. World Wide Web безусловно подходила под эти два параметра. Кроме того, спецификации WWW производили впечатление добротно выполненной академической работы с обзором литературы по данному вопросу, обилием ссылок и обоснованностью принятых решений. Мультипротокольный переносимый интерфейс в WWW, создание которого начала Группа Разработки Программного Обеспечения NCSA, был назван Mosaic. Пробная версия программы была закончена в первой половине 1993 года, а в августе 1993 была анонсирована альфа-версия для Internet.
Следует отметить, что сам проект Mosaic внес огромный вклад в развитие спецификаций World Wide Web, существенно обогатив различные компоненты системы. Разработчики Mosaic ввели в стандарты WWW большое количество новшеств. Агрессивная политика команды NCSA привела к тому, что многие программы-интерфейсы, разработанные в рамках ранних стандартов, постепенно стали отмирать, не выдержав конкуренции. Для самого NCSA это закончилось тем, что лидер команды, Марк Андресен, покинул в марте 1994 года NCSA и организовал коммерческую корпорацию Netscape. C этого момента начался новый этап борьбы, но теперь между старыми коллегами. Netscape активно навязывает свои стандарты, что приводит к тому, что документы, подготовленные с расширениями Netscape неправильно отображаются Mosaic, а документы с расширенными возможностями NCSA могут вообще не отображаться Netscape.
Следует отметить, что проект NCSA преследовал большие цели, нежели просто программу-интерфейс в WWW. С самого начала Mosaic разрабатывалась как программа с возможностями доступа к ресурсам Internet посредством различных протоколов, в число которых входили FTP, telnet, NNTP, SMTP. Однако вначале предполагалось, что делаться это будет за счет вызова внешних, относительно Mosaic, программ. В настоящее время Netscape сам поддерживает, кроме перечисленных, протоколы доступа в Gopher и Wais. Последнее позволяет использовать Netscape, впрочем, как и Mosaic, для работы вне рамок World Wide Web.
Mosaic на некоторое время затмила разработки CERN. Однако эта группа имела хорошо продуманную стратегию развития системы, которая включала в себя следующие основные моменты: разработка и поддержка стандартов спецификаций системы, разработка библиотеки свободно распространяемых мобильных кодов системы, полного комплекта средств, обеспечивающих разработку и реализацию компонентов системы на любом типе компьютера в сети, подготовка набора справочных и демонстрационных документов о состоянии сети и направлениях ее развития. Данная стратегия позволила распространять программное обеспечение, разработанное в рамках проекта в Internet, а наличие line mode broser’а позволила открыть возможности WWW для огромной аудитории пользователей алфавитно-цифровых устройств, подключенных в сеть. Некоторое время NCSA лидировала и по числу установок серверов, однако в настоящее время CERN обеспечил себе паритет и в этой области. Правда, и здесь не обошлось без «накладок». Так, форматы файлов конфигурации программы imagemap, обеспечивающей работу с графическими гипертекстовыми ссылками, у этих двух серверов различны.
Другим показателем успешного развития работ является образование W3-консорциума. Консорциум образован после подписания соглашения между Масачусетским Технологическим Институтом (MIT, USA) и Национальным Институтом Информатики и Автоматики (INRA, France) c согласия CERN. Если не вдаваться в подробности, то смысл этого соглашения заключается в том, что все программное обеспечение аккумулируется в MIT, участники имеют право copyright на все разработанное программное обеспечение и спецификации. Программное обеспечение распространяется свободно. За представителем MIT закрепляется должность директора, а за представителем INRA - должность зам. директора. Взносы полноправных участников W3C составляют $50.000 в год, а ассоциированных членов - $5.000 в год, соглашение заключено на три года начиная с 1 октября 1994 года. Любопытно, что организации с годовым оборотом, превышающим $50 миллионов, обязаны регистрироваться как полноправные члены, и что консорциум надеется получать прибыль, превышающую $1,5 миллиона, т.к. предусмотрен порядок использования средств сверх этой суммы. Средства до этого предела используются на развитие системы и исследования.
Образование Netscape Corporation и W3C легко объяснимы с точки зрения роста популярности WWW. В марте 1993 года трафик World Wide Web составлял 0,1% от общего трафика сети NSF, сентябре 1993 года он уже составил 1,0% от общего трафика сети NSF. В октябре 1993 года количество зарегистрированных серверов WWW равнялось 500, а к июню 1994 года оно достигло 1500 и продолжает стремительно расти.
Следует отметить, что появление технологии WWW и ее бурный прогресс не одинок. Приблизительно в это же время появились и другие распределенные информационные технологии в Internet. Это, в первую очередь, Gopher и Wais. Столь бурный рост этого сектора компьютерных технологий привел к появлению на свет очень интересного документа, подготовленного по заказу Комиссии Европейского Союза к ежегодной встрече руководителей Союза 24-25 июня 1994 года на Корфу. Документ прямо обращает внимание руководителей стран Союза на тот факт, что происходит бурный рост рынка информационных технологий, и если Союз не хочет в очередной раз оказаться на вторых ролях, то должен предпринять энергичные усилия по поддержке работ в этой области. Авторы доклада утверждают, что происходит очередная техническая революция, вызванная возможностями современных телекоммуникационных систем и компьютерных сетей. Авторы выделяют десять основных сфер применения новых технологий:
· работа посредством сети, т.е. создание новых рабочих мест;
· обучение по сети;
· научные коммуникации;
· обычные услуги по сети;
· управление дорожным движением;
· управление воздушным движением;
· быстрое медицинское обслуживание;
· создание единой системы защиты прав потребителей и производителей информационных услуг;
· создание единой европейской административной сети;
· создание информационной сети общего пользования для всех граждан Союза.
В каком-то смысле учреждение W3C является ответом профессионалов на медлительность бюрократов из Комиссии ЕвроСоюза. Среди учредителей W3C один из авторов документа - Мартин Банжеманн (Martin Bangemann).
Следующим важным этапом развития технологии World Wide Web стало появление весной 1995 года языка программирования Java, анонсированного компанией Sun Microsystems. Если быть более точным, то прямое отношение к World Wide Web имеет не сам язык, а мобильные коды и возможность их интерпретации программами просмотра Web. Создав свой броузер (программу просмотра) HotJava, Sun смогла продемонстрировать, что идеология интерпретации языка разметки документов может быть расширена. В страницы теперь можно стало встраивать фрагменты программ, которые после передачи по сети активировались на компьютере пользователя, расширяя тем самым концепцию распределенных вычислений.
К этому времени кроме Java появились еще и языки управления сценариями просмотра документов, самым известным из которых стал JavaScript. Тем самым, к середине 1996 года технология World Wide Web превратилась в полноценную гипертекстовую технологию, которая стала позволять решать большинство из тех задач, до которых доросли локальные гипертекстовые системы.
Учитывая все сказанное выше, попытаемся подробно остановиться на особенностях World Wide Web и отдельных ее компонентах, спецификациях и способах наращивания системы за счет внешнего программного обеспечения, существующем программном обеспечении и особенностях его функционирования на различных компьютерных платформах. Этим вопросам и будут посвящены следующие несколько разделов.
3.5.2. Понятие гипертекста
В предыдущем разделе речь шла об истории и основных вехах развития World Wide Web. В последнее время часто приходится слышать, что WWW - это очень просто. Однако, за этой кажущейся простотой скрывается хорошо продуманная сложная система. При этом следует заметить, что система бурно развивается. Для того, чтобы более точно описать это развитие, наши англоязычные коллеги используют эпитет «dramatic». Познакомимся более подробно с WWW.
В 1989 году, когда Т.Бернерс-Ли предложил свою систему, в мире информационных технологий наблюдался повышенный интерес к новому и модному в то время направлению - гипертекстовым системам. Сама идея, но не термин, была введена В.Бушем (Vannevar Bush) в 1945 году в предложениях по созданию электромеханической информационной системы Memex. Несмотря на то, что Буш был советником по науке президента Рузвельта, идея не была реализована. В 1965 году Т.Нельсон (Ted Nelson) ввел в обращение сам термин «гипертекст», развил и даже реализовал некоторые идеи, связанные с работой с «нелинейными» текстами. В 1968 году изобретатель манипулятора «мышь» Д.Енжильбард (Doug Engelbart) продемонстрировал работу с системой, имеющей типичный гипертекстовый интерфейс, и, что интересно, проведена эта демонстрация была с использованием системы телекоммуникаций. Однако внятно описать свою систему он не смог. В 1975 году идея гипертекста нашла воплощение в информационной системе внутреннего распорядка атомного авианосца «Карл Винстон», которая получила название ZOG. В коммерческом варианте система известна как KMS. Работы в этом направлении продолжались и, время от времени, появлялись реализации типа HyperCard фирмы Apple или HyperNode фирмы Xerox. В 1987 была проведена первая специализированная конференция Hypertext'87, материалам которой был посвящен специальный выпуск журнала «Communication ACM».
Идея гипертекстовой информационной системы состоит в том, что пользователь имеет возможность просматривать документы (страницы текста) в том порядке, в котором ему это больше нравится, а не последовательно, как это принято при чтении книг. Поэтому Т.Нельсон и определил гипертекст как нелинейный текст. Достигается это путем создания специального механизма связи различных страниц текста при помощи гипертекстовых ссылок, т.е. у обычного текста есть ссылки типа «следующий-предыдущий», а у гипертекста можно построить еще сколь угодно много других ссылок. Любимыми примерами специалистов по гипертексту являются энциклопедии, Библия, системы типа «Help».
Простой, на первый взгляд, механизм построения ссылок оказывается довольно сложной задачей, т.к. можно построить статические ссылки, динамические ссылки, ассоциированные с документом в целом или только с отдельными его частями, т.е. контекстные ссылки. Дальнейшее развитие этого подхода приводит к расширению понятия гипертекста за счет других информационных ресурсов, включая графику, аудио- и видео-информацию, до понятия гипермедиа. Тем, кто интересуется более подробно различными схемами и способами разработки гипертекстовых систем, стоит обратиться к специальной литературе.
3.5.3. Основные компоненты технологии World Wide Web
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы из четырех существующих ныне, разработав:
· язык гипертекстовой разметки документов HTML (HyperText Markup Language);
· универсальный способ адресации ресурсов в сети URL (Universal Resource Locator);
· протокол обмена гипертекстовой информацией HTTP (HyperText Transfer Protocol).
Позже команда NCSA добавила к этим трем компонентам четвертый:
· универсальный интерфейс шлюзов CGI (Common Gateway Interface).
Java не включается в этот список намеренно, т.к. область применения этого языка гораздо шире чем простое «оживление» World Wide Web.
Идея HTML - пример чрезвычайно удачного решения проблемы построения гипертекстовой системы при помощи специального средства управления отображением. На разработку языка гипертекстовой разметки существенное влияние оказали два фактора: исследования в области интерфейсов гипертекстовых систем и желание обеспечить простой и быстрый способ создания гипертекстовой базы данных, распределенной на сети.
В 1989 году активно обсуждалась проблема интерфейса гипертекстовых систем, т.е. способов отображения гипертекстовой информации и навигации в гипертекстовой сети. Значение гипертекстовой технологии сравнивали со значением книгопечатания. Утверждалось, что лист бумаги и компьютерные средства отображния/воспроизведения серьезно отличаются друг от друга, и поэтому форма представления информации тоже должна отличаться. Наиболее эффективной формой организации гипертекста были признаны контекстные гипертекстовые ссылки, а, кроме того, было признано деление на ссылки, ассоциированные со всем документом в целом и отдельными его частями.
Самым простым способом создания любого документа является его набивка в текстовом редакторе. Опыт создания хорошо размеченных для последующего отображения документов в CERN’е был - трудно найти физика, который не пользовался бы системой TeX или LaTeX. Кроме того, к тому времени существовал стандарт языка разметки - Standard Generalised Markup Language (SGML).
Следует также принять во внимание, что согласно своим предложениям Т.Бернерс-Ли предполагал объединить в единую систему имеющиеся информационные ресурсы CERN, и первыми демонстрационными системами должны были стать системы для NeXT и VAX/VMS.
Обычно гипертекстовые системы имеют специальные программные средства построения гипертекстовых связей. Сами гипертекстовые ссылки хранятся в специальных форматах или даже составляют специальные файлы. Такой подход хорош для локальной системы, но не для распределенной на множестве различных компьютерных платформ. В HTML гипертекстовые ссылки встроены в тело документа и хранятся как его часть. Часто в системах применяют специальные форматы хранения данных для повышения эффективности доступа. В WWW документы - это обычные ASCII- файлы, которые можно подготовить в любом текстовом редакторе. Таким образом, проблема создания гипертекстовой базы данных была решена чрезвычайно просто.
В качестве базы для разработки языка гипертекстовой разметки был выбран SGML (Standard Generalised Markup Language). Следуя академическим традициям, Бернерс-Ли описал HTML в терминах SGML (как описывают язык программирования в терминах формы Бекуса-Наура). Естественно, что в HTML были реализованы все разметки, связанные с выделением параграфов, шрифтов, стилей и т.п., т.к. реализация для NeXT подразумевала графический интерфейс. Важным компонентом языка стало описание встроенных и ассоциированных гипертекстовых ссылок, встроенной графики и обеспечение возможности поиска по ключевым словам.
С момента разработки первой версии языка (HTML 1.0) прошло уже пять лет. За это время произошло довольно серьезное развитие языка. Почти вдвое увеличилось число элементов разметки, оформление документов все больше приближается оформлению качественных печатных изданий, развиваются средства описания нетекстовых информационных ресурсов и способы взаимодействия с прикладным программным обеспечением. Совершенствуется механизм разработки типовых стилей. Фактически, в настоящее время HTML развивается в сторону создания стандартного языка разработки интерфейсов как локальных, так и распределенных систем.
Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т.п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS, например. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как, например Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как, например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип «text/html».
Третьим в нашем списке стоит протокол обмена данными в World Wide Web - HTTP (HyperText Transfer Protocol). Данный протокол предназначен для обмена гипертекстовыми документами и учитывает специфику такого обмена. Так в процессе взаимодействия, клиент может получить новый адрес ресурса на сети (relocation), запросить встроенную графику, принять и передать параметры и т. п. Управление в HTTP реализовано в виде ASCII-команд. Реально, разработчик гипертекстовой базы данных сталкивается с элементами протокола только при использовании внешних расчетных программ или при доступе к внешним, относительно WWW, информационным ресурсам, например базам данных.
Последняя составляющая технологии WWW - это уже плод работы группы NCSA - спецификация CGI (Common Gateway Interface). CGI была специально разработана для расширения возможностей WWW за счет подключения всевозможного внешнего программного обеспечения. Такой подход логично продолжал принцип публичности и простоты разработки и наращивания возможностей WWW. Если команда CERN предложила простой и быстрый способ разработки баз данных, то NCSA развила этот принцип на разработку программных средств. Надо заметить, что в общедоступной библиотеке CERN были модули, позволяющие программистам подключать свои программы к серверу HTTP, но это требовало использования этой библиотеки. Предложенный и описанный в CGI способ подключения не требовал дополнительных библиотек и буквально ошеломлял своей простотой. Сервер взаимодействовал с программами через стандартные потоки ввода/вывода, что упрощает программирование до предела. При реализации CGI чрезвычайно важное место заняли методы доступа, описанные в HTTP. И хотя реально используются только два из них (GET и POST), опыт развития HTML показывает, что сообщество WWW ждет развития и CGI по мере усложнения задач, в которых будет использоваться WWW-технология.
3.5.4. Архитектура построения системы
От описания основных компонентов перейдем к архитектуре взаимодействия программного обеспечения в системе World Wide Web. WWW построена по хорошо известной схеме «клиент-сервер». На рисунке 3.25 показано, как разделены функции в этой схеме.
Программа-клиент выполняет функции интерфейса пользователя и обеспечивает доступ практически ко всем информационным ресурсам Internet. В этом смысле она выходит за обычные рамки работы клиента только с сервером определенного протокола, как это происходит в telnet, например. Отчасти, довольно широко распространенное мнение, что Mosaic или Netscape, которые безусловно являются WWW-клиентами, это просто графический интерфейс в Internet, является верным. Однако, как уже было отмечено, базовые компоненты WWW-технологии (HTML и URL) играют при доступе к другим ресурсам Mosaic не последнюю роль, и поэтому мультипротокольные клиенты должны быть отнесены именно к World Wide Web, а не к другим информационным технологиям Internet. Фактически, клиент - это интерпретатор HTML. И как типичный интерпретатор, клиент в зависимости от команд (разметки) выполняет различные функции. В круг этих функций входит не только размещение текста на экране, но и обмен информацией с сервером по мере анализа полученного HTML-текста, что наиболее наглядно происходит при отображении встроенных в текст графических образов. При анализе URL-спецификации или по командам сервера клиент запускает дополнительные внешние программы для работы с документами в форматах, отличных от HTML, например GIF, JPEG, MPEG, Postscript и т.п. Вообще говоря, для запуска клиентом программ независимо от типа документа была разработана программа Luncher, но в последнее время гораздо большее распространение получил механизм согласования запускаемых программ через MIME-типы.
Другую часть программного комплекса WWW составляет сервер протокола HTTP, базы данных документов в формате HTML, управляемые сервером, и программное обеспечение, разработанное в стандарте спецификации CGI. До самого последнего времени (до образования Netscape) реально использовалось два HTTP-сервера: сервер CERN и сервер NCSA. Но в настоящее время число базовых серверов расширилось. Появился очень неплохой сервер для MS-Windows и Apachie-сервер для Unix- платформ. Существуют и другие, но два последних можно выделить из соображений доступности использования. Сервер для Windows - это shareware, но без встроенного самоликвидатора, как в Netscape. Учитывая распространенность персоналок в нашей стране, такое программное обеспечение дает возможность попробовать, что такое WWW. Второй сервер - это ответ на угрозу коммерциализации. Netscape уже не распространяет свой сервер Netsite свободно и прошел слух, что NCSA-сервер также будет распространяться на коммерческой основе. В результате был разработан Apachie, который, по словам его авторов, будет freeware, и реализует новые дополнения к протоколу HTTP, связанные с защитой от несанкционированного доступа, которые предложены группой по разработке этого протокола и реализуются практически во всех коммерческих серверах.
|
|
Рис. 3.25. Архитектура WWW-технологии
База данных HTML-документов - это часть файловой системы, которая содержит текстовые файлы в формате HTML и связанные с ними графику и другие ресурсы. Особое внимание хотелось бы обратить на документы, содержащие элементы экранных форм. Эти документы реально обеспечивают доступ к внешнему программному обеспечению.
Прикладное программное обеспечение, работающее с сервером, можно разделить на программы-шлюзы и прочие. Шлюзы - это программы, обеспечивающие взаимодействие сервера с серверами других протоколов, например ftp, или с распределенными на сети серверами Oracle. Прочие программы - это программы, принимающие данные от сервера и выполняющие какие-либо действия: получение текущей даты, реализацию графических ссылок, доступ к локальным базам данных или просто расчеты.
Все, что было сказано до этого момента, можно отнести к классической схеме World Wide Web. В настоящее время следует говорить об изменении общей архитектуры.
Как видно из рисунка 3.26, к середине 1996 года произошли некоторые изменения в архитектуре сервиса World Wide Web.
Произошел возврат к модульной структуре сервера World Wide Web. Этот возврат был реализован в виде спецификации API. API - это спецификация разработки прикладных модулей, которые встраиваются в сервер, точнее редактируются совместно с модулями сервера. Применение во всех серверах многопотоковой технологии выполнения подзадач делает такой способ расширения возможностей сервера более экономичным с точки зрения ресурсов вычислительной установки, чем разработка CGI-скриптов.
В дополнение к HTML активно стал применяться еще один язык разметки - VRML (Virtual Reality Modeling Language). В данном случае речь идет об описании трехмерных сен и возможности «бродить» по этим мирам. При этом в VRML также, как и в HTML предусмотрены гипертекстовые ссылки, что позволяет создавать смешанные базы данных, где информационный архив, например, можно представить в виде книг в библиотеке, среди которых может путешествовать автор, выбирая нужную ему тематику и источник, которые затем представляются в формате документа HTML.
|
|
Рис. 3.26. Архитектура World Wide Web к середине 1996 года
Java-applet’ы - это мобильные коды Java, ссылки на которые вмонтированы в тело документа. При доступе к такому документу программа просмотра пользователя предварительно анализирует документ на предмет наличия в нем такого типа ссылок, и, если они существуют, то подкачивает мобильные коды в свою память. Коды могут сразу выполняться по мере размещения их на компьютере пользователя, но могут активироваться и при помощи специальных команд.
Как видно из рисунка, изменения коснулись и клиентской части технологии. В настоящее время происходит постепенный переход от простой классической архитектуры клиент-сервер к архитектуре с сервером приложений, в роли которого выступает программа-клиент. В частности, NCSA опубликовала спецификацию CCI (Common Client Interface) для разработки приложений для работы с сервисами World Wide Web через программу Mosaic.
Завершая обсуждение архитектуры World Wide Web, хотелось бы еще раз подчеркнуть, что ее компоненты существуют практически для всех типов компьютерных платформ и свободно доступны в сети. Любой, кто имеет доступ в Internet, может создать свой WWW-сервер, или, по крайней мере, посмотреть информацию с других серверов.
3.5.4.1. Язык гипертекстовой разметки HTML
Язык гипертекстовой разметки HTML (HyperText Markup Language) был предложен Тимом Бернерсом-Ли в 1989 году в качестве одного из компонентов технологии разработки распределенной гипертекстовой системы World Wide Web.
Разработчики HTML пытались решить две задачи:
· дать дизайнерам гипертекстовых баз данных простое средство создания документов;
· сделать это средство достаточно мощным, чтобы отразить имевшиеся на тот момент представления об интерфейсе пользователя гипертекстовых баз данных.
Первая задача была решена за счет выбора таговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. Примером такой системы является хорошо известный язык разметки научных документов TeX, предложенный Американским Математическим Обществом, и программы его интерпретации.
К моменту создания HTML существовал стандарт языка разметки печатных документов - SGML (Standard Generalized Markup Language), который и был взят в качестве основы HTML. Предполагалось, что такое решение поможет использовать существующее программное обеспечение для интерпретации нового языка. Однако, будучи доступным широкому кругу пользователей Internet, HTML зажил своей собственной жизнью. Вероятно, многие администраторы баз данных WWW и разработчики программного обеспечения для этой системы имеют довольно смутное представление о стандартном языке разметки SGML.
Вторым важным моментом, повлиявшим на судьбу HTML, стал выбор в качестве элемента гипертекстовой базы данных обычного текстового файла, который хранится средствами файловой системы операционной среды компьютера. Такой выбор был сделан под влиянием следующих факторов:
· такой файл можно создать в любом текстовом редакторе на любой аппаратной платформе в среде любой операционной системы.
· к моменту разработки HTML существовал американский стандарт для разработки сетевых информационных систем - Z39.50, в котором в качестве единицы хранения указывался простой текстовый файл в кодировке LATIN1, что соответствует US ASCII.
Таким образом, гипертекстовая база данных в концепции WWW - это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки).
Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы данных и интерфейсом пользователя.
Сервер, кроме доступа к документам и обработки гипертекстовых ссылок, осуществляет также препроцессорную обработку документов, в то время как интерфейс пользователя осуществляет интерпретацию конструкций языка, связанных с представлением информации.
К настоящему времени известна уже третья версия языка - HTML 3.0, которая находится в стадии развития. Если первая версия языка (HTML 1.0) была направлена на представление языка как такового, где описание его возможностей носило скорее рекомендательный характер, вторая версия языка (HTML 2.0) фиксировала практику использования конструкций языка, версия ++ (HTML++) представляла новые возможности, расширяя набор элементов HTML в сторону отображения научной информации и таблиц, а также улучшения стиля компоновки изображений и текста, то версия 3.0 призвана упорядочить все нововведения и согласовать их с существующей практикой. Кроме этого, в версии 3.0 снова делается попытка формализации интерфейса пользователя гипертекстовой распределенной системы.
3.5.4.2. Принципы построения и интерпретации HTML
Таговая модель описывает документ как совокупность элементов, каждый из которых окружен тагами. По своему значению таги близки к понятию скобок "begin/end" в универсальных языках программирования, которые задают области действия имен локальных переменных и т. п. Таги определяют область действия правил интерпретации текстовых элементов документа. Типичным примером такого рода является таг стиля Italic, который определяет область отображения курсива.
Текст на языке HTML:
Текст, следующий за словом «Italic» <I>, отображается как курсив</I>.
Текст, отображаемый программой интерпретации:
Текст, следующий за словом «Italic», отображается как курсив.
В приведенном выше примере элемент текста, который должен быть выделен курсивом, заключен между тагом начала стиля «Italic» - <I> и тагом конца стиля - </I>. Общая схема построения элемента текста в формате HTML может быть записана в следующем виде:
«элемент»:= < «имя элемента» «список атрибутов»> содержание элемента </ «имя элемента»>
Конструкция перед содержанием элемента называется тагом начала элемента, а конструкция, расположенная после содержания элемента, - тагом конца элемента.
Структура гипертекстовой сети задается гипертекстовыми ссылками. Гипертекстовая ссылка - это адрес другого HTML документа, который тематически, логически или каким-либо другим способом связан с документом, в котором ссылка определена.
Для записи гипертекстовых ссылок в системе WWW была разработана специальная форма, которая называется Universe Resource Locator. Типичным примером использования этой записи можно считать следующий пример:
Этот текст содержит <A HREF= «http://polyn.net.kiae.su/altai/index.html»> гипертекстовую ссылку</A>.
В приведенном выше примере элемент «A», который в HTML называют якорем (anchor), использует атрибут «HREF», который обозначает гипертекстовую ссылку (HyperText REFerence), для записи этой ссылки в форме URL. Данная ссылка указывает на документ с именем «index.html» в директории «altai» на сервере «polyn.net.kiae.su», доступ к которому осуществляется по протоколу «http».
Гипертекстовые ссылки в HTML делятся на два класса: контекстные гипертекстовые ссылки и общие. Контекстные ссылки вмонтированы в тело документа, как это было продемонстрировано в предыдущем примере, в то время как общие ссылки связаны со всем документом в целом и могут быть использованы при просмотре любого фрагмента документа. Оба класса ссылок присутствуют в стандарте языка с самого его рождения, однако, первоначально наибольшей популярностью пользовались контекстные ссылки. Эта популярность привела к тому, что механизм использования общих ссылок практически полностью «атрофировался». Однако по мере стандартизации интерфейса пользователя и стилей представления информации разработчики языка снова вернулись к общим ссылкам и стремятся приспособить их к задачам управления этим интерфейсом.
Структура HTML-документа позволяет использовать вложенные друг в друга элементы. Собственно, сам документ - это один большой элемент с именем «HTML»:
<HTML> Содержание документа </HTML>
Сам элемент HTML или гипертекстовый документ состоит из двух частей: заголовка документа (HEAD) и тела документа (BODY):
<HTML>
<HEAD>
Содержание заголовка
</HEAD>
<BODY>
Содержание тела документа
</BODY>
</HTML>
Приведенная выше форма записи определяет классический HTML-документ. Введение в язык HTML фреймов определило еще один шаблон документа:
<HTML>
<!--
Author: HTMLed User
Date: January 21, 1996
-->
<HEAD>
</HEAD>
<FRAMESET COLS="40%,*">
<NOFRAMES>
<BODY>
Sorry there are not a frame support in your browser.
</BODY>
</NOFRAMES>
<FRAMESET ROWS="120,*,60">
<FRAME SRC=banner.htm NAME=banner>
<FRAME SRC="www.htm" NAME=content>
<FRAME SRC="bottom.htm" NAME=bottom>
</FRAMESET>
<FRAMESET ROWS="100%">
<FRAME SRC="www_hist.htm" NAME=info>
</FRAMESET>
</FRAMESET>
</HTML>
В данном примере представлен документ, который состоит из трех окон внутри рабочего окна программы просмотра, в каждое из которых загружается обычный документ.
Рассмотрим пример классического документа:
<HTML>
<!--
Author: Pavel Khramtsov
Date: January 21, 1996
-->
<HEAD>
<TITLE>This is a Baner</TITLE>
</HEAD>
<BODY BACKGROUND=www_wall.jpg VLINK=0000FF LINK=FF0000>
<CENTER>
<TABLE>
<TR><TD><IMG SRC="interne0.jpg"></TD>
<TD CENTER>
<H3>Администрирование Internet</H3>
<I>Центр Информационных Технологий, 1996.</I>
</TD></TR>
</TABLE>
</CENTER>
</BODY>
</HTML>
Все, что расположено между <HTML> и </HTML> - это документ. Содержание элемента HEAD определяет заголовок документа, который состоит из двух элементов: TITLE и BASE. Вслед за заголовком начинается тело документа, которое содержит в своих первых строках некоторую вводную информацию и содержание документа, оформленное в виде списка.
Каждый документ в системе World Wide Web имеет свое имя, которое указывается в элементе TITLE заголовка документа. Его мы видим в первой строке интерфейса.
Контейнер BODY открывает тело документа. В качестве фона в этом элементе определена картинка back.gif. Эта картинка – «back.gif» - задана частичной формой спецификации URL, которая не задает полного адреса ресурса в сети.
Затем мы определили таблицу, состоящую из двух ячеек. В одной ячейке картинка, в то время как в другой - текстовый фрагмент. Текст определен как заголовок третьего уровня, который должен отображаться стилем Italic.
Кроме текстовых фрагментов и описаний фреймов на странице могут встретиться программы на JavaScript:
<HTML>
<HEAD>
<TITLE>JavaScript</TITLE>
<SCRIPT LANGUAGE="JavaScript">
<!-- Hide script from user
// * * *
// * * Form runing string
// * * *
adv_string = "Internet\""
status_string = adv_string+adv_string+adv_string+adv_string+adv_string+adv_string
// * * *
// * * Background function definition
// * * *
i=0
function background()
{
// Select 50 symbols from status string target.
window.status = status_string.substring(i,i+180)
// After last character move to first position
if(++i == 180) i=0
// The Clock is here
current_date = new Date()
window.document.form1.clock.value = current_date.getHours()+":"+current_date.getMinutes()+":"+current_date.getSeconds()
// Set timeout between function execution
id = setTimeout("background()",500)
window.document.form1.kuku.value = "number" + i
}
// This is the end of code definition -->
</SCRIPT>
</HEAD>
<BODY onLoad="background()" BACKGROUND=www_wal0.jpg>
<H1>JavaScript</H1>
<HR>
JavaScript - текст о JavaScript.:
<UL>
<LI><A HREF="#m_clock">Часы</A>
<LI><A HREF="#wind">Бегущая строка</A>
</UL>
<HR>
<A NAME=m_clock>
<FORM NAME=form1 ACTION="new_window()">
<INPUT NAME=clock TYPE=text SIZE=8 MAXLENGTH=8>
<HR>
<A NAME=wind>
<INPUT
TYPE=button NAME=help Value="HELP" onClick="window.open('clock.htm','Clock_Window','scrollbars=yes,
width=450,height=350')">.
<HR>
<INPUT NAME=kuku type=text>
<HR>
</FORM
<P>
</BODY>
</HTML>
В данном случае описаны две программы: программа идущих часов и программа бегущей строки. Данный язык поддерживают не все программы просмотра.
3.5.5. Протокол обмена гипертекстовой информацией (HyperText Transfer Protocol, HTTP 1.0.)
HTTP - это протокол прикладного уровня, разработанный для обмена гипертекстовой информацией в сети Internet. Протокол используется одной из популярнейших систем Сети - Word Wide Web - с 1990 года.
Реальная информационная система требует гораздо большего количества функций, чем просто поиск. HTTP позволяет реализовать в рамках обмена данными набор методов доступа, базирующихся на спецификации универсального идентификатора ресурсов (Universal Resource Identifier), применяемого в форме универсального локатора ресурсов (Universe Resource Locator) или универсального имени ресурса (Universal Resource Name). Сообщения по сети при использовании протокола HTTP передаются в формате, схожим с форматом почтового сообщения Internet (RFC-822) или с форматом сообщений MIME (Multiperposal Internet Mail Exchange). HTTP используется для взаимодействия программ-клиентов с программами-шлюзами, разрешающими доступ к ресурсам электронной почты Internet (SMTP), спискам новостей (NNTP), файловым архивам (FTP), системам Gopher и WAIS. Протокол разработан для доступа к этим ресурсам посредством промежуточных программ-серверов (proxy), которые позволяют передавать информацию между различными информационными службами без потерь. Протокол реализует принцип «запрос/ответ». Запрашивающая программа - клиент - инициирует взаимодействие с отвечающей программой - сервером, и посылает запрос, включающий в себя метод доступа, адрес URI, версию протокола, похожее по форме на MIME сообщение с модификаторами типа передаваемой информации, информацию клиента, и, возможно, тело сообщения клиента. Сервер отвечает строкой состояния, включающей версию протокола и код возврата, за которой следует сообщение в форме, похожей на MIME. Данное сообщение содержит информацию сервера, метаинформацию и тело сообщения. Понятно, что в принципе, одна и та же программа может выступать и в роли сервера и в роли клиента (так собственно и происходит при использовании proxy-серверов).
При работе в Internet для обслуживания HTTP-запросов используется 80 порт TCP/IP. Практика использования протокола такова, что клиент устанавливает соединение и ждет ответа сервера. После отправки ответа сервер инициирует разрыв соединения. Таким образом, при передаче сложных гипертекстовых страниц соединение может устанавливаться несколько раз. Остановимся более подробно на механизме взаимодействия и форме передаваемой информации.
3.5.5.1. Форма запроса клиента
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:
GET http://polyn.net.kiae.su/
В этой записи слово GET обозначает метод доступа GET, а http://polyn.net.kiae.su/ - это запрос ресурса. Клиенты, которые способны поддерживать версии протокола выше 0.9 должны пользоваться полной формой запроса. При использовании полной формы в запросе указываются строка запроса, несколько заголовков (заголовок запроса или общий заголовок) и, возможно, тело обозначения ресурса. В форме Бекуса-Наура общий вид полного запроса выглядит так:
<Полный запрос>:= <Строка Запроса> (<Общий заголовок>|<Заголовок запроса>|<Заголовок обозначения ресурса>)<символ новой строки>[<тело ресурса>]
Квадратные скобки здесь обозначают необязательные элементы заголовка. Строка запроса - это, практически, простой запрос ресурса. Отличие состоит в том, что в строке запроса можно указывать различные методы доступа, и за запросом ресурса следует указывать версию протокола. Например, для вызова внешней программы можно использовать следующую строку запроса:
POST http://polyn.net.kiae.su/cgi-bin/test HTTP/1.0
В данном случае используется метод POST и протокол версии 1.0.
3.5.5.2. Методы доступа
В настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD.
GET - метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не текст программы. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса. Имеется разновидность метода GET - условный GET. При использовании этого метода сервер ответит на запрос только в том случае, если будут выполнены условия передачи. Это позволяет разгрузить сеть, избавив ее от передачи ненужной информации. Условие указывается в поле «if-Modified-Since» заголовка запроса. При использовании метода GET в поле тела ресурса возвращается собственно затребованная информация (текст HTML-документа, например).
HEAD - метод, аналогичный GET, но не возвращает тела ресурса. Используется для получения информации о ресурсе. Условного HEAD не существует. Данный метод используется для тестирования гипертекстовых ссылок.
POST - этот метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличие от GET и HEAD, в POST передается тело ресурса, которое и является информацией из поля форм или других источников ввода. В первых версиях протокола были определены и другие методы доступа (DELETE, например), но они не нашли должного применения. Многие функции, которые возлагали на эти методы, можно успешно выполнять через POST.
Изменение числа методов доступа отражает практику использования HTTP. Однако, с исторической и методической точек зрения, первые версии протокола представляют несомненный интерес, особенно раздел, описывающий методы доступа. В версии 1993 года насчитывалось 13 различных методов доступа. Среди этих методов были такие, например, как:
· CHECKOUT - защита от несанкционированного доступа;
· PUT - замена содержания информационного ресурса;
· DELETE - удаление ресурса;
· LINK - создание гипертекстовой ссылки;
· UNLINK - удаление гипертекстовой ссылки;
· SPACEJUMP - переход по координатам;
· SEARCH - поиск.
Из этого списка видно, что протокол был действительно максимально ориентирован на работу с гипертекстовыми распределенными системами, причем не только с точки зрения потребителя, но и с точки зрения разработчика подобных систем. Однако, во-первых, как показывал опыт, практически не использовались методы доступа, связанные с изменением информации. Это объясняется, прежде всего, соображениями безопасности. Ни один администратор не позволит, неизвестно кому менять информацию на его сервере. Во-вторых, методы SPACEJUMP и SEARCH были с успехом заменены на функционально аналогичные CGI-скрипты. Из этого не следует, что их возрождение невозможно, например, в язык гипертекстовой разметки вернулись ссылки, общие для всего документа, но пока их реализация в протоколе отложена. В-третьих, не нашли практической реализации методы установления/удаления ссылок LINK и UNLINK. Но необходимость в них растет и связана она с реорганизацией сети. Многие информационные ресурсы меняют свои адреса, что вносит беспорядок в структуру сети, где и без этого начинающему пользователю трудно что-либо найти. Одним словом, вопрос о новых методах доступа все еще открыт, поэтому, видимо, спецификация HTTP еще не вышла на стадию RFC и остается в виде Internet Draft.
В обеих формах запроса важное место занимает форма запроса ресурса, которая кодируется в соответствии со спецификацией URI. Применительно к World Wide Web эта спецификация получила название URL. При обращении к серверу можно использовать как полную форму URL, так и упрощенную.
Полная форма содержит тип протокола доступа, адрес сервера ресурса, и адрес ресурса на сервере (рисунок 3.27).
|
|

Рис. 3.27. Полный адрес ресурса
Однако такой адрес реально нужен для работы через промежуточный сервер, так как тот может пересылать запросы. При обращении к первичному серверу клиент может опускать протокол и адрес, устанавливая взаимодействие с сервером по адресу, указанному в URL (в исходном документе), и порту 80, передавая только путь от корня сервера.
Здесь пока оставим обсуждение элементов запроса и обратимся к структуре ответа сервера. Дело в том, что элементы заголовков запроса и ответа одинаковые, и поэтому их имеет смысл обсудить после определения структуры ответа сервера.
3.5.5.3. Ответ сервера
Ответ сервера может быть, как и запрос, упрощенным или полным. При упрощенном ответе сервер возвращает только тело ресурса (например, текст HTML-документа). При полном ответе клиенту возвращается строка состояния (Status-Line), общий заголовок, заголовок ответа, заголовок ресурса и тело ресурса. В форме Бекуса-Наура полный ответ представляется следующим образом:
<Полный ответ>:= <Строка состояния> (<Общий заголовок>|<Заголовок ответа>|<Заголовок ресурса>) <символ новой строки>[<тело ресурса>]
Строка состояния состоит из версии протокола, кода возврата и краткого описания этого кода. Например, она может выглядеть так:
«HTTP/1.0 200 Success».
Заголовок ответа сервера может состоять из адреса URI запрашиваемого ресурса, и/или наименования программы сервера, и/или кода идентификации для работы в защищенном режиме. Состав полей заголовка ресурса является общим и для запроса клиента и для ответа сервера, и состоит из разрешения на метод доступа, типа кодировки тела ресурса (содержания ресурса), длины тела ресурса, типа ресурса, время действия данной копии ресурса, времени последнего изменения ресурса и расширения заголовка.
Рассмотрим более подробно поля заголовка, обращая внимание на реальное применение каждого из них и возможность проявления ошибок при обработке этих полей разными программами (серверами и клиентами).
Если в заголовке ответа сервера указано предложение Location, то это значит, что требуемый ресурс находится по-другому адресу и его надо запросить заново. Такая процедура называется перенаправлением. Перенаправление в заголовке будет выглядеть как:
Location: http://apollo.polyn.kiae.su/risk/riskform.html
Имя и версия сервера указываются в поле Server. При использовании сервера Церн данное поле будет выглядеть как:
Server: CERN/3.0 libwww/2.17
В заголовке может встречаться и поле контроля доступа WWW-Authenticate, которое определяет способ доступа к закрытым ресурсам. Например, это поле может выглядеть как:
WWW-Athenticate: Basic realm= «WallyWorld»
Кроме рассмотренных выше полей, в заголовке могут встретиться и другие поля, которые определяют содержание тела передаваемого ресурса. Эти поля относятся к заголовку ресурса, но в ответе сервера они встречаются вперемешку с общими полями. Поле Allow определяет разрешенные методы доступа к ресурсу:
Allow: GET, HEAD
Поле Сontent-Encoding определяет тип кодирования передаваемого ресурса:
Content-Encoding: x-gzip
В данном случае указывается, что ресурс является заархивированным файлом в формате zip. Обычно ресурсы хранятся в виде, указанном в данном поле, и при их получении клиент должен обеспечить их преобразование в приемлемый для отображения вид. Это своего рода предобработка данных, которая базируется обычно на MIME типах. В машинах, где недостаточно памяти на видео-адаптерах, используют предобработку для преобразования изображений в приемлемый для отображения вид. Так, например, для персональных компьютеров с 512 КБ памяти на видеоадаптере используют предобработку для преобразования 256-цветных картинок в 16-цветные. Если этого не делать, то можно наблюдать интересный эффект: в Unix-системах при работе с программами Chimera и Mosaic 256-цветные картинки удваиваются, т.е. вместо одной на экране отображаются последовательно две картинки. Это связано с тем, что для 256 цветов нужно ровно в два раза больше памяти, чем для 16. Для того, чтобы избежать двойного отображения встроенных в текст картинок, их следует преобразовать.
Другим полем, которое проявляет себя при работе в сети, порождая ошибки отображения ранними версиями программ просмотра или ранним версиями программ серверов, является поле Content-Length. Поле Content-Length указывает размер (количество байтов) передаваемого ресурса. Это поле указывается как клиентом при работе по методу POST, так и сервером при ответе на запросы клиентов. При этом в ранних версиях программ-серверов может порождаться ошибка, вызванная возможностью вставки сервером некоторой информации в текст ресурса. Например, сервер NCSA (1.3) позволяет вставлять в текст HTML-документов фрагменты текста из других файлов при помощи выражения типа:
<!--#includes virtual="/include/commonheader.html" -->
В данном случае речь идет об общей заставке для всех документов некоторого раздела. На сервере в директории документов хранится файл одного размера, но после выполнения подстановки размер файла увеличивается, однако, сервер сообщает клиенту старый размер файла. Новые программы-клиенты (Netscape, Mosaic) неправильно обрабатывают такой ответ и информация не отображается.
Поле Content-Type определяет тип информации, передаваемой сервером. Наиболее часто используются типы text/play - простой тест и text/html - документ в формате HTML. Для сокращения трафика по сети существует несколько полей, связанных со временем передачи информации и периодичностью ее изменения на серверах. Поле Date определяет время отправки сообщения. Информация из данного поля сохраняется в файле статистики сервера и может быть использована для анализа доступа к ресурсам сервера из сети.
Поле Expires определяет время годности ресурса для использования. Если время использования вышло, то ресурс не должен передаваться. Точнее, его не следует передавать и принимать. О поле if-Modified-Sience уже упоминалось. Оно предназначено для того, чтобы не передавать имеющиеся у клиента копии ресурса, если не были произведены его изменения. Поле Pragma используется при передаче сообщений с сервера на сервер. Реально известно только одно значение данного поля: no-cache, которое запрещает запоминать в буфере данные для последующего использования.
Поле Referer используется для того, чтобы указать, из какого ресурса была осуществлена ссылка на ресурс. Данное поле - это мечта любого администратора базы данных сети. При помощи информации из этого поля можно определить, в каких WWW-страницах прописан конкретный сервер. От этого зависит количество обращений к серверу, «качество» пользователей, время отклика на информацию, размещаемую на сервере. При необходимости можно связаться с администратором этого сервера и уведомить его об изменениях на вашем сервере.
3.5.5.4. Защита сервера от несанкционированного доступа
Отдельное место при обсуждении протокола занимают вопросы, связанные с обеспечением защиты ресурсов сервера от несанкционированного доступа. Как было отмечено в предыдущих разделах, первоначально разработка защищенных способов обмена данными в системе World Wide Web не предполагалась. Однако быстрое развитие популярности системы привело к тому, что многие коммерческие организации стали устанавливать серверы HTTP на свои машины. Кроме этого, конфиденциальной информации много и в научно-исследовательских государственных организациях. Таким образом, возникла необходимость в разработке механизмов защиты информации для системы WWW.
Проблема защиты информации на Internet - это отдельная большая тема. В данном разделе мы рассмотрим только обеспечение безопасности при использовании серверов HTTP.
При обсуждении этой проблемы полезно вспомнить схему WWW-технологии (рисунок 3.26). Из этой схемы видно, что в этой технологии имеется как минимум две потенциальные "дыры" .
Первая связана с чтением защищенных текстовых файлов. Для решения этой задачи имеется достаточно много традиционных механизмов, встроенных в операционные системы. Проблема возникает, если администратор системы решит использовать для размещения WWW-файлов и FTP-архива одно и тоже дисковое пространство. В этом случае защищенные WWW-файлы окажутся доступными для «анонимного» FTP-доступа. Многие серверы разрешают создавать в дереве поддерживаемых ими документов «домашние» страницы пользователей с помощью методов POST и GET. Это значит, что пользователи могут изменять информацию на компьютере сервера. Данные, вводимые пользователем, передаются как тело ресурса при методе POST через стандартный ввод, а методе GET через переменные окружения. Естественно, что разрешение создания файлов на сервере протокола HTTP создает потенциальную опасность доступа к защищенной информации лиц, не имеющих права доступа к ней. Решается эта проблема путем создания специальных файлов прав пользователей сервера WWW.
|
|
Рис. 3.28. Схема управления ресурсов сервером HTTP
Вторая возможность проникновения в компьютерную систему через сервер WWW связана с CGI-скриптами. CGI-скрипт - это программа, которую сервер HTTP может запускать для реализации механизмов, не предусмотренных в протоколе. Многие достаточно мощные информационные механизмы WWW реализованы посредством CGI-скриптов. К ним относятся: программы поиска по ключевым словам, программы реализации графических гипертекстовых ссылок - imagemap, программы сопряжения с системами управления базами данных и т.п. Естественно, что при этом появляется возможность получить доступ к системным ресурсам. Обычно внешняя программа запускается с идентификатором пользователя, отличным от идентификатора сервера. Данный идентификатор указывается при конфигурировании сервера. Наиболее безопасным здесь является идентификатор пользователя nobody (65534). Основная опасность скриптов заключена в том, что данные в скрипт посылаются программой-клиентом. Для того, чтобы в качестве параметров не передавали «подозрительных» данных, многие серверы производят проверку параметров на наличие допустимых символов. Особенно опасны скрипты для тех, кто использует сервер на персональном компьютере с MS-Windows 3.1. В этом случае файловая система практически не защищена. Одной из характерных для скриптов проблем является размер входных данных. Многие «умные» серверы обрезают слишком большие входные потоки и тем самым защищают скрипты от «поломки». Кроме перечисленных выше опасностей, порождаемых природой сети и системы WWW, существует еще одна, связанная с такой экзотикой, как мобильные коды. Мобильный код - это программа, которая может передаваться по сети для выполнения ее клиентом. Код встраивается в WWW-страницу при помощи тага <APP ...> - application. Например, Sun выпустила WWW-клиента HotJava, который позволяет интерпретировать язык Java. Существуют клиенты и для других языков, Safe-Tcl для Tcl, например. Главное назначение таких средств - реализация мультимедийных страниц и реализация работы в rеal-time. Опасность применения такого сорта страниц очевидна, так как повторяет способ распространения различного сорта вирусов. Однако пока речи о защите от такого сорта «взломов» не идет, видимо в силу довольно ограниченного применения данной возможности в сети.
Практически любой сервер имеет механизм назначения паролей и прав доступа для различных пользователей, который базируется на схеме идентификации протокола HTTP 1.0. Данная схема предполагает, что программа-клиент посылает серверу идентификатор пользователя и пароль. Понятно, что такой механизм не обеспечивает защиты передаваемой по сети информации, и она может стать легкой добычей злоумышленников.
Для того, чтобы этого не происходило, в рамках WWW ведется разработка других схем защиты. Они строятся на двух широко известных принципах: контроль доступа по IP-адресам и шифрация. Первый принцип реализован в программе типа «стена» (Firewall). Сервер разрешает обращаться к себе только с определенных IP-адресов и выполнять только определенные операции. Слабое место такого подхода с точки зрения WWW заключается в том, что обратиться могут через сервер-посредник, которому разрешен доступ к ресурсам защищенного первичного сервера. Поэтому применяют шифрование паролей и идентификаторов по аналогии с системой «Керберос». На принципе шифрования построен новый протокол SHTTP, который реализован в серверах Netsite (последние версии), Apachie и в новых серверах CERN и NCSA. Однако реально широкого применения это программное обеспечение еще не нашло и находится в стадии развития, а потому содержит достаточно большое количество ошибок.
Завершая обсуждение протокола HTTP и способов его реализации, нужно отметить, что в качестве широко доступного информационного ресурса WWW уже состоялась, следующий шаг - серьезные коммерческие применения. Но для этого необходимо еще внедрить в практику защищенные протоколы обмена, базирующиеся на HTTP. В последнее время появилось много новых программ, реализующих протокол HTTP. Это серверы и клиенты, написанные как для новых компьютерных платформ, так и для возможностей SHTTP. Реальную возможность попробовать свои силы в разработке различных WWW-приложений имеют и отечественные программисты.
3.5.6. Universal Resource Identifier - универсальный идентификатор. Спецификация универсального адреса информационного ресурса в сети
Из всех спецификаций World Wide Web только спецификация URI доведена до состояния RFC. За этим стандартом закреплен номер 1630. Выпущен этот документ в 1994 году и отражает состояние информационных ресурсов Internet на это время.
URI определяет способ записи (кодирования) адресов различных информационных ресурсов при обращении к ним из страниц WWW. Однако в последнее время данная спецификация стала встречаться и в почтовых сообщениях. При этом видимо предполагается, что пользователи почты должны использовать клиентов, поддерживающих этот формат сообщения (HTML). Реально, речь может идти о клиентах MIME.
Необходимость в URI была понятна разработчикам WWW c момента зарождения системы, т.к. предполагалось объединение в единую информационную среду средств, использующих различные способы идентификации информационных ресурсов. Первоначально это были FTP-архивы, информационно-поисковая система Alise, и справочная система ЦЕРН. Однако Бернерс-Ли подошел к делу основательно и разработал спецификацию, которая включала в себя обращения к FTP, Gopher, WAIS, Usenet, E-mail, Prospero, Telnet, Whois, X.500 и, конечно, HTTP (WWW). В итоге была разработана универсальная спецификация, которая позволяет расширять список адресуемых ресурсов за счет появления новых схем.
Место применения URI - гипертекстовые ссылки, которые записываются в тагах <A HREF=URI> и <LINK HREF=URI>. Встраиваемые графические объекты также адресуются по спецификации URI в тагах <IMG SRC=URI> и <FIG SRC=URI>. Реализация URI для WWW называется URL (Uniform Resource Locator). Точнее, URL - это реализация схемы URI, отображенная на алгоритм доступа к ресурсам по сетевым протоколам. Существует еще и URN (Uniform Resource Name), которое отображает URI в пространство имен на сети. Появление URN связано с желанием адресовать части почтового сообщения MIME. Но здесь есть момент, который находится в стадии дебатов. Сообщение «живет» не более 5 дней. Если оно сохранено, то его можно превратить в другой информационный ресурс, например, WWW-страницу. Поэтому судьба URN еще не решена.
3.5.6.1. Принципы построения адреса WWW
В основу URI были заложены следующие принципы:
· Расширяемость - новые адресные схемы должны были легко вписываться в существующий синтаксис URI.
· Полнота - по возможности, любая из существовавших схем должна была описываться посредством URI.
· Читаемость - адрес должен был быть легко читаем пользователем, что вообще характерно для технологии WWW - документы вместе с ссылками могут разрабатываться в обычном текстовом редакторе.
Расширяемость была достигнута за счет выбора определенного порядка интерпретации адресов, который базируется на понятии "адресная схема". Идентификатор схемы стоит перед остатком адреса, отделен от него двоеточием и определяет порядок интерпретации остатка.
Полнота и читаемость порождали коллизию, связанную с тем, что в некоторых схемах используется двоичная информация. Эта проблема была решена за счет формы представления такой информации. Символы, которые несут служебные функции, и двоичные данные отображаются в URI в шестнадцатеричном коде и предваряются символом «%».
Прежде, чем рассмотреть различные схемы представления адресов, приведен пример простого адреса URI:
http://polyn.net.kiae.su/polyn/index.html
Перед двоеточием стоит идентификатор схемы адреса – «http». Это имя отделено двоеточием от остатка URI, который называется «путь». В данном случае путь состоит из доменного адреса машины, на которой установлен сервер HTTP и пути от корня дерева сервера к файлу «index.html».
Кроме представленной выше полной записи URI, существует упрощенная. Она предполагает, что к моменту ее использования многие параметры адреса ресурса уже определены (протокол, адрес машины в сети, некоторые элементы пути). При таких предположениях автор гипертекстовых страниц может указывать только относительный адрес ресурса, т.е. адрес относительно определенных базовых ресурсов.
3.5.6.2. Схемы адресации ресурсов Internet
В RFC-1630 рассмотрено 8 схем адресации ресурсов Internet и указаны две, синтаксис которых находится в стадии обсуждения.
Схема HTTP. Это основная схема для WWW. В схеме указывается ее идентификатор, адрес машины, TCP-порт, путь в директории сервера, поисковый критерий и метка. Приведем несколько примеров URI для схемы HTTP:
http://polyn.net.kiae.su/polyn/manifest.html
Это наиболее распространенный вид URI, применяемый в документах WWW. Вслед за именем схемы (http) следует путь, состоящий из доменного адреса машины и полного адреса HTML-документа в дереве сервера HTTP.
В качестве адреса машины допустимо использование и IP-адреса:
http://144.206.160.40/risk/risk.html
Если сервер протокола HTTP запущен на другой, отличный от 80 порт TCP, то это отражается в адресе:
http://144.206.130.137:8080/altai/index.html
При указании адреса ресурса возможна ссылка на точку внутри файла HTML. Для этого вслед за именем документа может быть указана метка внутри документа:
http://polyn.net.kiae.su/altai/volume4.html#first
Символ "#" отделяет имя документа от имени метки. Другая возможность схемы HTTP - передача параметров. Первоначально предполагалось, что в качестве параметров будут передаваться ключевые слова, но, по мере развития механизма СGI-скриптов, в качестве параметров стала передаваться и другая информация.
http://polyn.net.kiae.su/isindex.html?keyword1+keyword2
В данном примере предполагается, что документ «isindex.html» - документ с возможностью поиска по ключевым словам. При этом в зависимости от поисковой машины (программы, реализующей поиск) знак «+» будет интерпретироваться либо как «AND», либо как «OR». Вообще говоря, «+» заменяет « » (пробел) и относится к классу неотображаемых символов. Если необходимо передать такой символ в строке параметров, то следует передавать в шестнадцатеричном виде его ASCII-код.
http://polyn.net.kiae.su/isindex.html?keyword1%20keyword2
В данном случае имеется один параметр, в котором два слова разделены пробелом. Символ "%" обозначает начало ASCII-кода, который продолжается до первого символа, отличного от цифры.
При использовании HTML Forms параметры передаются как поименованные поля:
http://polyn.net.kiae.su/isindex.html?field1=value1+field2=value
Значения "field1" и "field2" - это имена полей, а "value1" и "value" - их значения. При этом приведенному выше URI может соответствовать следующая HTML-форма:
<FORM ACTION=http://polyn.net.kiae.su/cgi-bin/test>
Введите значения полей:<BR>
Поле "field1":<INPUT NAME="filed1" VALUE="value1"><BR>
Поле "field2":<INPUT NAME="field2" VALUE="value2"><BR>
<HR>
</FORM>
Схема FTP. Данная схема позволяет адресовать файловые архивы FTP из программ-клиентов World Wide Web. При этом программа должна поддерживать протокол FTP. В данной схеме возможно указание не только имени схемы, адреса FTP-архива, но и идентификатора пользователя и даже его пароля. Наиболее часто данная схема используется для доступа к публичным архивам FTP:
ftp://polyn.net.kiae.su/pub/0index.txt
В данном случае записана ссылка на архив «polyn.net.kiae.su» c идентификатором «anonymous» или «ftp» (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
ftp://nobody:password@polyn.net.kiae.su/users/local/pub
В данном случае эти параметры отделены от адреса машины символом «@», а друг от друга двоеточием. В некоторых системах можно указать и тип передаваемой информации, но данная возможность не стандартизирована. Стандарт рекомендует определять тип по характеру данных (текстовая информация - ASCII, двоичная - IMAGE). Следует также учитывать, что употребление идентификатора пользователя и его пароля не рекомендовано, т.к. данные передаются незашифрованными и могут быть перехвачены. Реальная защита в WWW осуществляется другими средствами и построена на других принципах.
Схема Gopher. Данная схема используется для ссылки на ресурсы распределенной информационной системы Gopher. Схема состоит из идентификатора и пути, в котором указывается адрес Gopher-сервера, тип ресурса и команда Gopher.
gopher://gopher.kiae.su:70:/7/kuku
В данном примере осуществляется доступ к gopher-серверу gopher.kiae.su через порт 70 для поиска (тип 7) слова «kuku». Следует заметить, что gopher-тип, в данном случае 7, передается не перед командой, а вслед за ней.
Схема MAILTO. Данная схема предназначена для отправки почты по стандарту RFC-822 (стандарт почтового сообщения). Общий вид схемы выглядит как:
mailto:paul@quest.polyn.kiae.su
Схема NEWS. Данная схема используется для просмотра сообщений системы Usenet. Для этой схемы используется следующая нотация:
news:comp.infosystems.gopher
В данном случае можно получить статьи из группы «comp.infosystems.gopher» в режиме уведомления. Можно получить и текст статьи, но в этом случае указывают ее идентификатор:
news:086@comp.infosystems.gopher
Заказана 86 статья из группы.
Схема NNTP. Это еще одна схема получения доступа к ресурсам Usenet. В данной схеме обращение к группе comp.infosystems.gopher для получения статьи 86 будет выглядеть так:
nntp:comp.infosystems.gopher/086
Следует обратить внимание на то, что адрес сервера Usenet не указан. Программа-клиент должна быть предварительно сконфигурирована на работу с одним из серверов Usenet. Сама служба Usenet является распределенным информационным ресурсом, и группа comp.infosystems.gopher на сервере в домене kiae.su или где-либо еще в мире содержит одни и те же сообщения.
Схема TELNET. По этой схеме осуществляется доступ к ресурсу в режиме удаленного терминала. Обычно клиент вызывает дополнительную программу для работы по протоколу telnet. При использовании этой схемы необходимо указывать идентификатор пользователя, допускается использование пароля. Реально, доступ осуществляется к публичным ресурсам, и идентификатор и пароль являются общеизвестными, например, их можно узнать в базах данных Hytelnet.
telnet://guest:password@apollo.polyn.kiae.su
Схема WAIS. WAIS - распределенная информационно-поисковая система. Она работает в двух режимах: поиска и просмотра. При поиске используется форма со знаком «?», отделяющим адресную часть от ключевых слов:
wais://wais.think.com/wais?guide
В данном случае обращаются к базе данных wais на сервере wais.think.com с запросом на поиск документов со словом guide. Сервер должен вернуть клиенту список документов. После получения этого списка можно использовать вторую форму схемы wais - запрос на просмотр документа:
wais://wais.think.com/wais/wtype/039=/kuku/kuku.txt
039 - это идентификатор документа. Следует заметить, что не все клиенты умеют работать с этой схемой, и в ряде случаев следует пользоваться другими средствами. Схема wais хороша там, где надо обслуживать постоянно действующий запрос, который неизменен на протяжении длительного времени, но при этом выдает свежие документы.
Схема FILE. WWW-технология используется как в сетевом, так и в локальном режимах. Для локального режима используют схему FILE.
file:///C|/text/html/index.htm
В данном примере приведено обращение к локальному документу на персональном компьютере с MS-DOS или MS-Windows. Следует заметить, что данная схема не может быть применена к CGI-скриптам. Очень часто, однако, пользователи пытаются применить file к скрипту, что является ошибкой. Любой скрипт может быть запущен только сервером HTTP, т.к. ему надо передавать параметры и данные. Клиент запускает только программы просмотра на основе MIME-типов из заголовка сообщений сервера или по расширению файла.
Существует еще несколько схем. Эти схемы практически не используются или находятся в стадии разработки, поэтому останавливаться на них мы не будем.
Из приведенных выше примеров видно, что спецификация адресов ресурсов URI является довольно общей и позволяет проидентифицировать практически любой ресурс Internet. При этом число ресурсов может расширяться за счет создания новых схем. Они могут быть похожими на существующие, а могут и отличаться от них. Реальный механизм интерпретации идентификатора ресурса, опирающийся на URI, называется URL, и пользователи WWW имеют дело именно с ним.
3.5.7. Common Gateway Interface - средство расширения возможностей технологии World Wide Web
Спецификация CGI была разработана в Центре Суперкомпьютерных Приложений Университета штата Иллинойс (NCSA). Работы над ней велись параллельно с Mosaic. С точки зрения общей архитектуры программного обеспечения World Wide Web, CGI определила все дальнейшее развитие системных средств. До появления этой спецификации все новые возможности реализовывались в виде модулей, включенных в библиотеку общих кодов ЦЕРН. Разработчики серверов должны были использовать эти коды для реализации программ или заменять их своими собственными аналогами. Это означало, что после компиляции сервера добавить в него новые возможности будет невозможно. CGI в корне изменила эту практику.
Главное назначение Common Gateway Interface - обеспечение единообразного потока данных между сервером и прикладной программой, которая запускается из-под сервера. CGI определяет протокол обмена данными между сервером и программой. Для тех, кто знаком с протоколом HTTP, может показаться, что CGI - это просто подмножество этого протокола. Однако это не так. Во-первых, CGI определяет порядок взаимодействия сервера с прикладной программой, в котором сервер выступает инициирующей стороной, во-вторых, CGI определяет механизм реального обмена данными и управляющими командами в этом взаимодействии, что не определено в HTTP. Естественно, что такие понятия, как метод доступа, переменные заголовка, MIME, типы данных, заимствованы из HTTP и делают спецификацию прозрачной для тех, кто знаком с самим протоколом.
При описании различных программ, которые вызываются сервером HTTP и реализованы в стандарте CGI, используют следующую терминологию:
CGI-скрипт - программа, написанная в соответствии со спецификацией Common Gateway Interface. CGI-скрипты могут быть написаны на любом языке программирования (C, C++, PASCAL, FORTRAN и т.п.) или командном языке (shell, cshell, командный язык MS-DOS, Perl и т.п.). Скрипт может быть написан даже на языке редактора EMAC в системах Unix.
Шлюз - это CGI-скрипт, который используется для обмена данными с другими информационными ресурсами Internet или приложениями-демонами. Обычная CGI-программа запускается сервером HTTP для выполнения некоторой работы, возвращает результаты серверу и завершает свое выполнение. Шлюз выполняется точно также, только, фактически, он инициирует взаимодействие в качестве клиента с третьей программой. Если эта третья программа является сервисом Internet, например, сервер Gopher, то шлюз становится клиентом Gopher, который посылает запрос по порту Gopher, а после получения ответа пересылает его серверу HTTP.
Аналогично происходит взаимодействие с серверами распределенных баз данных, например, Oracle.
3.5.7.1. Механизмы обмена данными
Собственно спецификация CGI описывает четыре набора механизмов обмена данными:
· через переменные окружения;
· через командную строку;
· через стандартный ввод;
· через стандартный вывод.
Переменные окружения. При запуске внешней программы сервер создает специфические переменные окружения, через которые передает приложению как служебную информацию, так и данные. Все переменные можно разделить на общие переменные окружения, которые генерируются при любой форме запроса, и запрос-ориентированные переменные.
К общим переменным окружения относятся:
· SERVER_SOFTWARE - определяет имя и версию сервера.
· SERVER_NAME - определяет доменное имя сервера.
· GATEWAY_INTERFACE - определяет версию интерфейса.
К запрос-ориентированным относятся:
· SERVER_PROTOCOL - протокол сервера. Вообще говоря, CGI разрабатывалась не только для применения в World Wide Web с протоколом HTTP, но и для других протоколов также, но широкое применение получила только в WWW.
· SERVER_PORT - определяет порт TCP, по которому осуществляется взаимодействие. По умолчанию для работы по HTTP используется 80 порт, но он может быть и переназначен при конфигурировании сервера.
· REQUEST_METHOD - определяет метод доступа к информационному ресурсу. Это важнейшая переменная в CGI. Разные методы доступа используют различные механизмы передачи данных. Данная переменная может принимать значения GET, POST, HEAD и т. п.
· PATH_INFO - передает программе путь, часть спецификации URL, в том виде, в котором она указана в клиентом. Реально это означает, что передается путь (адрес скрипта) в виде, указанном в HTML-документе.
· PATH_TRANSLATED - то же самое, что и PATH_INFO, но только после подстановки сервером определенных в его конфигурации вставок. Дело в том, что при конфигурировании сервера некоторым элементам (ветвям) дерева файловой системы можно назначить синонимы. Типичным примером такого сорта является назначение типа:
cgi-bin ------------> /usr/local/etc/httpd/cgi-bin
В данном случае справа указано стандартное место CGI скриптов для сервера NCSA, а слева - его синоним. При получении скриптом test управления, в переменной окружения PATH_INFO будет значение:
"/cgi-bin/test", а в PATH_TRANSLATED -
"/usr/local/etc/httpd/cgi-bin/test".
· SCRIPT_NAME - определяет адрес скрипта так, как он указан клиентом. Если не указаны параметры, то значение этой переменной будут совпадать с PATH_INFO, но если переменные указаны, то все, что следует за знаком «?» будет отброшено.
PATH_INFO ----------> "/cgi-bin/search?nuclear+isotop"
SCRIPT+NAME --------> "/cgi-bin/search"
· QUERY_STRING - переменная определяет содержание запроса к скрипту. Чрезвычайно важна при использовании метода доступа GET. Возвращаясь к примеру с адресами скрипта укажем, что в QUERY_STRING помещается все, что записано после символа «?».
QUERY_STRING -------> "nuclear+isotop"
При этом никакого преобразования строки запроса сервером не производится. Все манипулирования с содержанием QUERY_STRING возложены на скрипт.
Следующий набор переменных связан с идентификацией пользователя и его машины:
· REMOTE_HOST - доменный адрес машины, с которой осуществляется запрос.
· REMOTE_ADDR - IP-адрес запрашивающей машины.
· AUTH_TYPE - тип идентификации пользователя. Используется в случае, если скрипт защищен от несанкционированного использования.
· REMOTE_USER - используется для идентификации пользователя.
· REMOTE_IDENT - данная переменная порождается сервером, если он поддерживает идентификацию пользователя по протоколу RFC-931. Рекомендовано использование этой переменной для первоначального использования скрипта.
Следующие две переменные определяют тип и длину передаваемой информации от клиента к серверу.
· CONTENT_TYPE - определяет MIME-тип данных, передаваемых скрипту. Используя эту переменную можно одним скриптом обрабатывать различные форматы данных.
· CONTENT_LENGTH - определяет размер данных в байтах, которые передаются скрипту. Данная переменная чрезвычайно важна при обмене данными по методу POST, т.к. нет другого способа определить размер данных, которые надо прочитать со стандартного ввода.
Возможна передача и других переменных окружения. В этом случае перед именем указывается префикс «HTTP_». Отдельный случай представляют переменные, порожденные в заголовке HTML-документа в тагах META. Они передаются в заголовке сообщения, и некоторые серверы могут порождать переменные окружения из этих полей заголовка.
Опции командной строки. Командная строка используется только при запросах типа ISINDEX. При HTML FORMS или любых других запросах неопределенного типа командная строка не используется. Если сервер определил, что к скрипту обращаются через ISINDEX-документ, то поисковый критерий выделяется из URL и преобразуется в параметры командной строки. При этом знаком разделения параметров является символ «+». Тип запроса определяется по наличию или отсутствию символа «=» в запросе. Если этот символ есть, то запрос не является запросом ISINDEX, если символа нет, то запрос принадлежит к типу ISINDEX. Параметры, выделенные из запроса, помещаются в массив параметров командной строки argv. При этом после из выделения происходит преобразование всех шестнадцатеричных символов в их ASCII-коды. Если число параметров превышает ограничения, установленные в командном языке, например в shell, то формирования командной строки не происходит и данные передаются только через QUERY_STRING. Вообще говоря, следует заранее подумать об объеме данных, передаваемом скрипту и выбрать соответствующий метод доступа. Размер переменных окружения тоже ограничен, и если необходимо передавать много данных, то лучше сразу выбрать метод POST, т.е. передачу данных через стандартный ввод.
Формат стандартного ввода. Стандартный ввод используется при передаче данных в скрипт по методу POST. Объем передаваемых данных задается переменной окружения CONTENT_LENGTH, а тип данных - переменной CONTENT_TYPE. Если из HTML-формы надо передать запрос типа: a=b&b=c, то CONTENT_LENGTH=7, CONTENT_TYPE=application/x-www-form-urlencoded, а первым символом в стандартном вводе будет символ «а». Следует всегда помнить, что конец файла сервером в скрипт не передается, а поэтому завершать чтение следует по числу прочитанных символов. Позже мы разберем примеры скриптов и обсудим особенности их реализации в разных операционных системах.
Формат стандартного вывода. Стандартный вывод используется скриптом для возврата данных серверу. При этом вывод состоит из заголовка и собственно данных. Результат работы скрипта может передаваться клиенту без каких-либо преобразований со стороны сервера, если скрипт обеспечивает построение полного HTTP-заголовка, в противном случае сервер заголовок модифицирует в соответствии со спецификацией HTTP. Заголовок сообщения должен отделяться от тела сообщения пустой строкой. Обычно в скриптах указывают только три поля HTTP-заголовка:
Content-type, Location, Status.
Content-type указывается в том случае, когда скрипт сам генерирует документ «на лету» и возвращает его клиенту. В этом случае реального документа в файловой системе сервера не остается. При использовании такого сорта скриптов следует учитывать, что не все серверы и клиенты отрабатывают так, как представляется разработчику скрипта. Так, при указании Content-type: text/html, некоторые клиенты не реализуют сканирования полученного текста на предмет наличия в нем встроенной графики. Обычно в Content-type указывают текстовые типы text/plain и text/html.
Location используется для переадресации. Иногда переадресация помогает преодолеть ограничения сервера или клиента на обработку встроенной графики или серверной предобработки. В этом случае скрипт создает файл на диске и указывает его адрес в Location. Сервер, таким образом, передает реально существующий файл. В последнее время серверы стали буферизовать возвращаемые клиентам данные, что приводит к решению вопросов, связанных с повторным запуском скриптов для встраивания графики и разгрузки компьютера с сервером HTTP.
3.5.7.2. Практика применения скриптов CGI
Применение скриптов широко практикуется в WWW. При их помощи, например, реализованы стеки графических гипертекстовых ссылок, встраивание даты в текст документов, встраивание ответов службы finger, доступ к базам данных и многое другое. Мы рассмотрим простейшие скрипты для распечатки параметров, передаваемых сервером, скрипты по обращению к shell, С скрипты, скрипты доступа к системе управления базами данных ingres и скрипт imagemap.
Простейшие скрипты и преобразование информации. Обсуждение начнем со скриптов, написанных на командном языке SHELL. Самый простой из них будет выглядеть как:
#!/bin/sh
echo Content-type: text/plain
echo
echo This is the result of script execution.
#The end of script
Первая строка определяет, что в качестве интерпретатора скрипта будет использован shell, вторая строка открывает заголовок сообщения, передаваемого скриптом серверу, и определяет тип передаваемой информации как обычный текст. Третья строка отделяет тело сообщения от его заголовка. В теле сообщения передается фраза из четвертой строки. Именно она и будет отображаться программой-интерфейсом пользователя.
В качестве следующего примера приведем скрипт, который отображает значения переменных окружения:
#!/bin/sh
echo Content-type: text/plain
echo
echo $REQUEST_METHOD
echo $QUERY_STRING
echo $CONTENT_TYPE
echo $CONTENT_LENGTH
#The end of script.
В данном скрипте пользователю будут возвращены значения указанных в строках команды echo переменных окружения.
Пользователю можно вернуть не только значения переменных окружения, но и результаты выполнения команд.
#!/bin/sh
echo Content-type: text/plain
echo
finger paul@polyn.kiae.su
#The end of script.
В результате выполнения этого скрипта пользователь получит информацию о пользователе paul с машины polyn.kiae.su.
Завершим обзор простейших скриптов небольшой программой на С:
#include <stdlib.h>;
#include <sys/types.h>;
main()
{
long i,n,uid;
char input_ch[1024];
char *env;
env = getenv("CONTENT_LENGTH"); /* Here we recieve a length */
sscanf(env,"%d",&n); /* of input stream and form */
for(i=0;i<;n;i++) /* command line */
{ input_ch[i] = getchar(); }
input_ch[i] = '\000';
printf("Content-type: text/html\n\n"); /* First message of a CGI Programme*/
/* This message must be a first one*/
/* in output sream. */
printf("<TITLE> C-cgi script.(example#1)</TITLE>\n");
printf("<H3><I> Russian Research Center \"Kurchatov Institute\"<I></H3>\n");
c_uid = -1;
sscanf(input_ch,"uid=%ld",&uid); /* Transform input data */
printf("Input Nuber:%ld.<BR><HR>",uid);
exit(0);
}
В приведенном выше примере программа получает данные через стандартный ввод. Это значит, что используется метод доступа POST. Число получаемых байтов указывается в переменной окружения CONTENT_LENGTH. Следует обратить внимание на то, что первой строкой записи в стандартный вывод является строка, определяющая тип информации. В данном случае он определен как текст HTML. Важно также отметить, что в этом операторе вывод завершается двумя переводами на новую строку, т.к. пустая строка должна разделять заголовок и тело сообщения, возвращаемого серверу. Остальные операторы выводят данные в виде HTML-предложений, формируя HTML-документ.
При написании скриптов следует учитывать то, что сервер обычно стартует в момент, когда не все пути могут быть определены, поэтому при обращении к ресурсам следует указывать полные пути для этих ресурсов.
Доступ к базе данных под управлением Ingres. Система управления базами данных Ingres является одной из популярных CУБД, работающих в среде операционной системы UNIX. Использование технологии разработки CGI-скриптов помогает построить современный дружественный интерфейс для пользователей WWW к базам данных под управлением данной СУБД. Начнем обсуждение этой возможности с простейших способов обращения с СУБД.
#!/bin/sh
echo Content-type: text/plain
echo
ingres polyn < query
#The end of script
В данном случае запрос заранее подготовлен в виде файла query. Скрипт не получает данных из интерфейсной программы, и действует по жесткой схеме запроса. Аналогично можно вызвать скрипт, выполняющий утилиты Ingres:
#!/bin/sh
echo Content-type: text/plain
echo
helpr polyn
#The end of script
В данном случае скрипт возвращает справку по базе данных polyn.
Естественно, что можно использовать не только тип text/plain, но и text/html. Пример такого использования приведен ниже:
#!/bin/sh
echo Content-type: text/html
echo
echo '< PRE> '
helpr polyn situat
echo '< /PRE> '
#The end of script
Выполнение жестких запросов не очень интересно для пользователя. Он обычно жаждет сформулировать свой собственный запрос. В следующем примере скрипту передается запрос методом доступа GET, который помещен в переменную окружения QUERY_STRING:
#!/bin/sh
echo Content-type: text/html
echo
echo '< PRE> '
echo $QUERY_STRING | tr "+" " " | ingres polyn
echo '< /PRE> '
#The end of script
Прежде всего, данные посылаются на предобработку, т.к. все пробелы в запросе заменяются на знак «+» в соответствии с правилами HTTP. После этого фильтра данные поступают на стандартный ввод интерпретатора Ingres и результат работы возвращается пользователю.
Вообще говоря необходима фильтрация и на выходе после Ingres, т.к. вывод содержит неотображаемые символы, например символ '/007', который лучше заменить на что-нибудь отображаемое.
Отчеты могут быть достаточно большими, поэтому имеет смысл ограничить отчет определенным числом строк:
#!/bin/sh
echo Content-type: text/html
echo
echo '< PRE> '
echo $QUERY_STRING | sed -f symbols | ingres polyn | tr "\007" "*" | head 100
echo '< /PRE> '
#The end of script
В данном случае размер отчета ограничен 100 записями. Обратите внимание, в качестве фильтра используется sed, который выполняет правильное преобразование символов из формата HTTP в обычный ASCII. При формировании файла symbols (правила преобразования) следует помнить о порядке выполнения правил преобразования.
Одним из недостатков приведенных выше скриптов является невозможность или достаточно большая сложность преобразования выходной информации Ingres. Если необходимо получить отчет со встроенными в его текст ссылками и картинками, то лучше использовать универсальный язык программирования, например, С.
Программирование на С с использованием EQUEL (препроцессор для доступа к Ingres) позволяет аккуратно разобрать входные данные и построить сложный гипертекстовый отчет. На рисунке 3.29 приведен пример интерфейсной формы.
|
|
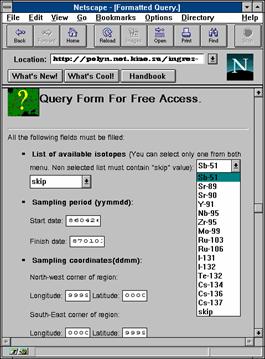
Рис. 3.29.
Результат выполнения скрипта приведен на рисунке 3.30:
|
|
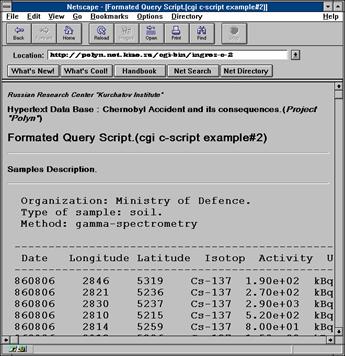
Рис. 3.30.
Работа со скриптом imagemap. Скрипт imagemap был разработан для организации доступа к документам по графическим гипертекстовым ссылкам. В общем случае это значит, что в текст HTML-документа встроена картинка. Данная картинка разбита на непересекающиеся области различной формы, обычно круги, прямоугольники или полигоны. С каждой из этих областей связан какой-либо объект (HTML-документ, другая картинка, фильм и т.п.). Выбирая мышью точку на этой картинке, пользователь выбирает объект, связанный с областью, которой принадлежит точка объекта и переходит к просмотру этого объекта. Например, на экране пользователя отображена Европейская часть территории Союза с административными границами республик. Выбирая точку внутри административных границ России, можно получить укрупненную карту европейской части России.
Некоторые HTTP-серверы реализуют функции imagemap самостоятельно, но чаще всего в Сети используют отдельный скрипт. Рассмотрим применение данного скрипта для сервера NCSA. Программа imagemap размещается в директории скриптов, обычно это: «/usr/local/etc/httpd/cgi-bin». В директории «/usr/local/etc/httpd/conf» размещается файл конфигурации скрипта. Для каждой картинки создается еще и файл разбиения картинки на области, адрес которого указывается в конфигурации скрипта.
Для организации стека графических ссылок в документе HTML используют следующую конструкцию:
<A href="http://polyn.net.kiae.su/cgi-bin/imagemap/russia">
<IMG SRC="http://demin.polyn.kiae.su/dss/russia.gif" ISMAP>
</A>
Таким образом, URL скрипта imagemap в качестве последнего компонента пути содержит аргумент, в данном случае "russia". При использовании этой гипертекстовой ссылки программа-клиент добавляет после слова "russia" последовательность типа “?14,25”. Первая цифра определяет координату X на картинке относительно левого ее края, а вторая цифра - координату Y относительно верхнего края картинки. При вызове скрипт ищет свой файл конфигурации, который имеет вид:
# метка : адрес файла описания картинки
russia : /usr/local/etc/httpd/cgi-bin/maps/russia.map
brussia : /usr/local/etc/httpd/cgi-bin/maps/brussia.map
....
Таким образом, для каждого вызова imagemap определяется описание разбивки картинки на непересекающиеся области. Каждый файл описания такой области может содержать три вида описаний: прямоугольной области, круговой области и полигона. Прямоугольник задается двумя углами: верхним левым и нижним правым, круг - центром и точкой на окружности, полигон - вершинами своих углов. При этом полигон рассматривается как замкнутый многоугольник, который может быть и невыпуклым. В качестве примера такого описания можно рассмотреть следующую запись:
#описание прямоугольника
rect 10 20 100 200
circle 50 50 60 60
poly 10 10 20 20 20 10
Практически все программы imagemap имеют ограничения на число вершин полигона, так для MS-Windows 3.1 ограничение равно 100 точкам.
Для разметки картинок используются специальные вспомогательные программы типа mapedit, которые позволяют сделать процесс разбивки картинки более наглядным и менее трудоемким.
Общей проблемой, связанной с использованием скриптов, является проблема безопасности. Во-первых, скрипты обычно не пишут сами, как, например, скрипт imagemap, а заимствуют. Понятно, что чужая программа может содержать ошибки. Поэтому лучше пользоваться библиотеками проверенных скриптов, которые рекомендованы, например, World Wide Web Consortium. Во-вторых, если пользователю разрешено иметь свои страницы, то он может получить возможность выполнять свои скрипты на сервере, что тоже приводит к брешам в системе безопасности, особенно если это shell-скрипты. Существуют такие скрипты, которые требуют прав доступа к ресурсам машины. Эти права шире, чем права пользователя "nobody", например, при доступе к базам данных. Все эти моменты следует учитывать, как при написании скриптов, так и при разрешении использования различным группам пользователей.
Как правило, новые возможности WWW опробуются на скриптах, а затем, если эти возможности широко используются в практике, они включаются в стандарты различных компонентов системы и могут быть реализованы в новых возможностях серверов, как например imagemap и системы безопасности. Скрипты позволяют новым энтузиастам Сети приобщиться к сообществу и внести свою лепту в развитие системы.
3.5.8. Выбор и установка сервера протокола HTTP и другого программного обеспечения базы данных World Wide Web
Как уже было сказано выше, сервер World Wide Web - это программа, обслуживающая запросы клиентов по протоколу HTTP. Иногда серверами WWW называют и другие программы, например, поисковые машины Wide Area Information Server. Но это слишком вольное толкование понятия WWW сервера. Главной задачей сервера «паутины» является обеспечение доступа пользователей к базе данных HTML документов. Однако, в настоящее время функциональные возможности серверов значительно расширились и вышли за пределы простой отсылки документов на запросы клиентов. Наиболее типичными для современных серверов являются следующие функции:
· ведение иерархической базы данных документов,
· контроль за доступом к информации со стороны программ-клиентов,
· предварительная обработка данных перед ответом на запрос,
· взаимодействие с внешними программами через Common Gateway Interface,
· реализация взаимодействия с клиентами и другими серверами в режиме посредника,
· реализация встроенных или взаимодействие с внешними поисковыми машинами.
Кроме того, такие серверы как NetSite (Netscape Communication) и Apachie реализуют шифрованные протоколы HTTP для обмена информацией с клиентами. Рассмотрение перечисленных свойств и функций WWW серверов полезно провести на примерах, основанных на практике эксплуатации серверов NCSA httpd, CERN httpd, Winhttpd и WN, Apachie.
3.5.8.1. Структура базы данных сервера WWW
Итак первой основной задачей для любого сервера является ведение его базы данных. База данных сервера - это часть файловой системы, отведенная для размещения файлов HTML документов. Большинство современных файловых систем - это иерархические деревья, следовательно, и база данных HTTP сервера также является таким деревом. Для любой базы данных необходимо ввести понятие единицы хранения - минимальный объект, к которому можно обратиться извне или получить в качестве ответа на запрос. Стандартным объектом хранения в базе данных HTTP сервера является HTML документ, который является обычном текстовым файлом. Кроме такого стандартного объекта многие серверы поддерживают различные комбинированные объекты хранения, создаваемые в ряде случаев из нескольких файлов или генерируемые программами «на лету».
Если обратиться к терминологии, которая принята в системах World Wide Web, то можно выделить следующие основные объекты, с которыми оперирует сервер и программа-клиент:
Страница базы данных World Wide Web - это законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу World Wide Web по универсальному идентификатору этого ресурса (URI, URL).
База данных World Wide Web или Website - набор страниц базы данных world Wide Web. При более подробном рассмотрении Website - это вся совокупность данных и программного обеспечения, обеспечивающая отображение страниц информационной базы данных World Wide Web.
Если страница Website представляет из себя обычный файл в стандарте HTML, то тогда говорят об элементарном или стандартном элементе хранения. В этом случае URL указывает непосредственно на этот файл, и сервер просто отправляет его в ответ на запрос пользователя.
Многие страницы, как это было показано в разделе, посвященном языку HTML, содержат внутри себя контейнеры-формы, которые служат для передачи информации от программы клиента программе-серверу. В рамках данного рассмотрения эти страницы выделены в особую группу страниц World Wide Web.
Страницей-формой будем называть в данном контексте файл в формате HTML, который содержит в себе HTML-форму.
После обращения к странице-форме, как правило, следует вызов либо API-модуля, встроенного в сервер, либо CGI-программы. В свою очередь такое действие вызывает генерацию этим модулем или программой виртуальной страницы.
Виртуальной страницей Website будем называть страницу, которая в виде файла в файловой системе сервера не существует. Данная страница появляется только в момент обращения клиента к серверу.
Один из способов генерации виртуальной страницы - это генерация при помощи API-модуля или CGI-программы. При этом весь текст страницы может порождаться программой, либо для генерации могут использоваться файлы-заготовки. Генерируют не только текстовые файлы, но и графику. Одним из наиболее популярных способов генерации документов является обращение к стекам гипертекстовых ссылок и системам управления универсальными базами данных(СУБД).
Второй способ генерации виртуальной страницы - это генерация такой страницы сервером. В данном случае в тело документа и файлы описания иерархии документов сервера включаются команды преобразования документов. Сервер может, в общем случае, производить условную генерацию документов на основе информации, полученной от программы-клиента.
Другим типом объекта, который хранится в Website, являются страницы в формате Virtual Reality Modeling Language(VRML). VRML-страница - это такой же объект, как и обычные страницы Website, только написанная на другом языке. К VRML-страница можно применять те же механизмы генерации, что и к страницам HTML.
Java-applet - это мобильный код, сгененрированный компилятором applet’ов. Applet’ы составляют в базе данных Website отдельную директорию в файловой системе сервера. В страницы HTML встраиваются специальные контейнеры applet’ов, которые позволяют программе-клиенту распознавать наличие applet’а и подгружать его в качестве части страницы.
|
|
Рис. 3.31. Структура базы данных и программного обеспечения Website
Как видно из рисунка 3.31, кроме перечисленных выше компонентов, базу данных Website составляют еще и другие файлы. Главным образом, это файлы графических и мультимедийных форматов. Для просмотра этих файлов программа-клиент должна уметь запускать либо внешнюю программу, либо plug-ins, т.е. программу, которая отображает файл графического или мультимедийного формата внутрь рабочей области программы-клиента.
Совершенно очевидно, что для создания всего этого многообразия файлов и компонентов Website необходимо программное обеспечение, которое не входит в стандартный набор, представленный на рисунке 3.31. Самый минимальный набор инструментов, который необходим для поддержания страниц базы данных, можно определить следующим образом:
· Редактор файлов формата HTML.
· Графический редактор, сохраняющий файлы в форматах GIF, в том числе и версии GIF89A, и JPEG.
· Редактор файлов формата MPEG.
· Редактор файлов VRML.
· Редактор аудиофайлов.
· Компилятор байткода Java.
· и др.
Кроме прочего, для того, чтобы тестировать страницы, необходимо иметь версии клиентского программного обеспечения различных производителей и различных версий. Определить, какие именно программы и их версии необходимы, можно по файлу статистики сервера. Позже будет рассказано, как это сделать.
В рамках данного курса мы не будем останавливаться подробно на всех этих типах программных продуктов, так как это предмет отдельного курса, но об основных из них - редакторах HTML-документов и редакторах графических файлов, имеет смысл поговорить более детально.
3.5.8.2. Редакторы HTML-документов
Самое простое решение проблемы создания HTML-документов - это использование простого текстового редактора, который вообще не ориентирован на разработку HTML-документов. Именно эта возможность и обеспечила первичную популярность World Wide Web. Многие ветераны до сих пор считают, что это наиболее гибкий способ разработки документов, т.к. специализированные редакторы не реализуют всех возможностей HTML или реализуют их крайне неэффективно, однако, если производство документов необходимо поставить на поток, и при этом разрабатывать их будет неискушенный в языке оператор, то подбор редактора, который автоматизирует ряд процедур разработки документа, становится актуальной задачей.
Любопытно, что большинство систем разметки гипертекстовых документов в настоящее время реализованы для персональных компьютеров с операционными системами Windows 3.x или Windows`95. Из прочих операционных сред можно выделить только IRIX, в рамках которого SGI предложила несколько типовых решений для организации как Website, так и рабочего места разработчика Website.
Все программы подготовки страниц можно разбить на следующие группы:
· специализированные редакторы HTML,
· дополнения к существующим текстовым редакторам для расширения их возможностей,
· программы конверторы из/в HTML и специализированные средства разработки отдельных компонент страниц или специальных страниц (графические редакторы, мультипликаторы, аудио рекордеры и т.п.).
В последнее время стали появляться не просто коммерческие средства подготовки HTML-страниц, а завершенные программные комплексы, оптимизированные под определенную платформу, как, например, система WebMagic Author, которая входит в комплект WebForce компании Silicon Graphic. Начнем обзор средств подготовки Web-страниц c редакторов HTML. Все редакторы можно разделить на коммерческие и свободно-распространяемые, а также на обычные и WYSIWYG.
Коммерческие редакторы продаются и стоят около 100$ за одну установку. Как правило, можно скопировать редактор по Internet и пользоваться им втечение 30 дней бесплатно, а за тем уже решать вопрос о его приобретении. Готовя этот обзор, я воспользовался этой возможностью и поработал с HotDog, HotMеtal, HTMLedit Pro, HTML Writer и рядом других редакторов, для того, чтобы составить свое собственное мнение о возможностях современных средств подготовки HTML-документов, которые занимают первые места в рейтингах иностранных компьютерных журналов и в периодических опросах авторов Web-страниц. В своей повседневной работе я пользуюсь свободно-распространяемой версией HTMLed 1.2 и вполне ей доволен, но признаю, что коммерческие продукты обладают рядом неоспоримых преимуществ, особенно, с точки зрения начинающих пользователей, о чем будет сказано чуть позже. Свободно-распростра-няемые программы - это то, что осталось с тех времен, когда Internet не погрузилась в пучину коммерциализации ее информационных ресурсов. До сих пор существуют добрые люди, которые пишут хорошие программы и раздают их всем желающим. К сожалению их становится все меньше. Среди этих программ следует выделить HTML Writer, HTMLed 1.2e, Web Wizard 16-bit и HotMetal Free.
Магическое слово «WYSIWYG» - означает «What You See Is What You Get», т.е., «Видишь то, что получишь». С этой концепцией построения редакторов текста все пользователи персональных компьютеров знакомы по работе с MS-Word for Windows. Среди HTML-редакторов также есть WYSIWYG редакторы, например, HotDog или TkWWW.
При сравнении различных редакторов зарубежные авторы принимают в расчет обычно следующие показатели: поддержка различных стандартов языка (HTML 3, Netscape Extensions, Microsoft Extensions), наличие специальных средств разработки таблиц, форм и графических стеков гипертекстовых ссылок (imagemap), наличие программ проверки синтаксиса HTML и национальных языков, размер редактируемого файла, наличие режима WYSIWYG, и удобства разработки, в которые включают внешний вид, наличие икон, определяемые пользователем последовательности HTML тегов и т. п. Если первые показатели не вызывают никаких сомнений, то показатель удобства выглядит в этом ряду несколько странно. На мой взгляд, это все ровно, что убеждать эскимоса в том, что рыбу надо есть свежевыловленной, а не с душком. Последнее замечание я сделал только потому, что был чрезвычайно удивлен тем обстоятельством, что первой во всех рейтингах значится коммерческая версия редактора HotDog. Действительно, это очень неплохой редактор, но по количеству действительно полезных функций в тех же рейтингах он уступает, например, редактору HotMetal. Так HotDog не поддерживает контроль синтаксиса HTML, хотя официально заявлено обратное. Для реализации этой возможности требуется загружать дополнительные файлы, которые в дистрибутиве не поставляются. То, что в рейтинге Карла Девиса (Carl Davis, http://www.ccs.org/htmledit/comparetable.html) HotDog и HotMetal соседствуют, можно объяснить вкусом автора рейтинга, однако Строуд (Forrest H. Stroud, http://cws.wilmington.net/html.html) назначил HotMetal три звезды против пяти у HotDog и поставил его на десятое место в общем списке HTML-редакторов после, например, свободно распространяемого редактора HTML Writer, что объяснить объективными показателями сравнения программ просто невозможно. В вину HotMetal вменяется то, что он проверяет синтаксис HTML, а так как HTML 3.0 и другие расширения языка не поддерживаются в качестве стандарта, то редактор терроризирует пользователя предложениями о коррекции ошибок при применении новых тегов. Но если проверка столь назойлива, ее всегда можно отключить и получить обычный редактор. Поэтому я не буду делать выводы о том, что лучше или хуже, а просто постараюсь выделить общие свойства различных редакторов и проиллюстрировать эти возможности примерами.
Прежде, чем говорить о способах редактирования HTML-документов и их реализации в различных редакторах, договоримся о том, что понимается под такого рода редактированием. Создание HTML-документа - это просто набор текста и расстановка внутри него тегов языка HTML. Собственно, набор текста и расстановку тегов можно производить в обычном текстовом редакторе вручную. В этом смысле все HTML-редакторы ни чем не отличаются от MS-Write или Notepad, например. Их особенность как HTML-редакторов заключается в способности автоматизировать процесс разметки, т.е. вставки в текст документа тегов языка HTML. Практически все редакторы позволяют запускать внешнюю программу просмотра, например, Netscape, для тестирования набранного документа, а некоторые из них синхронно отображают набираемый текст и графику, демонстрируя страницу Web в том виде, как ее увидят пользователи World Wide Web на экранах своих компьютеров.
Начнем с очевидных вещей - поддержки HTML тегов и встраивания гипертекстовых ссылок. Эти возможности поддерживаются любым HTML-редактором, будь он коммерческий или свободно-распространяемый. Вся разница состоит только в том, как широк этот набор. Практически, все редакторы поддерживают стандарт HTML 1.0, только очень старые редакторы, чьи коды были написаны в 1994 году, не поддерживают стандарт HTML 2.0, а вот новые стандарты и их вариации не поддерживаются многими редакторами. Так HTML 3.0 и Netscape Extensions не поддерживают HTML Assistant, HTMLed, HTML Writer, TkWWW, Phoenix и многие другие. Правда, следует заметить, что это не такая уж и большая беда. В понятие поддержки возможностей того или иного стандарта языка, обычно, вкладывается наличие специальных позиций в меню редактора, выбирая которые, можно вставлять в текст соответствующие теги. Многие редакторы позволяют организовывать пользовательские списки тегов, а это значит, что автор сам может расширить возможности своего редактора. С гипертекстовыми ссылками ситуация такая же как и с тегами. Авторы обзоров часто относят к достоинству редактора наличие списка ссылок на наиболее популярные страницы Web, который поставляется вместе с программой. Это конечно удобно. Но если автор давно работает с «паутиной», и круг его профессиональных интересов определился, то существуют еще две возможности создания таких списков: конвертирование в формат редактора списка закладок программы просмотра, которой пользуется автор, или свой собственный список, который накопился за время разработки страниц Web. Даже свободно-распространяемая версия HTMLed 1.2e позволяет реализовать оба способа. Графика вставляется в документы аналогично гипертекстовым ссылкам, поэтому отдельно на ее использовании в качестве элемента HTML-разметки останавливаться не будем.
Следующим важным свойством гипертекстовой разметки является разметка таблиц. Таблица довольно сложный объект и от автора требуется достаточно высокая квалификация, чтобы ее реализовать в HTML-документе. Важность таблиц во многом определяется тем, что кроме использования их как собственно таблиц, многие авторы организуют с их помощью многоколоночную разметку, блочную разметку, позиционирование графики относительно текста и ряд других эффектов, которые обычными средствами языка сделать трудно. Для примера можно посмотреть домашние страницы компании Demos (http://www.demos.su/), чтобы убедиться насколько эффективным может быть использование таблиц. Свободно-распространяемые редакторы разметку таблиц не поддерживают, поэтому следует обратится к коммерческим продуктам. Честно говоря, ничего подобного, скажем, таблицам MS-Word ни в одном из HTML-редакторов нет. Правда здесь надо оговориться, что проверить системы типа WebForce у меня возможности не было, а описание WebMagic Author на домашних страницах Silicon Graphic Inc. представления о реализации поддержки таблиц в этой программе не дает. В других же редакторах поддержка таблиц подразумевает вставку в текст документа-шаблона, состоящего из тегов элементов таблицы, которые потом надо заполнять вручную. Если таблица маленькая или ее элементы небольшие, то вся ее структура хорошо видна на экране, и работать с ней достаточно удобно, но если надо организовать многоколоночный текст, то наглядность мишени, которую выдал редактор, быстро теряется, создание таблицы с использованием средств редактора практически не отличается от ручной разметки.
Кроме таблиц важнейшим элементом интерактивных страниц Web являются страницы с формами. Тестируя коммерческие продукты, я ожидал увидеть возможность интерактивного программирования формы, как это давно принято в системах управления базами данных, и с чем впервые познакомился еще при работе с ADABAS NATURAL. Однако ни один из первой пятерки лучших редакторов World Wide Web такой возможностью на настоящий момент не обладает. Все, что можно реально получить - это отдельные элементы формы, которые вставляются в текст документа при выборе соответствующей позиции меню.
Теперь настало время поговорить о возможностях WYSIWYG редактирования. Первым редактором этого типа была программа TkWWW. Она совмещала в себе сразу и редактор, и программу просмотра. Таковой она осталась до сих пор. TkWWW исповедует принцип «Что видишь, то и будет» в классическом смысле этого слова, т.е. так как это делает MS-Word. При наборе текст HTML-документа сразу отображается так, как будто его просматривают программой Mosaic. Но как только необходимо вставить картинку, так сразу становится понятным, что программа не способна в режиме редактирования документа вставлять в него графику. Все картинки заменяются на текст IMAGE, не говоря уже о таблицах и формах. Вообще говоря, классический WYSIWYG не типичен для HTML-редакторов. Обычно программы открывают дополнительное окно, в котором и отображается результат интерпретации HTML-документа, который в данный момент редактируется. Таким образом, на экране одновременно отображаются исходный текст документа, в который автор вносит изменения и его образ после интерпретации программой просмотра. При чем интерпретация происходит синхронно, т.е. при наборе символов в рабочем окне они немедленно появляются в окне отображения. То же самое происходит и с графикой, и с другими элементами документа. Однако, применяя такие встроенные в редактор программы просмотра, всегда следует помнить о том, что другие программы Web, могут отображать документ несколько иначе. Для того, чтобы быть уверенным что 85% всех пользователей Web увидят документ в том же виде, как его видит автор, следует всегда обращаться к услугам внешней программы просмотра, а именно Netscape Navigator. Практически все редакторы эту возможность поддерживают.
Если рассматривать HTML-редактор не только как средство подготовки страниц Web квалифицированным автором, но еще и как средство обучения персонала, то единственным редактором, который полностью поддерживает не только описание себя самого, но и описание различных стандартов языка и приемов разработки страниц является HotDog. В интерактивном руководстве по этому редактору есть не только подробное описание HTML 2.0, HTML 3.0, Netscape Extensions для HTML 2.0 и предложения Netscape в стандарт HTML 3.0, но и описание Microsoft Extensions. Надо отметить, что эти описания составлены гораздо понятнее, чем описания самих разработчиков. Так, например, описание автоматического обновления документов с использованием механизма Refresh, который реализуется не сервером, а документом через конструкцию <META HTTP-EQUIV= «Refresh» ...> в контейнере HEAD документа, сопровождается достаточно ясными примерами, и гораздо прозрачнее для понимания описания этой возможности на домашних страницах Netscape Communication, которая придумала и реализовала эту конструкцию в своей программе просмотра.
Рассматривая различные HTML-редакторы, нельзя не обратить внимание, что подавляющее большинство их разработано для Microsoft Windows. Так один из наиболее представительных списков HTML который опубликован в руководстве «THE WEB DESIGNER», насчитывает 40 редакторов для Windows, 26 - для Macintosh, 28 для всех остальных платформ, в том числе 16 для X-Window. Коммерческая информационная служба Yahoo поддерживает отдельный список HTML-редакторов для Windows. В принципе, эта тенденция понятна. Администраторы серверов, среди которых подавляющее большинство составляют Unix рабочие станции, вообще не используют HTML редакторы, а обходятся обычными текстовыми. Число специализированных рабочих мест типа WebForce еще невелико, да и затраты на полный комплект, включающий рабочую станцию Indy и программное обеспечение, не сравнимы с затратами на персональный компьютер. Таким образом, если и нужно какое-либо специализированное программное обеспечение для разработки Web-страниц широкими слоями общественности Internet, то его место на персональном компьютере с Windows. В связи с этим интересно отметить еще одну тенденцию, которая связана с внедрением операционной системы Windows-95. Многие специалисты на западе наперебой обсуждают внедрение в Netscape Navigator возможностей интерпретатора языка Java, которое по их мнению произведет новую революцию в технологии World Wide Web. Может быть так оно и будет, но разработка страниц, содержащих Java applets - мобильный код языка Java, не такое простое дело, как набор текстовых документов и требует навыков настоящего программирования. В этом свете разработка Microsoft Extensions, в частности BGSOUND, выглядит хоть робкой, но очевидной попыткой дать более простые средства разработки мультимедийных страниц, чем это возможно при использовании Java. Netscape в настоящее время - лидер не только разработки программ просмотра страниц Web, но и законодатель моды в разработке самого языка HTML. Собственно, последнее обстоятельство и определяет лидерство Netscape в разработке программ. Но эта ситуация будет продолжаться только до тех пор, пока язык не сложился. Как только HTML перестанет меняться со скоростью 50% новых тегов в год, у Microsoft появится реальная возможность вытеснить Netscape c платформ, которые используют ее операционные системы. Пока же, то, что поставляется с Windows-95 скорее прототип, чем промышленная программа.
На этом можно было бы и поставить точку в нашем обзоре специализированных HTML-редакторов, но мы рассматриваем эти программы с точки зрения разработчика HTML-страниц, и в этом случае наш обзор будет несколько односторонним. Дело в том, что содержание документа интерпретируется не только программой просмотра страницы. В настоящее время довольно большой объем работы выполняется сервером. И здесь мы сталкиваемся с характерной для архитектуры «клиент-сервер» проблемой, которая коротко характеризуется сочетанием «толстый и тонкий». В настоящее время явно доминирует тенденция сделать «толстым» клиента. Собственно все расширения HTML направлены на внедрение новых возможностей, которые должен реализовывать клиент. Но к чему это приводит, видно по тем же редакторам HTML документов. Например, работа с лучшим из них, HotDog, в режиме WYSIWYG на PC486/100 с 16Mb оперативной памяти выглядит крайне непривлекательно. Обновление документа в контрольном окне явно не успевает за изменениями в окне редактирования и просто тормозит весь процесс подготовки документа. Реально, приходится набирать документ вслепую. Тот же эффект наблюдается и у HotMetal, и у <Live Markup>. Да это и не удивительно, если размер HotMetal, например, превышает 2Mb. Отключение режима WYSIWYG не решает этой проблемы - размер Netscape или Mosaic, которые можно использовать для тестирования страниц, также находятся около магической цифры 2Mb. Таким образом для разработки Web-страниц требуется машина, сравнимая по своим возможностям с той, на которую ставится сервер HTTP. В этом случае совершенно логичным является включение сервера в комплект инструментов разработки страниц Web. Если рассматривать эту проблему с другой точки зрения, то появления тагов типа BANNER или фреймов - это прямая альтернатива вставкам, которые осуществляет сервер в процессе подготовки документов (server site includes). В данном случае я рассматриваю фреймы только в этом смысле, хотя у этой конструкции языка есть множество других полезных применений. Но если сервер делает свою работу, не нагружая сети, то все выше указанные расширения языка только увеличивают трафик. Кроме того, используя обычный редактор, нельзя проверить работу через формы со скриптами CGI и стеками гипертекстовых ссылок - imagemap. Поэтому, некоторые фирмы предлагают в своих комплектах не только средства редактирования документов, но и серверы, например, Hype IT 1000, FrontPage, WebForce. Вообще, с появлением возможности динамического обновления страниц как со стороны сервера, так и со стороны клиента, делает такие связки достаточно эффективными. Это тот же принцип WYSIWYG, но не модельный как в HotDog с использованием специальных компонентов, а реальный, где применяется настоящий сервер и настоящий клиент. При этом в качестве средства набора страниц можно использовать любой HTML-редактор. При изучении документации по HTML, может сложиться впечатление, что HTML развиваются только путем добавления новых контейнеров, которые должны интерпретироваться клиентом. Это не так. В настоящее время, многие серверы стали поддерживать очень похожие возможности предварительной обработки документов перед их отсылкой клиенту. Если год назад, реально, это были только вставки, то теперь этот набор расширен до условных вставок и условной генерации. Некоторые разработчики пошли еще дальше и стали внедрять в HTML таги, которые интерпретируются только сервером. Типичным примером может служить HtmlScript. Отличие этого подхода в том, что если раньше предварительная обработка базировалась только на использовании комментариев HTML, то в HtmlScript язык дополнен новыми контейнерами, которые позволяют манипулировать содержанием документа-макета, который в результате этих манипуляций «на лету» превращается в обычный HTML-документ перед отправкой программе просмотра. Для подготовки такого сорта документов пока вообще нет специальных средств.
И последнее, о чем хочется сказать, - это о стиле подготовки документа. До сих пор для этой цели используется обычный набор текста, который производится в той же манере, что и в обычном текстовом редакторе. Но еще на заре гипертекстовых систем, многие теоретики говорили о том, что для нелинейного текста следует применять и нелинейные процедуры его подготовки. Кажется, что некоторые разработчики HTML-редакторов наконец прониклись этой идеей и решили создать нечто, что отличалось бы от обычного редактора. Первой ласточкой этого направления можно считать программу InContext Spider. Концепция этой программы достаточно прозрачна, но непривычна. В ее основу положен принцип визуализации контейнеров HTML и их связей между друг другом. Контейнеры помечаются соответствующими иконками, и автор может работать с каждым контейнером независимо от других. Для их взаимосвязи контейнеров используются деревья, сети и т.п. Такой стиль работ похож на разработку встроенных в текст картинок в Word 6.0 for Windows.
Во-первых, - это обзор «HTML EDITORS» (Forrest H.Stroud, http://cws.wilmington.net/ html.html), во-вторых, руководство «THE WEB DESIGNER» (N.Laviolette, http:// www.kosone.com/people/nelsonl.nl.html, в-третьих «HTML Editor Reviews» (Carl Davis, http://www.ccs.org/htmledit/). На этих страницах можно найти обширные списки редакторов с их кратким описанием и оценками авторов обзоров. Надеюсь, что эта информация поможет читателям в их повседневной работе.
Таблица 3.3.
HTML-редакторы
|
Название |
Адрес |
Примечание |
|
HotDog |
http://www.sausage.com/ |
Сервер часто не доступен Windows |
|
HTMLed |
http://www.ist.ca/htmled/ |
Windows |
|
HotMetal |
http://www.sq.com/ |
Windows |
|
InContext Spider |
http://www.incontext.ca/ |
Windows |
|
Phoenix |
http://www.bsd.uchicago.edu/ftp/pub/phoenix/ |
Unix |
|
Symposia |
http://www.grif.fr/ |
Unix |
|
TkWWW |
http://www.w3.org/hypertext/WWW/TkWWW/Status.html |
Unix |
3.5.8.3. Графические редакторы и их особенности
Главное особенностью графических редакторов является требование поддержки форматов GIF87, GIF89A и JPEG. Такое требование определяется тем, что только эти форматы поддерживаются программами клиентами World Wide Web, точнее большинством программ просмотра Website. Такие программы как Netscape Navigator и Internet Explorer позволяют просматривать картинки этих форматов внутри документов или как самостоятельные страницы Website.
Коммерческими программами, которые поставляются вместе со сканерами (обычно это FotoShop различных версий, продукты Adobe различных версий и др.) данные форматы поддерживаются. Единственным исключением является многокадровый GIF89A, для которого необходима отдельная программа подготовки документов.
Из свободно распространяемых программ наиболее популярны Lview (Windows), как коммерческая версия так и рекламная бета-версия, и X-Paint (X-Window). Если говорить более точно, то Lview - это интерактивный конвертор графических файлов из одного формата в другие.
|
|
Рис. 3.32. Графический конвертор Lview
Lview способен преобразовывать графические фалы из/в форматы: JPEG, BMP, GIF78A, GOF89A, TARGA, PCX, PPM, TIFF.
Программа X-PAINT для X-Window - это полноценный графический редактор, который способен сохранять документы в форматах GIF и JPEG. Его также довольно часто используют для конвертирования файлов из формата PCX.
В последнее время довольно широко при разработке страниц стали применяться многокадровые графические файлы формата GIF89A. Большинство небольших движущихся картинок в World Wide Web реализованы именно в этом стандарте, а не в виде Java-applet’ов. Принцип разработки таких объектов тот же, что и при производстве мультфильмов. Сначала создают последовательность из нескольких картинок, а потом их объединяют в единый файл. В заголовке файла содержаться правила его просмотра: число кадров, промежутки между кадрами и команды начала и остановки просмотра.
|
|
Рис. 3.33. Пример создания файла формата GIF89A
После того, как такая картинка вставлена в текст HTML-документа, она может быть отображена в виде небольшого мультфильма программой просмотра страниц World Wide Web. Такие программы просмотра как Netscape Navigator и Internet Explorer прекрасно отображают эти картинки. Если программа-клиент не способна отобразить файл формата GIF89A, то тогда просто отображается первый кадр. Так поступают, например, такие программы как Arena и Chimera.
Составление документа из нескольких файлов основано на механизме подстановок (server site includes), которые сервер осуществляет перед отправкой указанных в запросе клиента данных. Требование на подстановку включается в тело документа в виде строки комментария.
3.5.8.4. Серверы протокола HTTP
Сервер протокола http - это сердце Website. От того, насколько эффективно работает программа-сервер, зависят характеристики всего аппаратно-программного комплекса, реализующего Website.
Если проанализировать существующие программы этого типа, то можно легко убедиться в том, что основой большинства коммерческих и свободно распространяемых серверов является сервер NCSA 1.3R. На основе этого сервера разработаны такие популярные программы, как Netscape Enterprise Server, Internet Information Server (Microsoft), Apache и ряд других. Такая популярность NCSA httpd объясняется его функциональной полнотой и прозрачностью кода. Все изменения в этой программе были направлены на повышение эффективности кода, исправлению ошибок и повышению безопасности обмена данными.
Другой традиционный соперник NCSA - это сервер CERN. От этого сервера современные программы унаследовали возможность расширения за счет редактирования с ядром, т.е. модульную архитектуру, и возможность работы в режиме посредника и кэширующего сервера.
Рас уж речь зашла о свойствах серверов, то в настоящее время следует выделить три основных типа серверов:
· простые, классические, серверы,
· серверы посредники,
· кэширующие серверы.
Простой сервер обеспечивает доступ к документам Website и обмен данными с прикладными программами по запросу программы клиента.
Сервер-посредник(proxy) не является, в прямом смысле этого слова, сервером. Его задача состоит в обслуживании запросов не к своей собственной базе данных, а к World Wide Web в целом. Это значит, что для внешнего мира вся организация, т.е. все пользователи организации, представлена в виде всего одного адреса, с которого сервер отправляет запросы на другие серверы сети. Такой метод позволяет скрыться за межсетевым фильтром.
Кэширующий сервер - это другая разновидность сервера, точнее другое свойство сервера World Wide Web. Главная задача кэширующего сервера - это сокращение трафика в сети. Кэширующий сервер захватывает документы, которые пользователи запрашивают из сети. Обычно этот прием применяется на серверах посредниках. Таким образом создается временная локальная база данных страниц. Как показывает практика пользователи в своей массе, до 80% от их общего числа, используют одну и туже информацию, что составляет только около 20%, опрашиваемых информационных ресурсов. Если документы захватываются и хранятся на кэширующем сервере, то это позволяет разгрузить обмен по сети.
Все виды серверов можно использовать и для анализа статистики посещения серверов. Рассмотрим теперь конкретные пример серверов.
3.5.8.5. Выбор, установка и настройка сервера
Если Website организуется на базе специально разработанной для этой цели платформы, то выбирать, что называется, не приходится. Чаще всего это будет либо Netscape Enterprise Server или Netscape Fastrack. Если речь идет об Windows NT, то в этом случае кроме продуктов Netscape имеет смысл рассмотреть и IIS от Microsoft. В принципе это почти одно и то же.
Если же система устанавливается на произвольной платформе, то здесь выбор также не очень большой: сервер WN или Apache. WN - это самостоятельный продукт, который не использует код NCSA. До середины 1996 года это был пожалуй наилучший сервер. Однако, в настоящее время предпочтение следует все-таки отдать серверу Apache, который является развитием NCSA 1.3R в сторону построения модульной структуры и повышения безопасности обмена данными.
Тем не менее при рассмотрении установок и настроек мы будем параллельно описывать как тот, так и другой серверы.
Найти ftp-архив с дистрибутивом сервера не сложно. Для этого следует обратиться в каталог Yahoo (http://www.yahoo.com/) и там в разделе программного обеспечения серверов World Wide Web, можно найти адреса первоисточников. Если по каким-то причинам передача данных с сервера первоисточника происходит недостаточно быстро, то можно воспользоваться «зеркалами», которые расположены в пределах родного отечества. Ссылка на эти зеркала находится на домашней странице каждого сервера. Apache и WN имеются также и в ftp-архивах ftp.kiae.su и ftp.demos.su(ftp.ru).
После того как дистрибутив получен, его следует разархивировать и внимательно причитать файлы README, INSTALLATION, TODO. Как правило в составе дистрибутива есть скрипт configure(необходимо установить perl), который создает make-файл для компиляции и сборки сервера. Если в системе нет perl, и заниматься его установкой нет желания, то в этом случае надо отредактировать make-файл-источник для скрипта в соответствии с особенностями своей операционной системы. В данном случае имеется в виду Unix, т.к. для NT лучше воспользоваться уже собранным кодом.
В ряде случаев компилировать и собирать ничего не надо. Выполняемые модули для наиболее популярных платформ, как правило, уже есть в ftp-архиве. В этом случае надо только скопировать эти модули и документацию.
После того, как сервер собран или переписан, его устанавливают в то место файловой системы, где администратор предполагает его использовать. Наиболее популярное место - это директория /usr/local/etc/httpd. Но администратор может разместить сервер и в другом месте.
При размещении сервера в другом месте, следует отредактировать Makefile, если вы сами собирали сервер. В Makefile’е обычно есть переменная, которая определяет место расположения сервера и его служебных файлов. Кроме того, что эта переменная влияет на результат выполнения команды make install , по которой программное обеспечение сервера копируется в корневую директорию сервера, она же используется и для установки директории по умолчанию. В исполняемых модулях, которые получают по сети, именно /usr/local/etc/httpd указана в качестве такой директории по умолчанию.
Домашнюю директорию можно изменить не только при перекомпиляции, но и при запуске сервера. У сервера WN эта директория указывается в качестве последнего аргумента в командной строке:
/usr/paul>swn -p port [other options] /path/to/wn_root
При запуске apachie также можно указать корневую директорию:
/usr/paul>httpd -d /users/etc/httpd
Кроме сервера в корневой директории сервера могут располагаться еще служебные фалы и директории. Если для WN это условие не является обязательным, то при работе с Apache, для согласования его структур данных с сервером NCSA, надо создать еще несколько поддиректорий:
drwxr-xr-x 2 root wheel 512 Oct 11 07:01 cgi-bin
drwxr-xr-x 2 root wheel 512 Oct 11 07:02 conf
drwxr-xr-x 14 root wheel 1024 Oct 12 06:13 htdocs
-rwxr-xr-x 1 paul wheel 21739520 Oct 11 07:37 htdocs.tar
-rwxr-xr-x 1 root wheel 162003 Oct 11 07:16 httpd
drwxr-xr-x 2 root wheel 2048 Oct 11 07:01 icons
drwxr-xr-x 2 root wheel 512 Oct 11 07:19 logs
drwxr-xr-x 2 root wheel 2560 Oct 11 07:01 src
drwxr-xr-x 2 root wheel 512 Oct 11 07:01 support
Как видно из приведенного списка, это:
· cgi-bin - для размещения скриптов SGI;
· conf - для размещения конфигурации сервера;
· htdocs - корень дерева website;
· icons - место размещения иконок;
· logs - место размещения журналов контроля доступа.
Другие файлы и директории не являются обязательными и могут быть опущены. При анализе листинга, указанного выше, обратите внимание на флаги прав доступа к файлам и директориям. Обязательным условием функционирования обоих серверов является наличие флагов “чтения” и “выполнения” для всех файлов и директорий, к которым сервер будет обращаться(«r-x»). Если файл выполнения не будет установлен, то это заблокирует ряд функций сервера, например, команды cd в рамках текущей директории, что приведет к отказам на обслуживание.
Запуск сервера из командной строки - это только один из двух способов его запуска. И сервер WN и сервер Apache можно запускать из сервиса inetd. Для этого в файл /etc/services следует внести следующую запись:
wn 80/tcp
А в файл настроек inetd (inetd.conf) следует внести строчку:
wn stream tcp nowait nobody /full/path/to/wn wn
Аналогичные изменения можно произвести и для Apache.
Если при установке сервера, не предполагается, что к нему будут обращаться по миллиону раз за сутки, то сервер можно запускать через inetd. Однако, этот способ не является распространенным. Чаще всего сервер запускают в режиме stand alone, т.е. просто в качестве демона, который обслуживает запросы от клиентов.
Если у сервера WN все параметры задаются, как правило, в командной строке, то Apache настраивается при помощи файлов настройки. Всего этих файлов три: httpd.conf, srm.conf, access.conf. Существует еще один файл - mime.conf, который определяет обработку файлов других форматов, отличных от текстовых файлов с HTML-документами.
Разберем содержание файла httpd.conf. Начинается файл с определения типа запуска сервера:
ServerType standalone
Опция ServerType в данном случае установлена в значение standalone, т.е. сервер запускается как демон.
Вслед за этим определяется номер TCP-порта, на котором сервер осуществляет обслуживание. Стандартным портом является 80 порт TCP. Однако, обслуживание можно заказать и на другом порте:
Port 80
За этим определяется режим запроса имени хоста или IP-адреса, с которого осуществляется запрос к website:
HostnameLookups on
Вслед за этой опцией определяется идентификатор пользователя и идентификатор группы, под которыми сервер осуществляет обслуживание запроса:
User nobody
Group #-1
Здесь следует сделать небольшое пояснение. Дело в том, что для обслуживания каждого запроса сервер порождает процесс или поток (в зависимости от версии, производителя и операционной системы). При этом сам сервер стартует в момент запуска ОС и, следовательно, в этот момент имеет права администратора системы. Для того, чтобы эти права не получил обычный пользователь, в момент обслуживания запросов клиентов на каждый запрос порождается новый сервер, и уже этот сервер имеет права, которые определяются параметром User. Типичным пользователем, права которого доступны пользователю при доступе к Website, является пользователь nobody.
В файле конфигурации указывается и почтовый адрес администратора:
ServerAdmin paul@kiae.su
Этот адрес используется в сообщениях об ошибках, если ошибки происходят по вине администратора сервера или в сообщениях о перенаправлении запросов.
За почтовым адресом обычно следует определение корня Website. На этот корень будут опираться относительные адреса программного обеспечения. Данный адрес не надо путать с адресом корня страниц Website, который указывается далее:
ServerRoot /users/etc/httpd
DocumentRoot /users/etc/httpd/htdocs
Далее определяется местоположение файлов сообщений об ошибках:
ErrorLog logs/error_log
TransferLog logs/access_log
PidFile logs/httpd.pid
ScoreBoardFile logs/apache_status
AccessConfig conf/access.conf
ResourceConfig conf/srm.conf
Здесь же определяется параметр, по которому прекращается ожидание запроса от клиента:
Timeout 400
При стандартных настройках сервера ничего больше менять в файлах настройки не надо. Из всех параметров, которые еще могут быть указаны, серверу важны только те, что определяют число запросов, которые может обслужить сервер-потомок, т.е. тот, который порождается на запрос пользователя, длительность сессии и виртуальные серверы, там же указываются параметры кэша и режим proxy(посредника). Ниже представлен фрагмент описания параметров кэш-сервера и сервера-посредника:
# Proxy Server directives. Uncomment the following line to
# enable the proxy server:
ProxyRequests On
# To enable the cache as well, edit and uncomment the following lines:
CacheRoot /users/etc/httpd/proxy
СacheSize 5
CacheGcInterval 4
CacheMaxExpire 24
CacheLastModifiedFactor 0.1
CacheDefaultExpire 1
#NoCache olga.polyn.kiae.su
Далее в файле настроек можно определить дополнительные порты и IP-адреса сервера:
# Listen: Allows you to bind Apache to specific IP addresses and/or
# ports, in addition to the default. See also the VirtualHost command
Listen 3000
Listen 12.34.56.78:80
Кроме этого при организации сервера можно использовать так называемые hardware и software виртуальные-серверы:
# VirtualHost: Allows the daemon to respond to requests for more than one
# server address, if your server machine is configured to accept IP packets
# for multiple addresses. This can be accomplished with the ifconfig
# alias flag, or through kernel patches like VIF.
# Any httpd.conf or srm.conf directive may go into a VirtualHost command.
# See alto the BindAddress entry.
<VirtualHost host.foo.com>
ServerAdmin webmaster@host.foo.com
DocumentRoot /www/docs/host.foo.com
ServerName host.foo.com
ErrorLog logs/host.foo.com-error_log
TransferLog logs/host.foo.com-access_log
</VirtualHost>
При определении виртуальных серверов можно указывать любые команды, которые могут быть указаны и для описания главной базы данных. Вообще говоря, описания главной базы данных может и не быть, а могут быть определены только виртуальные серверы.
Следующий файл, который имеет прямое отношение к описанию базы данных - access.conf:
Ix: {13} cat access.conf
# access.conf: Global access configuration
# This file defines server settings which affect which types of services
# are allowed, and in what circumstances.
# Each directory to which Apache has access, can be configured with respect
# to which services and features are allowed and/or disabled in that
# directory (and its subdirectories). Originally by Rob McCool
# This should be changed to whatever you set DocumentRoot to.
<Directory />
# This may also be "None", "All", or any combination of "Indexes",
# "Includes", "FollowSymLinks", "ExecCGI", or "MultiViews".
# Note that "MultiViews" must be named *explicitly* --- "Options All"
# doesn't give it to you (or at least, not yet).
#Options Indexes FollowSymLinks ExecCGI Includes MultiViews
Options All
# This controls which options the .htaccess files in directories can
# override. Can also be "All", or any combination of "Options", "FileInfo",
# "AuthConfig", and "Limit"
#
AllowOverride None
# Controls who can get stuff from this server.
order allow,deny
allow from all
</Directory>
# /usr/local/etc/httpd/cgi-bin should be changed to whatever your ScriptAliased
# CGI directory exists, if you have that configured.
<Directory /users/etc/httpd/cgi-bin>
AllowOverride None
Options None
</Directory>
# Allow server status reports, with the URL of http://servername/status
# Change the ".nowhere.com" to match your domain to enable.
#<Location /status>
#SetHandler server-status
#order deny, allow
#deny from all
#allow from .nowhere.com
#</Location>
# You may place any other directories or locations you wish to have
# access information for after this one.
Данный файл определяет только основные принципы доступа к странице Website и способы работы со скриптами. Для каждой директории могут быть определены свои собственные права доступа и способы генерации страниц. Делается это либо добавлением новых предложений <Directory> и <Location> в данный файл, либо за счет создания в каждой директории файла описания прав доступа. В Apache - это файлы .access, а в WN - это файлы index. При этом принципы описания генерации страниц и доступа к ним в этих двух серверах совершенно разные. К генерации страниц мы вернемся немного позже, пока поговорим еще об одном файле описания настроек Apache - srm.conf. Мы обратим внимание на особенности представления страниц Website:
DocumentRoot /users/etc/httpd/htdocs
UserDir public_html
DirectoryIndex index.html
FancyIndexing on
AddIconByEncoding (CMP,/icons/compressed.gif) x-compress x-gzip
AddIconByType (TXT,/icons/text.gif) text/*
AddIconByType (IMG,/icons/image2.gif) image/*
#... здесь определены другие иконы для разных типов файлов
DefaultIcon /icons/unknown.gif
ReadmeName README
HeaderName HEADER
# IndexIgnore is a set of filenames which directory indexing should ignore
# Format: IndexIgnore name1 name2...
IndexIgnore */.??* *~ *# */HEADER* */README* */RCS
# AccessFileName: The name of the file to look for in each directory
# for access control information.
AccessFileName .htaccess
# DefaultType is the default MIME type for documents which the server
# cannot find the type of from filename extensions.
DefaultType text/plain
# AddEncoding allows you to have certain browsers (Mosaic/X 2.1+) uncompress
# information on the fly. Note: Not all browsers support this.
AddEncoding x-compress Z
AddEncoding x-gzip gz
Alias /icons/ /users/etc/httpd/icons/
ScriptAlias /cgi-bin/ /users/etc/httpd/cgi-bin/
# To use CGI scripts:
AddHandler cgi-script .cgi
# To use server-parsed HTML files
AddType text/html .shtml
AddHandler server-parsed .shtml
# If you wish to use server-parsed imagemap files, use
AddHandler imap-file map
# To enable type maps, you might want to use
AddHandler type-map var
#AddHandler foot-action foot
#Action foot-action /cgi-bin/footer
# Or to do this for all HTML files, for example, use:
#Action text/html /cgi-bin/footer
# MetaDir: specifies the name of the directory in which Apache can find
# meta information files. These files contain additional HTTP headers
# to include when sending the document
#MetaDir .web
# MetaSuffix: specifies the file name suffix for the file containing the
# meta information.
#MetaSuffix .meta
В данном фрагменте многие опции остались в виде комментариев. Если их необходимо использовать, то просто надо убрать символ «#» из первой позиции строки.
Как видно из этих опций, в современных версиях серверов пользователю дается возможность выбора между внешними по отношению к серверу реализациям imagemap и модулем сервера, который реализует те же функции. Кроме того, сервер позволяет реализовать стандартные заголовок и окончание документа (header и footer).
В случае, когда для разных частей базы данных нужны заголовки страниц разного типа, пользуются так называемые server-side includes, т.е. вставки в тело документа, которые сервер делает, перед тем как отправить документ программе-клиенту. Делается это при помощи HTML-комментариев типа:
<!-- #include file.html -->
При анализе документа, содержащего эту строку, вместо нее будет вставлено содержание файла file.html. Синтаксис таких предложений варьируется от сервера к серверу. Некоторые серверы, например WN, разрешают выполнять условные подстановки типа:
<!-- #if accept ~ "image/jpeg" -->
<a href="picture.jpg">
Here is the jpeg version of picture.</a>
<!-- #else -->
<a href="picture.gif">
Here is the gif version of picture.</a>
<!-- endif -->
В данном случае условная подстановка выполняется на основе анализа заголовка запроса программы-клиента, в котором есть список предложений Accept.
Пример заголовка запроса по протоколу HTTP 1.0.
GET /httpddoc/setup/startit.htm HTTP/1.0
Referer: http://144.206.192.101/httpddoc/Overview.htm
User-agent: Mozilla/1.1N (Windows; 16bit)
Accept: */*
Accept: image/gif
Accept: image/x-xbitmap
Accept: image/jpeg
Последние четыре строки этого примера сообщают серверу форматы графических данных, которые могут быть отображены программой-интерфейсом Mozilla версии 1.1N (Mozilla - 16 разрядный интерфейс Netscape Communication для Windows 3.1).
Существуют и другие способы вставки файла в текст документа. Наиболее интересным из них является создание «скелета» документа, состоящего только из вставок. Необходимость в этом появляется например при создании печатной копии гипертекстовой базы данных.
Возможность ссылаться только на часть файла основана на механизме «зон» (ranges). Для того чтобы этот механизм работал, сервер должен понимать запросы типа: <http://host/dir/file;lines=20-30>. В этом случае в качестве ответа будут получены строки с 20-й по 30-ю, а не весь файл. Обычно, такую ссылку используют для работы с плоским текстом.
Еще одна важная особенность современных серверов - это фильтры, позволяющие выполнять некоторые подготовительные операции над файлом прежде, чем им займется сам сервер. Наиболее часто фильтры применяются для распаковки или преобразования графических файлов.
«Зоны» и фильтры не указываются и не прописываются разработчиком в телах документов базы данных сервера, а обычно настраиваются через файлы конфигурации сервера. Сервер NCSA, например, имеет специально выделенную директорию для своих файлов конфигурации. Аналогичную структуру имеет и популярный сервер для Windows 3.1 и
Windows NT - Winhttpd. Другие серверы, например WN, в каждом каталоге дерева базы данных имеют соответствующий файл конфигурации ресурсов.
Описание файлов со специальным назначением следует начинать с файла index.html, который предназначен для тех случаев, когда пользователь не указывает в своем запросе конкретный файл базы данных, а просто обращается к серверу или к одной из директорий:
http://polyn.net.kiae.su/
или
http://www.w3.org/hypertext/
В этом случае по умолчанию обращение происходит к файлу index.html. Вообще говоря, таким файлом может быть любой другой файл, который будет назначен при конфигурировании вместо index.html, но это приведет к необходимости постоянно помнить о том, что на вашем сервере все не так как у всех остальных.
Важным свойством сервера является перенаправление запроса, когда в файле конфигурации появляется указание на другой файл. Все, кто пробовал работать с Line Mode Browser’ом, наверняка сталкивались со следующей ситуацией: на экран выдается странное сообщение «Сервер выполнил перенаправление запроса. Программа-клиент не умеет делать автоматический перевызов ресурса...». После подобной фразы предлагается выбрать одну из ссылок для перехода к требуемой WWW странице. До сих пор с этим приходится сталкиваться при обращении по адресу http://www.w3.org/ или http://info.cern.ch/. В данной ситуации происходит перенаправление запроса на другой ресурс, а так как программа просмотра Line Mode Browser или www не выполняет повторного запроса ресурса с новым адресом, то приходится делать его вручную. Вообще говоря, перенаправление чрезвычайно полезный механизм, при отсутствии которого во время перемещения страниц с одного сервера на другой в сети творилась бы жуткая неразбериха.
Кроме простого перенаправления существует еще одна интересная возможность переадресации запросов, связанная со временем хранения файла в базе данных. В заголовке HTTP существует предложение Refresh, которое заставляет клиента периодически, через определенный промежуток времени, без дополнительного требования со стороны пользователя, обращаться к серверу за новой копией файла. При этом сервер, например WN, имеет возможность перенаправить запрос к другому файлу базы данных. Используя этот механизм, можно организовать цикл из нескольких страниц, которые будут замещать друг друга. Применение такого механизма очевидно: рекламные ролики, галереи картинок, информационные доски. В сочетании с CGI-скриптами такой механизм дает возможность простыми средствами организовать довольно сложные динамические страницы.
Последним, о чем следует упомянуть в связи со структурой базы данных сервера WWW, являются файлы-индексы. Эти файлы не следует путать с index.html, используемым для доступа по укороченному URL. Главное назначение файлов-индексов - обеспечение поиска информации в базе данных WWW сервера по ключевым словам. Такие серверы как CERN httpd или WN имеют специальный модуль, который реализует функции поисковой машины. Сервер NCSA обычно настраивается на использование внешней поисковой машины, например WAIS, а индексный файл - это инвертированный список, где каждому слову ставится в соответствие список документов, где это слово встречается. Часто считают, что поиск по ключевым словам реализует полнотекстовый поиск по базе данных: однако это не так. Реально в файлы-индексы попадают только те слова, которые содержатся в части документа, предназначенной для построения индекса. Так многие серверы позволяют строить индексы по заголовкам документов, по специальным полям пользователя или по спискам ключевых слов, указанных в файле конфигурации. В принципе, существует возможность построения индекса с использованием полного текста документа, но при этом следует учитывать следующее: в полном тексте много общих слов, которые будут занимать место, но не прибавят точности поиску. При создании таких индексов база данных будет фактически продублирована, но только в другом формате.
Все серверы поддерживают возможность запуска внешних программ через спецификацию Common Gateway Interface. Обычно CGI скрипты расположены в специальной директории базы данных сервера. Однако, в ряде случаев, скрипт может храниться и в произвольном месте файловой системы. Сервер распознает скрипт либо по месту хранения, либо по расширению имени скрипта - как правило, это «cgi». Как это определяется, мы видели из файлов настройки сервера Apfche.
3.5.8.6. Обслуживание запросов
Обсудив структуру базы данных сервера, перейдем к обсуждению процедуры обслуживания запросов программ-клиентов World Wide Web. Существует два способа активации сервера: запуск в качестве «демона» или запуск через механизм inetd. В первом случае сервер осуществляет прослушивание 80-го порта TCP и запуск обслуживающей запросы части самостоятельно. При этом сервер может охватить одновременно несколько запросов. Во втором случае сервер инициируется программой обслуживания запросов по мере их поступления. Первый случай предпочтительней при большом количестве обращений со стороны программ-клиентов, второй более экономичный и требует меньшего количества системных ресурсов. После получения запроса сервер принимает запрос и приступает к разбору его заголовка, из которого сервер извлекает информацию о возможностях клиента, например, о его способности работы с графикой, определяет адреса клиента и, если необходимо, протоколы предварительной обработки информации. Эти данные используются сервером для анализа прав данного клиента по доступу и его возможностей по проведению подстановок и кодированию текста документа. После этого сервер выделяет из заголовка запрос на ресурс, определяет метод доступа к ресурсу и тип ресурса. Именно в этом месте принимается решение на запуск скрипта или перенаправление запроса. После выделения запроса на ресурс, сервер активирует программы предварительного преобразования данных (разархивирование, подстановки). После этого сервер начинает формирование ответа на запрос. В заголовке он указывает необходимые инструкции для клиента. Если происходит перенаправление запроса - Locate, если необходимо периодическое обновление - Refresh и т.п. Следует отметить, что результат работы скрипта также проходит обработку на сервере, который не подставляет дополнительной информации в заголовок ответа только в том случае, если скрипт полностью сформировал HTTP.
Вообще говоря, серверы являются относительно небольшими программами по сравнению с клиентами HTTP, например, головной модуль сервера WN составляет всего 13911 байт кода на языке Си. Кроме самого сервера в комплект программного обеспечения, необходимого для организации базы данных World Wide Web, входят средства построения индексов и стандартный набор CGI скриптов, главным из которых является imagemap. Следует отметить, что не все серверы обслуживают графические стеки гипертекстовых ссылок через imagemap. Сервер WN, например, имеет встроенный модуль обработки таких ссылок. Данный разнобой осложняет перенос базы данных с одного сервера на другой и здесь затрачиваются основные усилия на модернизацию системы.
В заключение, хотелось бы отметить, что организация своей собственной базы данных WWW не является запредельно сложной задачей - в ftp архивах (ftp.kiae.su, ftp.funet.fi, ftp.sunet.se и др.) можно без труда найти все необходимое программное обеспечение. При этом следует принимать во внимание тот факт, что при запуске серверов часто требуется выполнять привилегированные операции, а это разрешено только администратору системы. Из всех серверов, которые мне пришлось устанавливать из исходных текстов, без дополнительных усилий собрался только WN: NCSA требовал некоторых изменений в Makefile, а CERN требовал установки дополнительной библиотеки общих кодов.
3.5.9. Организация информационной службы на основе технологии World Wide Web
В последнее время, активно прорабатываются различные варианты реализации информационной службы на основе серверов HTTP. Основу этой идеи составляет тот факт, что базовое программное обеспечение уже существует. Существует также и формат предоставления документов и спецификации взаимодействия с внешним, по отношению к серверу, программным обеспечением.
Перед такого рода системами ставится несколько задач:
· представление информации об организации;
· сбор информации об информационных запросах пользователей;
· сбор информации об информационных нуждах сотрудников организации.
Первая задача решается путем создания стандартной базы данных Web и установкой сервера, который будет работать в стандартном режиме.
Вторая задача решается за счет анализа журналов посещения сервера пользователями Internet и путем организации интерфейсных страниц для сбора информации об этих пользователях.
Третья задача решается за счет анализа кэша сервера. Все запросы сотрудников захватываются в этот кэш и доступны для администрации сервера. Все это позволяет говорить о создании аналитической службы, главной задачей которой является анализ информационных потребностей различных ей информации в World Wide Web. Приведем некоторые примеры анализа этой статистики.
3.5.9.1. Статистика доступа к системе и ее анализ
Все сервера обеспечивают контроль доступа к своим информационным ресурсам. Осуществляется он на базе специального журнала доступа. Для пояснения целей задач сбора и обработки статистики буде рассматривать конкретный пример - базу данных «Polyn» РНЦ «Курчатовский Институт».
При обращении к информационным ресурсам систем, разработанных в рамках технологии World Wide Web, главным в процессе обработки запросов пользователя является сервер протокола HTTP. Общая схема получения статистики обращения пользователя к системе может быть изображена следующим образом:
|
|
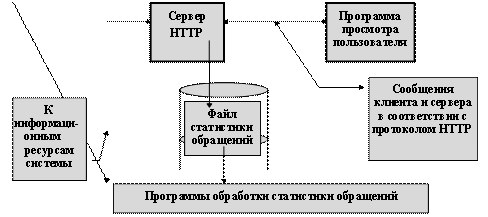
Рис. 3.34. Схема получения статистики обращений к информационным ресурсам базы данных под управлением
сервера HTTP
Как отображено на этой схеме (рисунок 3.34) любой сервер ведет файл статистики (в нашем случае файл статистики сервера NCSA 1.2).
Этот файл является главным инструментом при анализе эффективности работы базы данных Web. Каждый сервер ведет статистику посещений базы данных пользователями Internet в этом файле. Прежде чем начать описание содержания такого файла следует условиться об определенной терминологии. Визитом или посещением базы данных Web принято называть обращение к странице базы данных. Посещение следует отличать от сессии и обращения к файлу базы данных (Hit).
Сессия - это множество обращений одного и того же пользователя к страницам базы данных за ограниченный промежуток времени. При этом время между посещениями страниц равно времени их прочтения. При работе с ресурсами Web нельзя точно определить сессию, т.к. если ее начало еще можно проидентифицировать, то определить конец сессии довольно трудно. Программное обеспечение пользователя не сообщает об окончании работы данной сессии. Следует заметить, что разные разработчики программ-клиентов WWW и серверов стремятся найти решение этой проблемы. В частности Netscape Communication предлагает в качестве решения ввести дополнительный атрибут в протокол обмена информации, который будет определять идентификатор сессии. Идентификатор должен сообщаться клиенту сервером и храниться у клиента втечение сеанса работы с данным сервером.
Обращение к файлу базы данных отличается от посещения страницы тем, что одна страница может состоять из нескольких файлов. В качестве простого примера можно указать на страницы с тагами <IMG>. В этом случае программа клиент порождает запрос не только к файлу с расширением html, но и к файлам, указанным в странице в качестве встроенных картинок с расширениями gif, например.
В настоящее время существует несколько типов журналов посещений. Формат журнала зависит от типа сервера, который используется для ведения базы данных. Однако, в настоящее время формат записей журнала посещений стабилизировался, и большинство серверов поддерживает следующий перечень полей:
1. Доменное имя удаленного хоста или его IP-адрес.
2. Имя пользователя (часто не указывается и заменяется на символ «-»)
3. Идентификация пользователя (Заменяется на «-» если не используется запрос идентификации)
4. Дата и время посещения
5. Запрос клиента
6. Код возврата
7. Количество переданных байтов
Некоторые серверы в дополнение к этим полям записывают в журнал еще и
8. URL страницы, с которой осуществлен доступ(если клиент не сообщает этой информации, то поле заменяется символом «-»)
9. Тип программного обеспечения клиента
Ниже приведен пример типичного журнала посещений, который ведется сервером NCSA, использующимся в системе «Полынь».
Пример. Фрагмент статистики сервера при обращении к базе данных «Полынь»
144.206.192.4 - - [15/Sep/1995:23:17:29 -0400] "GET /dss/index.htm HTTP/1.0" 200 1020
144.206.192.4 - - [15/Sep/1995:23:17:30 -0400] "GET /dss/radsign1.gif HTTP/1.0" 200 270
144.206.192.4 - - [15/Sep/1995:23:17:56 -0400] "GET /dss/index.htm?kuku HTTP/1.0" 200 1020
Разберем первую строчку журнала посещений, представленного в примере:
144.206.192.4 - адрес хоста, с которого осуществлялся доступ к базе данных;
«- -» - сообщает, что северу не были переданы ни имя пользователя, ни запрос на идентификацию;
[15/Sep/1995:23:17:29 -0400] - дата и время доступа;
GET /dss/index.htm HTTP 1.0 - запрос клиента;
200 - код успешного завершения обработки запроса;
1020 - число переданных клиенту байтов.
Первые две строчки этого примера составляют одно посещение, т.к. страница «index.htm» содержит картинку «radsign1.gif». Таким образом, журнал посещений содержит информацию о доступе к файлам базы данных, из которой еще надо составить статистику доступа к страницам.
Кроме файла посещений, который обычно называется access_log, многие серверы ведут еще и другие системные журналы, например, error_log (журнал ошибок), referer_log (журнал страниц, в которых установлены ссылки на данную страницу), agent_log (журнал программного обеспечения клиентов).
В нашем случае сосредоточим внимание на журнале посещений, т.к. именно он является источником статистики, которую будем анализировать в дальнейшем.
Существует достаточно большой набор программного обеспечения, которое можно использовать для получения простейших статистических оценок. Здесь мы рассмотрим программы: Analog, AccessWatch, Web-Scope, Statbot, mw3s, Raytraced Access Stats.
Analog - программа, разработанная Стефеном Тернером (Stephen Turner) из лаборатории статистики Кембриджского Университета, считается одной из лучших среди свободно распространяемых средств анализа статистики Web. Она выдает статистику в виде ASCII файлов, в которых содержится и графическое представление в виде, принятом для просмотра на алфавитно-цифровых дисплеях. Считается, что если понадобится построить качественные картинки, то лучше использовать специальное программное обеспечение для их подготовки. Analog анализирует файлы посещений в «старом» формате сервера NCSA и «общем» формате, который был описан выше. Программа подготавливает сводный отчет, в который входит общее количество посещений сервера за анализируемый период, общее число ошибок за исследуемый период, число перенаправлений, средние число запросов в день, число обслуженных хостов, количество страниц, с которых осуществлялся доступ, число некорректных записей в файле посещений, общее число байтов переданных клиентам и среднее число байтов переданных за сутки. Analog генерирует месячный отчет по доступу к базе данных, недельный отчет и несколько видов суточных отчетов: сводный отчет по дням недели, и отчет по датам. Подсчитывается частота обращений с различных доменов, с различных хостов, и выводится в упорядоченном по частоте виде. Для анализа популярности страниц приводится статистика посещения директорий и отдельных страниц базы данных. В конце отчета приводится время, за которое отчет был подготовлен, и версия программы. Программа может быть получена по адресу: ftp://ftp.statslab.cam.ac.uk/pub/users/sret1/analog/.
AccessWatch - это скрипт, написанный на Perl 5.0 Дейвом Маером (Dave Maher) из университета Бакнел, который позволяет собирать статистику не только по серверу в целом, но и по отдельным домашним страницам пользователей. Для работы с этой программой желательно иметь программу просмотра страниц Web, которая позволяет отображать таблицы HTML. Последнее необходимо для представления данных в виде столбцов гистограмм. Такой метод представления статистики в программах анализа журналов посещений довольно популярен и не только в свободно-распространяемых программах, но в коммерческих продуктах. AccessWatch генерирует отчет о суточной статистике посещений, почасовую статистику посещений, упорядоченное по частоте посещений распределение страниц, частоту посещения с разных доменов, упорядоченный список 10 наиболее активных хостов. Адрес AccessWatch: http://www.eg.bucknell.edu/~dmaher/accesswatch/.
Mw3s - это одна из версий Multi Server WebChats (v1.4.1), которая разработана Тобиасом Оетакером(Tobias Oetiker) из университета De Montfort, Англия. Главное назначение этого пакета - сбор статистики с нескольких http серверов. Пакет состоит из двух программ. Первая - logscan устанавливается как CGI-скрипт на каждом сервере, который будет находится под присмотром mw3s. Вторая - loggather, который устанавливается в crontab машины, осуществляющей мониторинг. Loggather запускается системой один раз в сутки, порождая при этом запросы к logscan. Mw3s, также как и AccessWatch, использует механизм таблиц HTML для отрисовки столбцов гистограмм. Скрипты можно получить по адресу: ftp://ftp.dmu.ac.uk/pub/netcomm/src/web/.
Statbot - программа генерации статистических отчетов о посещении Web страниц, которая поддерживается Дейвом Табсом (Dave Tubbs, dttubbs@xmission.com). Statbot генерирует графические отчеты в формате GIF, ссылки на которые могут быть включены в другие HTML-страницы. Генерируется 8 различных графиков-гистограмм: трафик за последние семь дней, трафик за последние 24 часа, сравнительный график трафика за последние четыре недели (каждая неделя отображается своим цветом), графики максимального и среднего трафика для каждого дня недели, график 10 наиболее активных машин, график соотношения общего посещения каждой страницы к числу повторных посещений этой же страницы (каждая страница отображается на графике отдельной точкой), круговая диаграмма распределения посещений по доменам и график общего числа байтов переданных с данного сервера в день. Программа может быть получена по адресу: ftp://ftp.xmission.com/pub/users/d/dtubbs/.
Web-Scope - пакет анализа статистики посещений, разработанная для TCL System Corporation. Пакет состоит из двух частей: программы построения дополнительных журналов и программы отображения данных. Среди обычного набора графиков и гистограмм следует отметить те, которые направлены на анализ информации о пути достижения страниц базы данных (где находятся ссылки на страницы, внесены ли эти ссылки в файлы закладок, какие роботы посещают страницы и какую информацию они ищут). Информацию о пакете можно найти по адресу: http://www.tic-systems.com/statinfo.html.
Raytraced Access Stats - программа подготовки данных для отображения программой POV raytracer. Главным достоинством этой программы является наличие прекрасной трехмерной графики, которая используется для построения гистограмм. Правда, воспользоваться этой красотой может только тот, кто соберет POV raytracer для своей платформы. Информацию о программе можно получить по адресу: http://web.sau.edu/ ~mkruse/scripts/access3.html
Цель анализа любой статистики обращений к информационной системе - это повышение эффективности работы этой системы, однако само понятие эффективности может быть истолковано по разному. Для коммерческих систем - эффективность будет исчисляться в терминах приносимой системой прибыли, в то время, как эффективность информационной системы бюджетной организации может исчисляться на основании числа реальных пользователей системы, количества запросов и, косвенно, на основе доли бюджетных средств, которые на систему тратятся. В данном разделе речь пойдет об анализе статистики посещений с целью повышения коммерческой эффективности системы. В первую очередь полученные результаты применимы для анализа статистики посещений рекламных материалов и расчета времени и, соответственно, затрат на размещение рекламы на страницах World Wide Web.
Приведем результаты обращений к данным сервера за семь месяцев его эксплуатации, собранные при помощи стандартных программ обработки статистики посещений:
|
|
Рис. 3.35. Статистика обращений за первые 209 суток функционирования сервера
На приведенном выше рисунке видно, что примерно через 150 суток начинает появляться определенный интерес пользователей сети к информации расположенной на сервере. Приблизительно те же данные можно получить и на других серверах сети. При этом интересно отметить, что включение сервера в так называемые Top списки, на задержку практически никак не влияют (можно сравнить с динамикой обращений к серверу компании Demos). Такой эффект легко объясним. Дело в том, что в список ссылка попадает после внесения ее в список популярного коммерческого сервера. Но в этот список ссылка попадает либо после сканирования сети роботом, либо из сообщения в телеконференции, либо после регистрации ее администратором системы. При этом необходимо некоторое время для индексирования ссылки и задержки ее в кэширующем сервере коммерческой системы для того, что чтобы администрация системы обратила внимание на существование такого ресурса и уже вручную внесла изменения в классификацию ресурсов Internet на домашней странице сервера коммерческой службы. Если анонс был сделан в летнее время, то приходится сделать еще и скидку на сезон. Как раз и получаем задержку равную приблизительно 150 дням. Особенно это характерно для специализированных систем типа «Полынь» когда речь идет о довольно узком, с точки зрения Internet круге пользователей.
Теперь обратим внимание на пик в начале графика. Точно такой же пик отмечается на всех серверах - это обращения администратора системы к файлам базы данных. Долгое время, пока система не выйдет на стабильный режим работы администратор системы является самым частым гостем на ее страницах.
Рассмотрим теперь годовой график статистики:
|
|
Рис. 3.36. Статистика посещений за год
На графике хорошо видно, что пик посещений пришелся на 230-250 суток после начала функционирования сервера. Начиная с 300 суток, сервер посещает устойчиво только около 700 пользователей в сутки. Это число отличается от того, которое было до начала роста популярности (150 суток с начала функционирования за вычетом активности администратора), что хорошо заметно и на графике (рисунок 3.36).
Для того, чтобы убедится в том, что это различие статистически значимо, проверим следующую гипотезу: распределения частоты посещения страниц базы данных в начальный период работы сервера и после пика посещений одинаковые. Для этого выберем два периода наблюдений: июль 1994 года и май 1995 года. В качестве статистического теста будем использовать тест Колмагорова-Смирнова. Такой выбор теста объясняется тем, что ни форма, ни параметры обоих распределений не определены априорно. На рисунке 3.37 приведен график этих распределений.
|
|
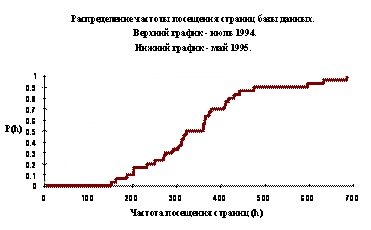
Рис. 3.37. Графики распределений посещений страниц базы данных в начальный и в стационарный период работы сервера
Для приведенного примера значение статистики равно:
|
|
Табличное значение получено для уровня значимости равного 0,05, и т.к. табличное значение меньше экспериментального, гипотеза о равенстве распределений отвергается.
Для того, чтобы лишний раз утвердиться в полученном результате, сравним два распределения стационарного периода работы сервера: май и апрель 1995 года (рисунок 3.38). На этом рисунке видно, что распределения также имеют различия, но существенно меньшие, чем в первом случае. Это подтверждает и статистический тест:
|
|
Табличное значение больше расчетного, и, следовательно, нет оснований для того, чтобы отвергать гипотезу о равенстве распределений.
|
|
Рис. 3.38. Распределения частоты посещения страниц в стационарный период работы сервера
Учет распределения частоты посещений важен с двух точек зрения. Во-первых, с чисто коммерческой. Наибольший процент использования World Wide Web технологии дает реклама товаров и услуг (около 80% всей информации). С этой точки зрения чрезвычайно важно знать, когда реально пользователь получит информацию о товаре и услуге, если ее разместит в Internet. Как показывает статистика обращений, это происходит немгновенно. При этом следует четко представлять, когда реклама становится не эффективно (большинство потенциальных покупателей ее уже посмотрели). Как видно из графика этот период составляет примерно 200 суток. Эта цифра одинакова для всех серверов. Просто на коммерческих серверах ее трудно определить, в то время как специализированные серверы четко дают представление о максимальном наплыве пользователей всех категорий. Дело в том, что большинство пользователей ,которые дали пик - это случайные пользователи, а их процент во всех системах один и тот же. Таким образом выставлять рекламу на срок более чем начальный период плюс 200 суток просто не целесообразно. Для специализированных систем - это срок проведения опросов, манифестов и других материалов информационного характера. Кроме того, становится очевидным, что простое обращений в телеконференции Usenet не дает гарантии максимального оповещения пользователей, т.к. сообщение Usenet хранится только 5 суток, а этого, как видно из графика, совсем недостаточно. Поэтому размещение сообщения в архиве телеконференции или в поисковой системе типа Lycos является оправданным даже с коммерческой точки зрения.
Второй аспект данной проблемы - это отделение шума случайных посещений от запросов действительно заинтересованных в информации пользователей. Совершенно ясно, что изменять структуру базы данных первые 300 суток после ее установки в сети нельзя. В этот период число случайных посещений превосходит число тематических посещений, что приводит к искажению представлений о тематических потребностях реальных пользователей. Чтобы лишний раз подтвердить этот вывод рассмотрим еще один график:
|
|
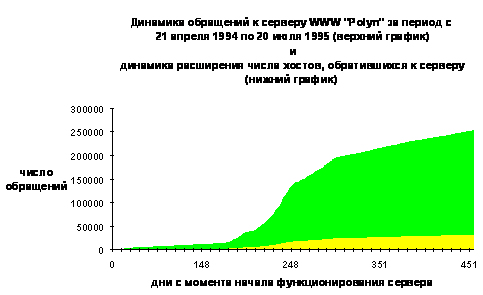
Рис. 3.39. Рост числа машин, с которых обращаются к базе данных «Полынь»
Через 300 суток после начала функционирования сервера рост числа новых машин, с которых обращаются к данным, существенно замедляется при постоянном числе обращений в сутки к страницам базы данных. Это еще раз подтверждает вывод о стабилизации круга пользователей системы. Рассмотрим еще один интересный график:
|
|
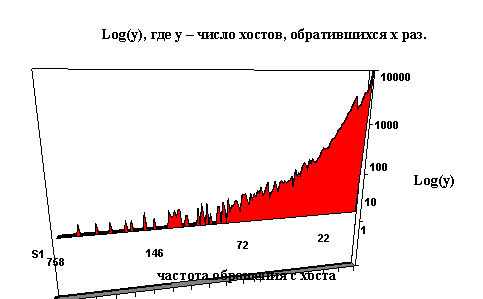
Рис. 3.40. Распределение частоты обращений пользователей к страницам базы данных «Полынь» к середине лета 1995 года
Это график интересен с двух точек зрения. Во-первых, он показывает, что существует несколько сотен пользователей, которые просмотрели все навигационные страницы базы данных (доступ к численным данным фиксируется как единичное обращение и служить для оценки тематической направленности запроса не может). Около сотни пользователей работают с базой данных регулярно. Если учесть, что проблемами моделирования загрязнения окружающей среды в результате аварии на Чернобыльской станции в мире занимается только около десяти групп исследователей, из которых не все имели доступ к системе World Wide Web, то такой показатель можно считать достаточно хорошим. Это подтверждается и результатами научных конференций, где система была включена в список важнейших информационных источников по данной проблеме.
Любопытен еще и тот факт, что большинство случайных пользователей осуществило только одно посещение страниц базы данных. Дело в том, что корневая страница имеет встроенную графическую картинку, которая загружается по отдельному запросу к серверу. Если пользователь работает с графической программой просмотра страниц World Wide Web, то при случайном обращении к базе данных пользователь должен осуществить два посещения (файл HTML и файл GIF). Тогда максимум должен приходится на 2, не на 1. Можно было бы предположить, что максимум в районе единицы говорит о том, что большинство пользователей работает с алфавитно-цифровыми программами просмотра, но этому противоречит статистика программ-клиентов: первое место занимает программа Netscape Navigator, а это графическая программа просмотра. Следовательно, остается только одно - пользователи отключают режим автоматической подкачки графики, и подкачивают иллюстрации только по специальному запросу. Этим они экономят свои ресурсы.
Конечно, в большинство приведенных здесь исследований проводить не надо, результаты сами по себе являются достаточно очевидными, но в данном случае они приведены здесь для полноты картины.
Еще более интересные результаты дает структурный анализ статистики посещений пользователей за разные периоды эксплуатации страниц Web, но это тема отдельного большого разговора, поэтому здесь приведены только результаты без самих статистических данных.
В различные периоды функционирования сервера изменяется тематика обращений пользователей. Структурный анализ позволяет отследить эти изменения и подстроить систему в соответствии с потребностями пользователей. В свою очередь это повышает число посещений страниц сервера и улучшает его коммерческие характеристики.
3.6. Информационно-поисковые системы Internet
Такие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Но, что они из себя представляют, как устроены, почему результат поиска в терабайтах информации выдается так быстро, как устроено ранжирование документов при выдаче, что из себя представляют информационные массивы этих систем - этим вопросам посвящен этот раздел.
Предварительные замечания
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено довольно большое количество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник «Научно-техническая информация. Серия 2. Информационные процессы и системы», которая выходит до сих пор. На русском языке издана так же и «библия» по разработке этого рода систем – «Динамические библиотечно-информационные системы» Жерарда Солтона (Gerard Salton)[1] (список литературы приводится в конце учебного пособия), в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом, нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения, появилось нечто принципиально новое, чего не было раньше. Если быть точным, то информационно-поисковые системы в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти, и в сети не будет каталога, отражающего конкретную предметную область, именно по этой причине для множества серверов Gopher, которое называется GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий мы видим и в World Wide Web. Собственно еще в 1988 году на в специальном выпуске «Communication of the acm»[2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал проблему организации поиска информации в больших гипертекстовых сетях в качестве первоочередной задачи для следующего поколения систем этого типа. До сих пор многие идеи, высказанные в этом разделе, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли[3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена не хорошим программам талантливых одиночек, а средствам, которые являются результатом долгосрочного планирования последовательного движения к поставленной цели научных и производственных коллективов. Рано или поздно этап исследований заканчивается и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако, многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital[4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
3.6.1. Архитектура современных информационно-поисковых систем World Wide Web
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения, рассмотрим типовую схему такой системы (рисунок 3.41). В различных публикациях, посвященных конкретным системам[5,6], приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере представленном в [6]:
|
|
Рис. 3.41. Структура ИПС для Internet (Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
На этой схеме обозначены:
client - это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
user interface - интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска. Просмотр результатов поиска и информационных ресурсов сети - это совершенно разные вещи, на которых остановимся чуть позже.
search engine - поисковая машина служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
index database - индекс - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро, и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
queries - запросы пользователя сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, на которые система дает хорошие ответы.
index robot - робот-индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
www sites - это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно и определим в чем отличие данной системы от традиционной информационно-поисковой системы локального типа.
3.6.2. Информационные ресурсы и их представление в информационно-поисковой системе
Как видно из схемы (рисунок 3.41) документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД’а. ПОД (Поисковый Образ Документа) - это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель[7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия термина в ПОД’е документа или его отсутствия. В более сложных моделях термины взвешиваются, т.е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet[4,6,7]. Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска, и модель поиска в нечетких множествах[7]. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet - это тема специального исследования. Здесь имеет смысл обратить внимание читателя только на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других. Исследования по применению других моделей также ведутся, например, в рамках проекта AltaVista[4] или научными группами[6]. Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени, и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД’ов документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов - это довольно нетривиальная задача, т.к. существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки (title), заглавия (H1, H2 и т.п.), аннотации, списки ключевых слов и полные тексты документов, сообщения администраторов о своих Web-страницах[9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков - поля Subject и Keywords. Наибольший простор для построения ПОД’ов дают HTML-документы. Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно используются списки запрещенных слов (stop-words), которые не могут быть использованы для индексирования, общих слов (предлоги, союзы и т.п.), а также часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием реально, является выбором слов из текста документа и сравнением с целым набором различных словарей, после которого термин попадает в поисковый образ документа, а потом и в индекс системы. Для того, чтобы не раздувать словарей и индексов, а индекс Lycos, например, равен 4TB, применяется такое понятие как «вес» термина[10]. Документ обычно индексируется 40[6] - 100[8] наиболее «тяжелых» терминами.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД’ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД’ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы[6]. Этот проект выбран потому, что он позволяет реализовывать не только примитивный булевый поиск, но и контекстный поиск, взвешенный поиск и ряд других возможностей, которые отсутствуют во многих поисковых системах, например Internet, Yahoo.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-ID отображает идентификаторы станиц в URL этих страниц, Keyword-ID отображает каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков отображает идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок отображает идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице), а прямой список - это массив поисковых образов страниц. Все эти файлы, так или иначе, используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того, чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным - хеширование.
Для обновления индекса применяется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу». Для этого служит таблица модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса, т.е. его перезагрузка.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и гордостью компании. Для того, чтобы убедиться в этом, достаточно почитать материалы OpenText[11].
3.6.3. Информационно-поисковый язык системы
Однако, индекс - это только часть поискового аппарата, причем не видная глазу пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка. Именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: «Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно».
Возможны и варианты. Так в большинстве систем фраза «Unix Platform» будет опознана как ключевая фраза, и не будет разделяться на отдельные слова. Вообще говоря, и все три слова могут быть опознаны как одна ключевая фраза. Другой подход заключается в вычислении близости между запросом и документом. Именно этот подход используется в Lycos, например. В этом случае, в соответствии с векторной моделью представления документов и запросов вычисляется мера близости. К настоящему времени известно около дюжины различных мер близости. Наиболее часто применяется cos угла между поисковым образом документа и запросом пользователя. Именно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее продвинутым языком запросов из современных информационно-поисковых систем Internet обладает AltaVista[4]. Кроме обычного набора AND, OR, NOT, эта система позволяет использовать еще и NEAR. Последний оператор позволяет организовать контекстный поиск. Все документы в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь хочет увидеть ключевое слово (в ссылке, заголовке и т.п.). Можно также задать поле ранжирования выдачи и критерий близости документов запросу.
3.6.4. Типы информационно-поисковых языков
Главная задача информационно-поисковой системы - это поиск информации релевантной информационным потребностям пользователя. Слово релевантность означает соответствие между желаемой и действительно получаемой информацией. Релевантность можно еще представить как меру близости между реально полученными документами и тем, что следовало бы получить из системы. Естественно, что здесь возникает две задачи, которые следует решить: представление информации в системе и формулирование информационных потребностей пользователя. Эти две проблемы тесно связаны друг с другом. Руководства по многим информационно-поисковым системам Internet (Yahoo, OpenText и др.), что система реализует запрос типа «найди похожее». Но что значит эта фраза в реальности? Как вычислить эту самую похожесть?
Наиболее распространенными моделями представления документов в информационно-поисковой системе являются различные вариации на тему векторной модели, когда документ представляется как набор терминов. Как уже упоминалось ранее, это не весь текст документа, а только небольшой набор терминов, который отражает его содержание. Базируясь на таком представлении о документе, и рассмотрим различные информационно-поисковые языки.
3.6.5. Традиционные информационно-поисковые
языки и
их модификации
Наиболее распространенным ИПЯ является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Запрос при этом может выглядеть следующим образом:
((информационная and система) or ИПС) not СУБД
В данном случае эта фраза означает: «Найди все документы, которые содержат одновременно слова «информационная» и «система», либо слово «ИПС», но не содержат слова "СУБД"».
Запрос можно рассматривать как и реальный документ из базы данных. В нашем случае, фактически, мы имеем дело с двумя запросами:
информационная and система not СУБД
и
ИПС not СУБД
Каждый, из которых подразумевает как бы два действия: сначала найти все документы, содержащие необходимые пользователю термины, а потом отсеять те, которые содержат термин «СУБД».
Такая схема достаточно проста, и поэтому наиболее широко применяется в современных информационно-поисковых системах. Но еще 20 лет тому назад были хорошо известны и ее недостатки.
Булевый поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, которые выдаются на запрос. При этом все будет очень сильно зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR напротив может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким ИПЯ создаются специальные документально лексические базы данных со сложными словарями, которые называются тезаурусами и содержат информацию о связи терминов словаря друг с другом.
Модификацией булевого поиска является взвешенный булевый поиск. Идея такого поиска достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. При этом взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, описанном выше, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. При этом измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Языки типа «Like this»
При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, когда близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается sin угла, который получают как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче ссылок на них пользователю. Вообще говоря, скалярное произведение не очень хорошо подходит для информационно-поисковых систем Internet, так как длина запроса обычно невелика. Это в традиционных системах существовали специальные службы, которые отлаживали длинные запросы, а в Internet такие службы только нарождаются. Поэтому реально применяются другие меры близости, но принцип остается тот же: сначала вычисляется мера, а потом происходит ранжирование.
Рассмотренный подход дает возможность более мягкого расширения и уточнения запросов, но он также не гарантирует высоких показателей релевантности, в случае выбора неудачной лексики.
Поиск в нечетких множествах
При этом типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности документам документального массива. Когда запрашивается AND, то это интерпретируется как минимум из двух функций, соответствующих терминам запросов, OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости.
Следует сразу сказать, что этот метод поиска используется только в исследовательских системах и распространен крайне ограничено.
Пороговые модели
Как было видно из предыдущего изложения, на конечном этапе поиска выборка найденных документов ранжируется. Но, совершенно очевидно, что меры близости или поиск в нечетких множествах приводит к ранжированию всего массива документов в базе данных. Современные информационно-поисковые системы Internet имеют базы данных только индексов, занимающие террабайты. Ранжировать целиком такие массивы - это просто безумная затея. Поэтому применяются пороговые модели, которые задают пороговые значения для документов, выдаваемых пользователю.
Кластерная
модель и Вероятностная модель информационного
поиска
В кластерной модели может использоваться два подхода. Первый заключается в том, что массив заранее разбивается на подмножества документов и при поиске высчитывается близость запроса некоторому подмножеству. В другом подходе кластер «накручивается» вокруг запроса и ближайших к нему терминов. Наиболее часто эта модель применяется в системах, уточняющих запрос по релевантности найденных документов.
При вероятностной модели вычисляется вероятность принадлежности документа классу релевантных запросу документов. При этом используется вероятность принадлежности терминов запроса каждому из документов базы данных.
Коррекция запроса по релевантности
Многие системы применяют механизм коррекции запроса по релевантности. Это означает, что процедура поиска носит интерактивный и итеративный характер. После проведения первичного поиска пользователь отмечает из всего списка найденных документов релевантные. На следующие итерации система расширяет/уточняет запрос пользователя терминами из этих документов и снова выполняет поиск. Так продолжается до тех пор пока пользователь не сочтет, что лучшего результата, чем он уже имеет добиться не удастся. Коррекция запроса по релевантности - это достаточно широко внедренный способ уточнения запросов. В некоторых системах пользователь может и не знать, о том, что эта процедура применяется, например, OpenText. В этом случае несколько итераций выполняется без его вмешательства.
Весь этот краткий обзор современного состояния ИПЯ ставил перед собой одну простую задачу: определить степень развития и современный уровень информационно-поисковых средств Internet.
3.6.6. Информационно-поисковые языки Internet
При описании и классификации информационно-поисковых систем ставилась задача проанализировать наиболее популярные и наиболее типичные системы, которыми пользуются в Сети.
Lycos
Как и большинство систем, Lycos дает возможность использовать простой запрос и более изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке. Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о числе документов на каждое слово, а уже позже и список ссылок на формально-релевантные документы. В списке напротив каждого документа указывается его мера близости запросу, число слов из запроса, которые попали в документ и оценочная мера близости, которая может быть больше или меньше формально вычисленной. На апрель 1996 года в Lycos не был реализован булевый поиск, такие планы были анонсированы. Последнее предложение подразумевает только то, что нельзя вводить эти операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Последнее относится к расширенной форме запроса, который предназначен для использования искушенными пользователями системы, которые уже научились пользоваться этим механизмом.
Таким образом, мы видим, что Lycos относится к системе с языком запросов типа «Like this», но предполагается его расширения и на другие способы организации поисковых предписаний.
AltaVista
Наиболее интересным с точки зрения информационно-поискового языка в AltaVista является возможность расширенного поиска. Здесь стоит сразу выделить, что в отличие от многих систем AltaVista поддерживает одноместный оператор NOT. Кроме этого есть еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой словарь этих фраз. Кроме всего прочего, при поиске в АltaVista можно задать имя поля где должно встретиться слово. Это может быть гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но сказано, что ранжирование применяется как при простом поиске, так и при расширенном запросе.
Реально эту систему можно отнести к системе с расширенным булевым поиском.
Yahoo
Данная система появилась в сети одной из первых, и поэтому говорить будем о сегодняшнем состоянии Yahoo, а не о состоянии годовой давности. В настоящее время Yahoo сотрудничает со многими производителями средств информационного поиска и на различных ее серверах используется различное программное обеспечение. На мой взгляд, это самая незатейливая информационная служба, которая сосредоточилась на информации о Web как таковой. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел, и они соединяются либо AND, либо OR. При выдаче не выдается степени соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на «общие» слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что информация в базе данных Yahoo точно есть. Ранжирование производится по числу терминов запроса в документе.
Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText
Информационная система OpenText представляет из себя самый коммерциализированный информационный продукт в сети. Все описания больше напоминают рекламу, чем реальное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов поиска сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска.
OpenText можно было бы отнести без сомнения к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
InfoSeek
Система InfoSeek обладает довольно развитым информационно-поисковым языком, который позволяет не просто указывать какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков «+» - термин обязан быть в документе, «-» - термин обязан отсутствовать в документе. Кроме этого InfoSeek позволяет проводить то, что называется контекстным поиском. Это значит, что, используя специальную форму запроса можно потребовать последовательной совместной встречаемости слов. Кроме этого можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Есть возможность и указания ключевых фраз. Ключевая фраза от последовательной встречаемости отличается тем, что фраза всегда ищется как единое целое, а при последовательной встречаемости слова могут стоять рядом, но в произвольном порядке. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса в документе, за вычетом общих слов. Все эти факторы используются как вложенные процедуры.
Подводя краткое резюме, можно сказать, что InfoSeek относится к традиционным системам с элементом взвешивания терминов при поиске.
WAIS
WAIS является одной из наиболее изощренных поисковых систем Internet. В отличие от многих поисковых машин, ИПЯ системы позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечение терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии «Британика» на Internet.
Применение языков на практике:
Рассмотрим теперь небольшой сравнительный пример использования описанных выше поисковых машин. В качестве запроса использовалась фраза:
«Best on the Web»
Подразумевалось, что следует найти документ, связанный с конкурсами «Лучший на Сети». Понятно, что уже в самом запросе есть определенная некорректность, но тем интереснее посмотреть, как с ней справились различные системы. Эта фраза задавалась в качестве набора слов, и при этом получались следующие результаты.
AltaVista - после нормализации лексики от запроса осталось только Best. Естественно, что при этом качество поиска было отвратительным. Однако, использование поиска по фразе как по единому целому, поставило требуемый документ на первое место в списке найденных.
Lycos - здесь отсеялись «on the» и документ был указан только в конце списка. Поиск по фразе улучшения результатов не дал.
InfoSeek - при расширенном поиске нужный документ был найден третьим в списке из десяти документов. Уточнение поиска привело только к миграции документа вглубь списка.
OpenText - документ занимает пятую строчку в списке из десяти документов. Как и в случае с InfoSeek уточнение запроса результатов не дало.
Yahoo - документ попал в список найденных и занял третье место (ошибка в запросе: вместо «on the» следовало указывать «of the»). Но здесь следует заметить, что основное место хранения этого документа база данных Yahoo, т.е. запрос точно совпадает с тематикой базы данных.
Следует заметить, что приведенный пример не стоит рассматривать как реальную оценку возможностей описанных выше систем. Это просто иллюстрация, которая поможет провести свой собственный выбор наиболее подходящего средства поиска.
В завершении хотелось бы обратить внимание читателей еще на один аспект выбора информационно-поисковой системы. Это профиль ее баз данных. Можно возразить, что все системы индексируют одно и тоже - массив документов Internet. Однако делают они это по-разному. Очень важен профиль системы, который задается разбиением документов по темам и словарем индексирования, а также способом его поддержания. Определенным ориентиром здесь могут служить виртуальные библиотеки. Но об этом в следующий раз.
3.6.7. Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. При этом различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню-ориентированный подход, либо командную строку. Меню-ориентированный подход позволяет ввести список терминов, обычно через пробел, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На нашей схеме (рисунок 3.41) есть так называемые сохраненные запросы пользователя. В большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один тип использования сохраненных запросов. В традиционных системах это называется расширением или уточнением запроса, в зависимости от того, что получаем в результате преобразования запроса: увеличение размера выборки или ее сокращение. При этом традиционная система хранит не запрос как таковой, а результат поиска, т.е. список идентификаторов документов, который объединяется/пересекается со списком полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в World Wide Web не практикуется. Вызвано это особенностью протоколов взаимодействия программы-клиента и сервера системы, которые не поддерживают сеансовый режим работы.
Как стало уже понятно из выше изложенного, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых системах выдается только список ссылок, а в таких системах как Lycos, AltaVista, Yahoo кроме ссылок дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, сообщается, сколько терминов запроса содержится в поисковом образе документа и в соответствии с этим ранжируется результат поиска. В Lycos выдается мера соответствия документа запросу, и ранжирование производится по этому параметру. Обычно пользователь имеет возможность уточнить запрос.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности[7]. Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Формальная - это та, что вычисляет система и на основании чего ранжируется выборка найденных документов. Реальная - это та, как сам пользователь оценивает найденные документы. Некоторые системы имеют для этого специальное поле[6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа. И выдача снова ранжируется. Так происходит до тех пор, пока результат не стабилизируется. Это означает, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS - это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы. Это значит, что одна ИПС, например, Lycos строит поисковый аппарат над поисковым аппаратом другой системы - WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, т.е. разбить их на поля, и хранить документы как один файл, индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения. В этом случае программа просмотра ресурсов Internet должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.